
音视频通信为什么要选择WebRTC?
共 6596字,需浏览 14分钟
·
2022-02-09 17:34
在网上经常看到有人说:“在线教育直播是用WebRTC做的”,“音视频会议是用WebRTC做的”......;“声网、腾讯、阿里......都使用的WebRTC”。但你有没有好奇,这些一线大厂为什么都要使用WebRTC呢?换句话说,WebRTC到底好在哪里呢?
这个问题,对于长期做音视频实时通信的老手来说是不言而喻的;但对于新手,则是急切想知道,而又很难得到答案的问题。那么本文我将采用对比法,向你详细阐述一下WebRTC到底好在哪里。
这次我们对比的指标包括:性能、易用性、可维护性、流行性、代码风格等多个方面。不过,要做这样的对比并非易事儿,首先要解决的难点是,目前市面上没有一款与WebRTC接近或有相似功能的开源库。这真成了无米之炊了!
好在这点困难并难不倒我们,既然没有与之可比较的开源库,那我们就自己“造”一个,用自研系统与WebRTC作比较。评估一下自研系统与基于WebRTC开发的音视频客户端,哪个成本更低、质量更好。通过这样的对比,相信能让你更加了解WebRTC,知道其到底有多优秀了。
自研系统直播客户端架构
首先我们先来了解一下自研直播客户端的架构,其如(图1)所示。这是一个最简单的音视频直播客户端架构,通过这张架构图,你大体可以知道自研系统都要实现那些模块了。

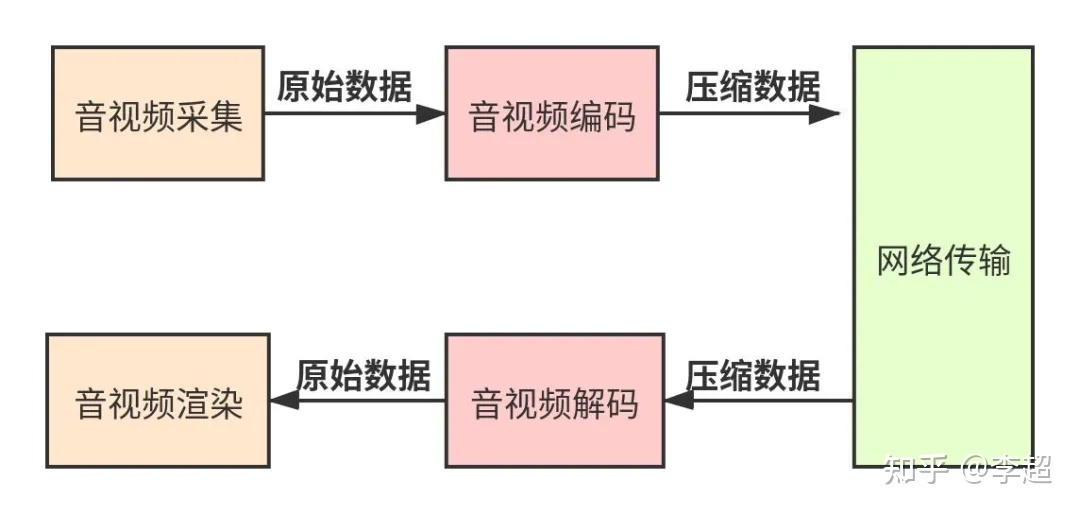
由(图1)你可以知道,一个最简单的直播客户端至少应该包括:音视频采集模块、音视频编码模块、网络传输模块、音视频解码模块和音视频渲染模块五大部分。
- 音视频采集模块:该模块调用系统的API,从麦克风和摄像读取设备采集到的音视频数据。音频采集的是PCM数据,视频采集的是YUV数据。
- 音视频编码模块:它负责将音视频设备上采集的原始数据(PCM、YUV)进行压缩编码。网
- 络传输模块:该模块负责将编码后的数据生成RTP包,并通过网络传输给对端;同时,接收对端的RTP数据。
- 音视频解码模块:它将网络模块接收到的压缩数据进行解码,还原回原始数据(PCM、YUV)。
- 音视频渲染渲染:拿到解码后的数据后,该模块将音频输出到扬声器,将视频渲染到显示器。
通过前面的介绍,相信你一定觉得,自研一个直播客户端好像也不是特别难的事儿。但实际上,上面介绍的音视频直播客户端架构是极简化的,甚至都不能称之为直播客户端架构,而只能称它为示意图。因为要将它变为真实的、可商用的架构还需要做不少的细化工作。
拆分音视频模块
接下来,咱们就对上面的直播客户端架构图进行逐步细化,细化的第一步就是拆分音视频模块。因为在实际开发中,音频与视频的处理是完全独立的,它们有各自的处理方式。如音频有独立的采集设备(声卡),独立的播放设备(扬声器)、访问音频设备的系统API等,另外,音频还有多种音频编解码器,如Opus、AAC、iLBC等;同样,视频也有自己独立的采集设备(摄像头)、渲染设备(显示器)、各种视频编码器,如H264、VP8等。细化后的直播客户端架构如(图2)所示。

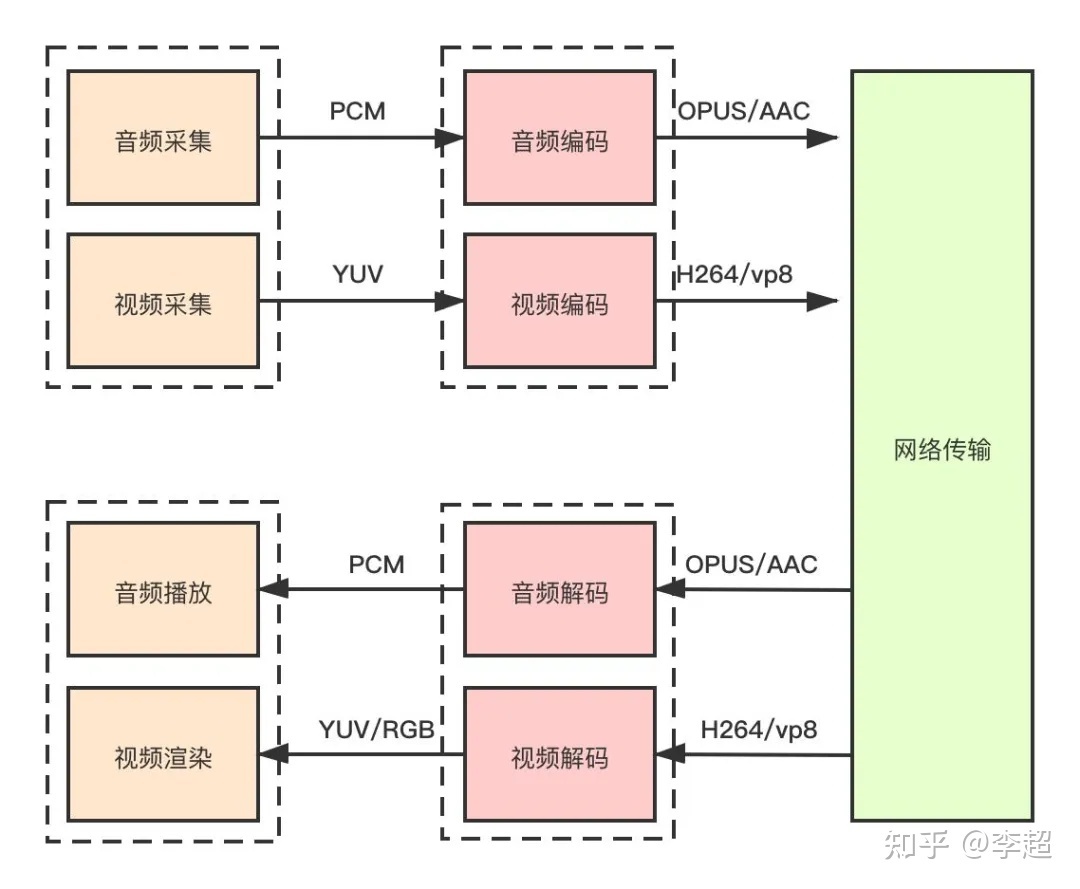
从(图2)中你可以看到,细化后的架构中,音频的采集模块与视频的采集模块是分开的,而音频编解码模块与视频的编解码模块也都是分开的。也就是说,音频是一条处理流程,视频是另外一条处理流程,它们之间并不相交。在音视频处理中,我们一般称每一路音频或每一路视频为一条轨。
除此之外,你还可以知道,自研音视频直播客户端要实现的模块远不止5个,至少应该包括:音频采集模块、视频采集模块、音频编码/音频解码模块、视频编码/视频解码模块、网络传输模块、音频播放模块以及视频渲染7个模块。
跨平台
实现音视频直播客户端除了要实现上面介绍的7个模块外,还要考虑跨平台的问题,只有在各个平台上都能实现音视频的互联互通,才能称得上是一个合格的音视频直播客户端。所以它至少应该实现Windows端、Mac端、Android端以及iOS四个终端,当然如果还能够支持Linux端和浏览器则是再好不过的了。
你要知道的是,如果不借助WebRTC,想在浏览器上实现音视频实时互通,难度是非常大的,这是自研系统的一大缺陷。除了与浏览器互通外,其它几个终端实现互通倒是相对较容易的事儿。
增加跨平台后,音视频直播客户端的架构要较之前复杂得多了,其如(图3)所示。从这张图中你可以看到,要实现跨平台,难度最大、首当其冲的,是访问硬件设备的模块,如音频采集模块、音频播放模块、视频采集模块以及视频播放模块等,它们在架构中的变化是最大的。

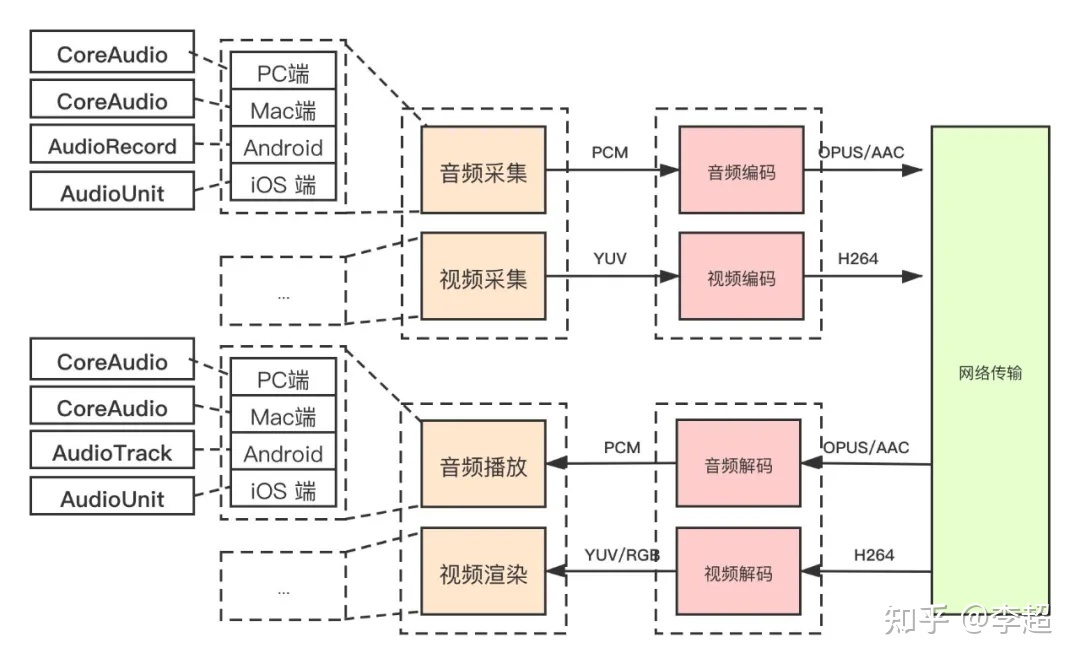
以音频采集为例,在不同的平台上,采集音频数据时使用的API是完全不一样的。PC端使用的是CoreAudio系列的API;巧合的是,Mac端用于采集音频的系统API也称为CoreAudio,不过具体的函数名肯定是不同的;在Android端,它为采集音视频提供的API称之为AudioRecord;iOS端,使用AudioUnit来采集音频数据;而Linux端,则使用PulseAudio采集音频数据。
总之,每个终端都有各自采集音视频数据的API。由于不同的系统,其API设计的架构也不同,所以在使用这些API时,调用的方式和使用的逻辑也千差万别。因此,在开发这部分模块时,其工作量是巨大的。
插件化管理
对于音视频直播客户端来说,我们不但希望它可以处理音频数据、视频数据,而且还希望它可以分享屏幕、播放多媒体文件、共享白板......此外,既使是处理音视频,我们也希望它可以支持多种编解码格式,如音频除了可以支持Opus、AAC外,还可以支持G.711/G.722、iLBC、speex等;视频除了可能支持H264外,还可以支持H265、VP8、VP9、AV1等,这样它才能应用的更广泛。
实际上,这些音视频编解码器都有各自的优缺点,也有各自适用的范围。比如G.711/G.722主要用于电话系统,音视频直播客户端要想与电话系统对接,就要支持这种编解码格式;Opus主要用于实时通话;AAC主要应用于音乐类的应用,如钢琴教学等。所以,我们希望直播客户端能够支持尽可能多的编解码器,这样的直播客户端才足够强大。
如何才能做到这一点呢?最好的设计方案就是实现插件化管理。当你需要支持某个功能时,直接编写一个插件放上去即可;当不需要的时候,可以随时将插件拿下来,这样的设计方案灵活、安全、可靠。

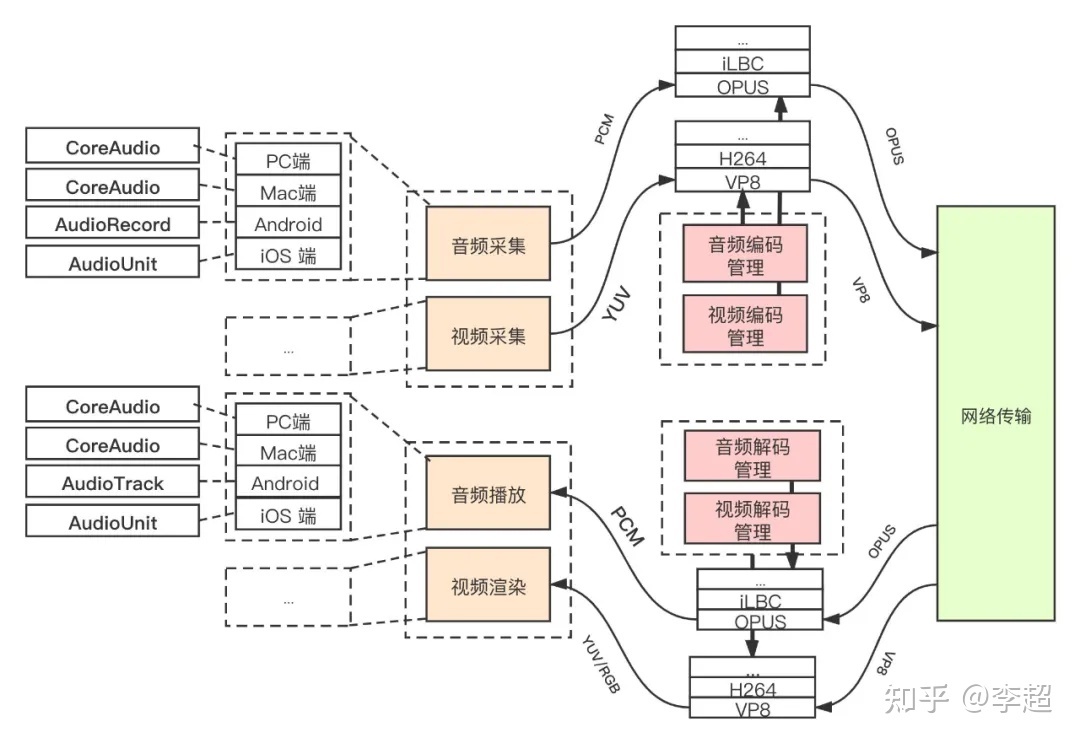
为了让直播客户端支持插件化管理,我对之前的架构图又做了调整。如(图4)所示。从中你可以看到,为了支持插件化管理,我将原来架构图中的音视频编解码器换成音视频编解码插件管理器,而各种音视频编解码器(Opus、AAC、iLBC......)都可以作为一个插件注册到其中。当你想使用某种类型的编码器时,可以通过参数进行控制,这样从音视频采集模块采集到的数据就会被送往对应的编码器进行编码;当接收接收到RTP格式的音视频数据时,又可以根据RTP头中的Payload Type来区分,将数据交由对应的解码器进行解码。经这样处理后,咱们的音视频直播客户端的功能就更强大了,应用范围也更广了。
这里我以音频编解码器为例,简要的向你介绍一下直播客户端增加插件管理前后的区别。客户端在增加插件管理之前,它只能使用一种音频编解码器,如Opus。因此,在一场直播活动中,所有参与直播的终端都只能使用同一种音频的编解码器(Opus)。这样看起来貌似也不会产生什么问题,是吧?不过,假如此时,我们想将一路电话语音接入到这场直播中(电话语音使用的编解码器为G.711/G.722),它就无能为力了;而有了插件管理情况就不同了,各终端可以根据接收到的音频数据类型调用不同的音频解码器进行解码,从而实现不同编解码器在同一场直播中互通的场景,这就是插件化管理给我们带来的好处。
服务质量
除了上面我介绍的几点外,要实现一个功能强大的、性能优越的、应用广泛的音视频直播客户端还有很多的工作要做,尤其将服务质量是大家特别关心的。如果直播客户端不能提供好的服务质量,那它就失去了商业价值。
实时通信中的服务质量指的是什么呢?它主要包括三个方面,一是通信时延小;二是同等网路条件下视频更清晰、流畅;三是同等网络条件下语音失真小。如何才能保障通信时延小、视频清晰、语音不失真呢?
这里的关键是网络。如果直播客户端可以保障用户有一条非常好的网络线路,在这条线路上传输的时延最小、不丢包、不乱序,那我们的音视频服务质量自然就上去了,对吧!
但我们都知道,网络的问题是最难解决的。出现丢包、抖动、乱序更是家常便饭。有的同学可以会说 TCP 不是已经解决了丢包、乱序这些问题吗?确实是,但它是以牺牲时延为代价的。当我们的网络比较优质时,TCP/UDP都可以用于实时传输,但大多数情况下,我们首选UDP,原因是在弱网环境下使用TCP会产生极大的延时。
要想弄清楚TCP为什么在弱网环境下会产生极大的延时,就要介绍一点TCP的机制的了。TCP为了保证不丢包,不乱序,采用了发送、确认、丢包、重传的机制。正常情况下,数据从一端传输到另一端是没有任何问题的,但当出现丢包时就会有较大的麻烦。如图所示。

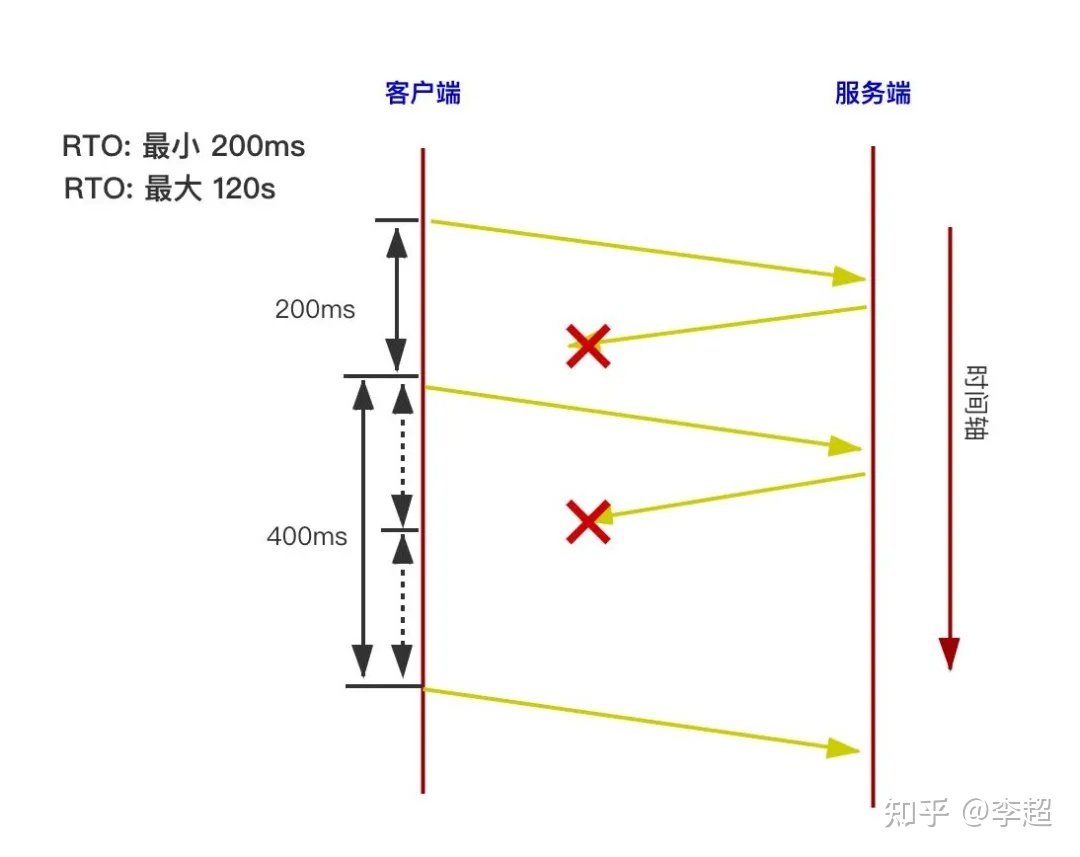
图中显示了多次丢包时的延迟情况:从客户端向服务端发送数据包,服务端需要返回ACK消息进行确认; 客户端收到确认消息后, 才能继续发送后面的数据(有滑窗时也是类似的)。每次客户端发完数据后,都会启动一个定时器,定时器的最短超时时间是200ms。如果因某种原因,在200毫秒客户端没有收到返回的ACK包,客户端会重发上一个包。由于TCP有退避机制,以防止频繁发送丢失的包,因此会将重发包的超时时间延长到400ms。如果重发包依然没有收到确认消息,则下一次重发的超时时间会延长到800ms。我们可以看到,连续几次丢包后,就会产生非常大的延迟,这就是TCP在弱网环境下不能使用的根本原因。
根据实时通信指标,超过 500ms 就不能称为实时通信了,因此在弱网情况下,绝对不能使用TCP协议。实时通信的指标如(图6)所示。


通过(图6)中的表格可以看到,如果端到端延迟在200ms以内,说明整个通话是优质的,通话效果就像大家在同一个房间里聊天一样;300ms以内,大多数人很满意,400ms以内,有小部分人可以感觉到延迟,但互动基本不受影响;500ms以上时,延迟会明显影响互动,大部分人都不满意。所以最关键的一点是500ms,只有延迟低于500ms,才可以说是合格的实时互动系统。
通过上面的描述我们可以知道,如果我们想在自己的直播客户端中实现好的服务质量,任务还是非常艰巨的。当然,除了上面要实现的功能外,还有其它很多需要处理的细节。
其它
音视频不同步问题。音视频数据经网络传输后,由于网络抖动和延迟等问题,很可能造成音视频不同步。因此,你在实现音视频直播客户端时,需要增加音视频同步模块以保障音视频的同步。
回音问题。回音问题指的是,自己与其它人进行实时互动时,可以听到自己的回声。在实时音视频通信中,不光有回音问题,还有噪音、声音过小等问题,我们将它们统称为3A问题。这些问题都是非常棘手的。目前开源的项目中,只有WebRTC和Speex有开源的回音消除算法,而且WebRTC的回音消除算法还是目前世界上最顶级的。
音视频的实时性问题。要进行实时通信,网络质量尤为关键。但你应该也清楚,网络的物理层是很难保障网络服务质量的,必须在软件层加以控制才行。虽然大家常用的TCP协议有一套完整的保障网络质量的方案,但它在实时性方面表现不佳。换句话说,TCP是以牺牲实时性来保障网络服务质量的,而实时性又是音视频实时通信的命脉,这就导致TCP协议不能作为音视频实时传输的最佳选择了。因此,为了保证实时性,一般情况下实时直播应该首选UDP协议。但这样一来,我们就必须自己编写网络控制算法以保证网络质量了。
此外,还有网络拥塞、丢包、延时、抖动、混音......不胜枚举。可以说,要实现一个实时的音视频直播客户端有许许多多的问题要解决,这里我就不一一列举了。总之,通过上面的描述,我想你已经清楚要自己研发一套音视频直播客户端到底有多难了。
WebRTC客户端架构
实际上,在直播客户端架构一节我讲的所有功能,WebRTC都已经实现了。下面让我们看一下WebRTC架构图吧,如(图)所示。

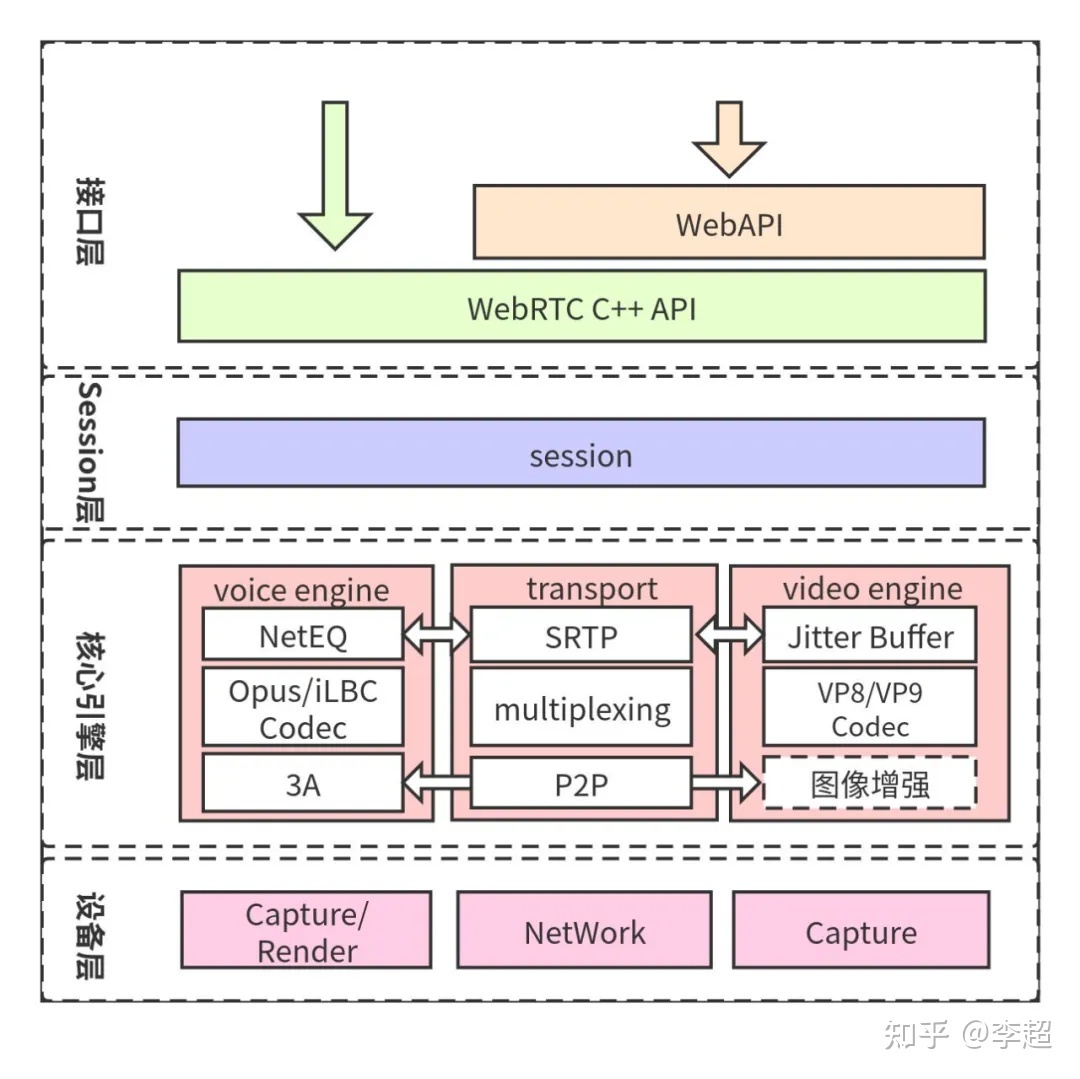
从WebRTC架构图中你可以了解到,它大体上可以分成四层:即接口层、Session层、核心引擎层和设备层。下面我就向你简要的介绍一下每一层的作用。
接口层包括两部分,一是Web层接口;二是Native层接口。也就是说,你既可以使用浏览器开发音视频直播客户端,也可以使用Native(C++、Android、OC等)开发音视频直播客户端。
Session层的主要作用是控制业务逻辑,如媒体协商、收集Candidate等,这些操作都是在Session层处理的;
核心引擎层包括的内容就比较多了。从大的方面说,它包括音频引擎、视频引擎和网络传输层。音频引擎层包括NetEQ、音频编解码器(如OPUS、iLBC)、3A等。视频引擎包括JitterBuffer、视频编解码器(VP8/VP9/H264)等。网络传输层包括SRTP、网络I/O多路复用、P2P等。以上这些内容中,本书重点介绍了网络相关的内容,它们分布在第三章音视频实时通信的本质、第六章WebRTC中的ICE实现、第九章RTP/RTCP协议详解、第十章WebRTC拥塞控制等几个章节中,由于篇幅的原因,其它内容我会陆续发布在我的个人主站https://avdancedu.com上。
设备层主要与硬件打交道,它涉及的内容包括:在各终端设备上进行音频的采集与播放、视频的采集以及网络层等。这部分内容会在本书的最后一章 \textbf{WebRTC源码分析}中做详细介绍。
从上面的描述中你可以看到,在WebRTC架构的四层中,最复杂、最核心的是第三层,即引擎层,因此,这里我再对引擎层内部的关系做下简要介绍。引擎层包括三部分内容,分别是:音频引擎、视频引擎以及网络传输。其中音视引擎和视频引擎是相对比较独立的。不过,它们都需要与网络传输层(transport)打交道。也就是说,它们都需要将自己产生的数据通过网络传输层发送出去;同时,也需要通过网络传输层接收其它端发过来的数据。此外,音频引擎与视频引擎由于要进行音视频同步的原因,所以它们之间也存在着关联关系。

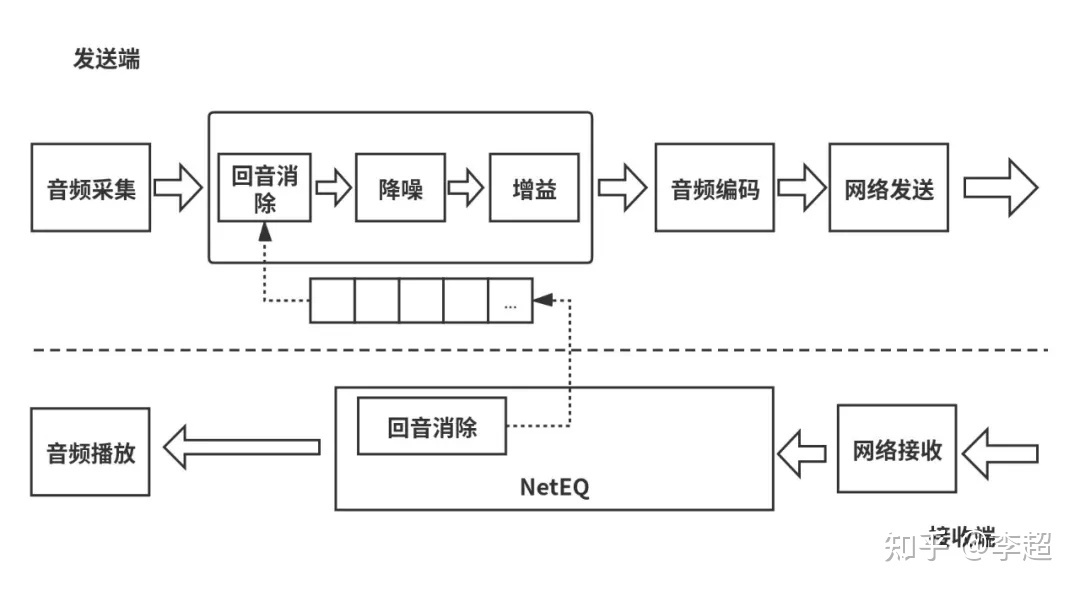
最后,我们再次以音频为例(如图8所示),来看一下WebRTC中的数据流是如何流转的吧。当WebRTC作为发送端时,它通过音频设备采集到音频数据后,先要进行3A处理,处理后的数据交由音频编码器编码,编码后由网络传输层将数据发送出去;另一方面,当网络传输层收到数据后,它要判断数据的类型是什么,如果是音频,它会将数据交给音频引擎模块处理,数据首先被放入到NetEQ模块做平滑处理及音频补偿处理,之后进行音频解码,最终将解码后的数据通过扬声器播放出来。视频的处理流程与音频的处理流程是类似的,这里我就不再赘述了。
小结
通过上面对自研音视频客户端架构的描述以及WebRTC客户端架构的描述,相信在你心中,对WebRTC的优势已经非常清楚了。下面我再从性能、跨平台、音视频服务质量、稳定性等几个方面对两者做一下总结。如(图9)所示:


(图9)告诉我们,WebRTC在实时音视频直播方面的优势是不言而喻的,又有Google的强大支持,这就是为什么大家都选择WebRTC的真正原因了。
我的视频课
WebRTC实时互动直播技术入门与实战 5G时代必备技能 (戳链接直达课程)
百万级高并发WebRTC流媒体服务器设计与开发 (戳链接直达课程)
编程必备基础-音视频小白系统入门课 (戳链接直达课程)
OpenCV入门到进阶:实战三大典型项目 (戳链接直达课程)
经典再升级-FFmpeg音视频核心技术全面精讲+实战 (戳链接直达课程)
我的新书
★本书深入浅出地对WebRTC技术进行了系统讲解,既有原理又有实战,从WebRTC是如何实现实时音视频通信的,到如何应用WebRTC库实现音视频通信,再到WebRTC源码的剖析,逐步展开讲解。此外,对WebRTC的传输系统进行了重点分析,相信读者通过本书可以一窥WebRTC传输的奥秘。