
Flume一文深入浅出
本文来源:http://r6d.cn/bdvqa
Flume简介
Flume概述:
Flume是开源日志系统。是一个分布式、可靠性和高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据;同时,FLume提供对数据进行简单处理,并写到各种数据接收方(可定制)的能力。
Flume是什么?
Flume是流式日志采集工具,FLume提供对数据进行简单处理并且写到各种数据接收方(可定制)的能力,Flume提供从本地文件(spooling directory source)、实时日志(taildir、exec)、REST消息、Thift、Avro、Syslog、Kafka等数据源上收集数据的能力。
Flume能干什么?
提供从固定目录下采集日志信息到目的地(HDFS,HBase,Kafka)能力。 提供实时采集日志信息(taidir)到目的地的能力。 FLume支持级联(多个Flume对接起来),合并数据的能力。 Flume支持按照用户定制采集数据的能力。
Flume在FusionInsight中的位置:
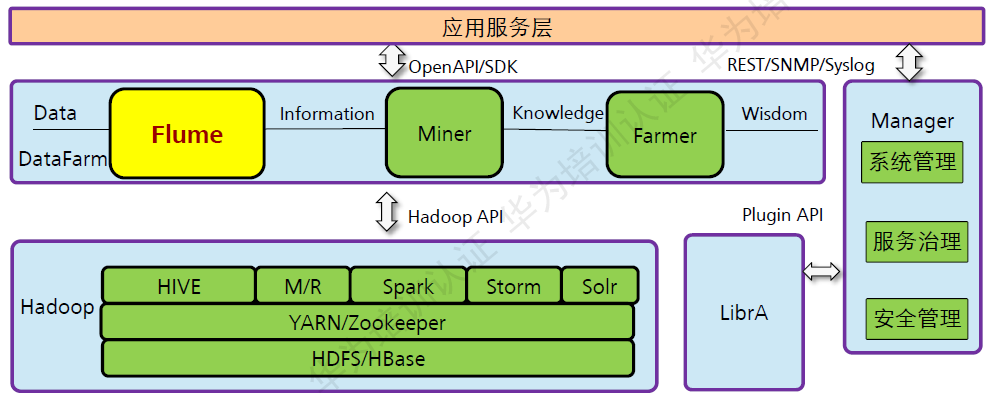
图:Flume在FusionInsight中的位置
Flume是收集、聚合事件流数据的分布式框架。
Flume系统架构
Flume基础架构:
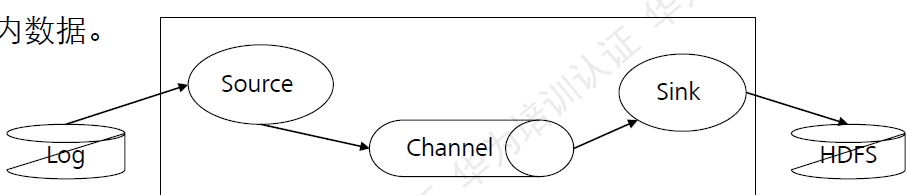
图:Flume基础架构图
Flume基础架构:Flume可以单节点直接采集数据,主要应用于集群内数据。
Flume多agent架构:

图:Flume多agent架构
Flume多agent架构:Flume可以将多个节点连接起来,将最初的数据源经过收集,存储到最终的存储系统中。主要应用于集群外的数据导入到集群内。
Flume架构:
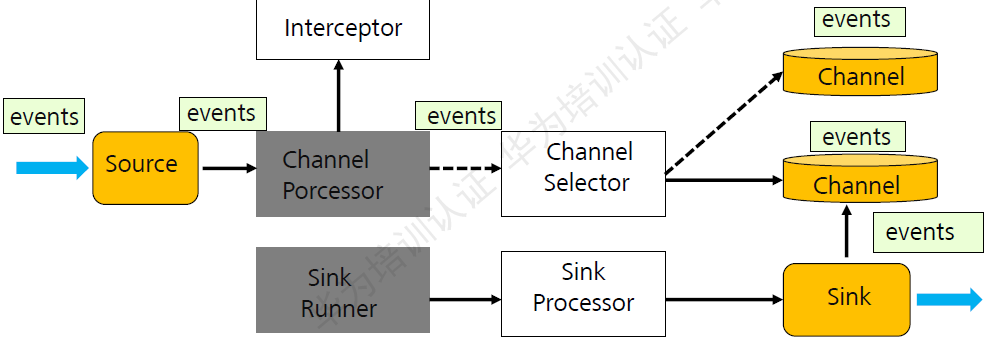
图:Flume架构图
各组件具体介绍如下:
events:Flume当中对数据的一种封装。是一个数据单元。flume传输数据最基本的单元。
Interceptor:拦截器,主要作用是将采集到的数据根据用户的配置进行过滤和修饰。
Channel Selector:通道选择器,主要作用是根据用户配置将数据放到不同的Channel当中。
Channel:主要作用是临时的缓存数据。
Sink Runner:sink的运行器,主要是通过它来驱动Sink Processor,Sink Processor驱动Sink来从Channel当中获取数据。
Sink Processor:主要策略有,负载均衡,故障转移以及直通。
Sink:主要作用是从Channel当中取出数据,并将数据放到不同的目的地。
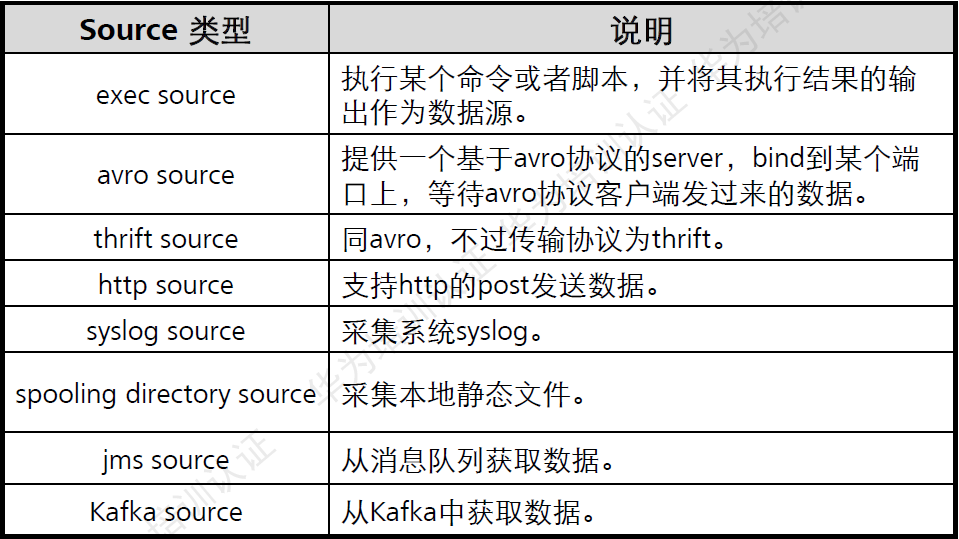
基本概念- Source:
Source负责接收events或通过特殊机制产生events,并将events批量放到一个或多个Channels。有驱动和轮询2中类型的Source。
驱动型Source:是外部主动发送数据给Flume,驱动Flume接收数据。 轮询source:是FLume周期性主动去获取数据。
Source必须至少和一个channel关联。
Source的类型如下:
基本概念 - Channel:
Channel位于Source和Sink之间,Channel的作用类似队列,用于临时缓存进来的events,当Sink成功地将events发送到下一跳的channel或最终目的,events从Channel移除。
不同的Channel提供的持久化水平也是不一样的:
Memory Channel:不会持久化。消息存放在内存中,提供高吞吐,但提供可靠性;可能丢失数据。 File Channel:对数据持久化;基于WAL(预写式日志Write-Ahaad Log)实现。但是配置较为麻烦,需要配置数据目录和checkpoint目录;不同的file channel均需要配置一个checkpoint目录。 JDBC Channel:基于嵌入式Database实现。内置derby数据库,对event进行了持久化,提供高可靠性;可以取代同样持久特性的file channel。
Channels支持事物,提供较弱的顺序保证,可以连接任何数量的Source和Sink。
基本概念 - Sink:
Sink负责将events传输到下一跳或最终目的,成功完成后将events从channel移除。
必须作用于一个确切的channel。
Sink类型:

Flume关键特性介绍
Flume支持采集日志文件:
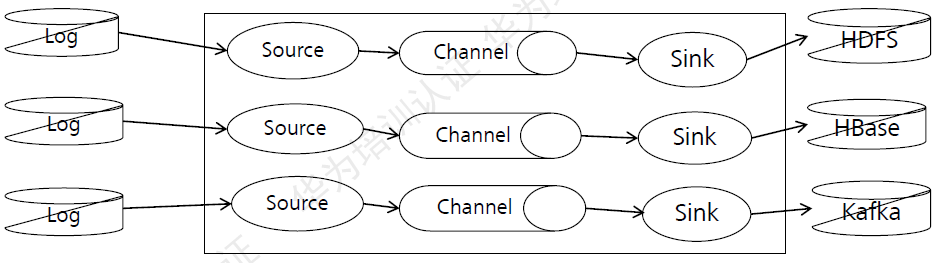
图:Flume采集日志文件
Flume支持将集群外的日志文件采集并归档到HDFS、HBase、Kafka上,供上层应用对数据分析、清洗数据使用。
Flume支持多级级联和多路复制:
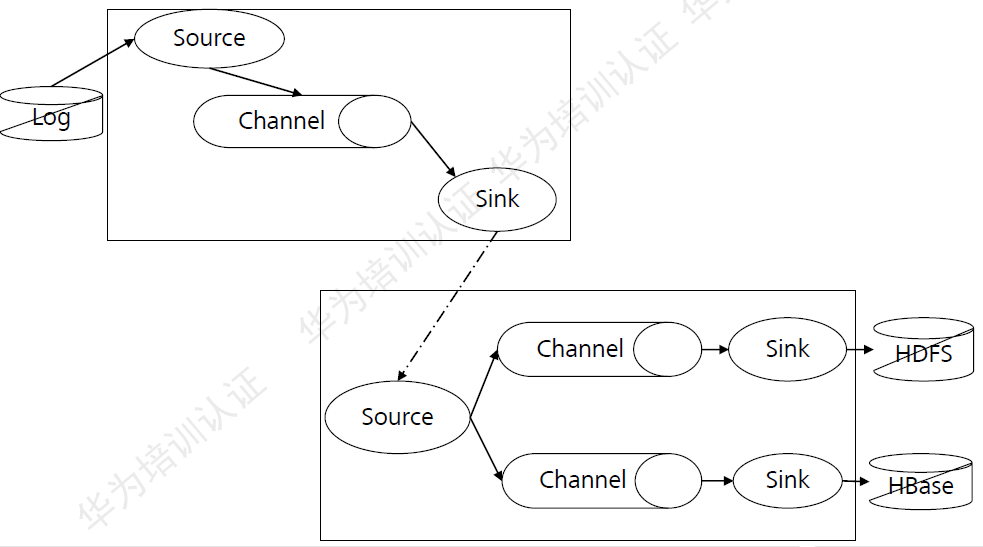
图:Flume级联
Flume支持将多个Flume级联起来,同时级联节点内部支持数据复制。
这个场景主要应用于:收集FusionInsight集群外上的节点上的日志,并通过多个Flume节点,最终汇聚到集群当中。
Flume级联消息压缩、加密:
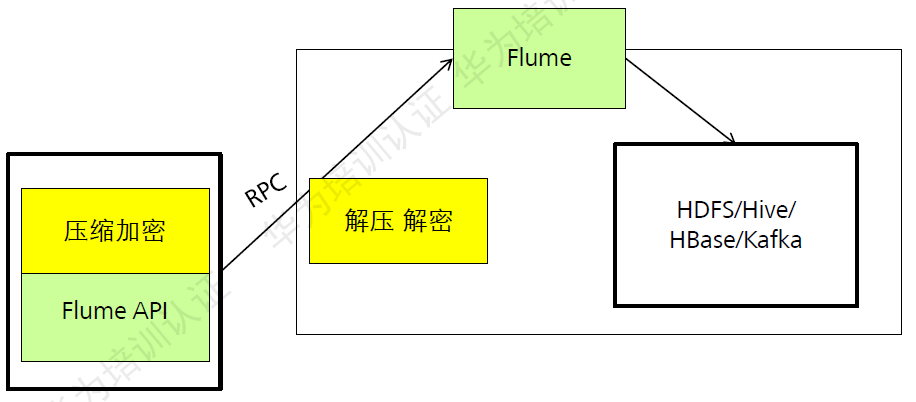
图:Flume级联消息压缩、加密
Flume级联节点之间的数据传输支持压缩和加密,提升数据传输效率和安全性。
在同一个Flume内部进行传输时,不需要加密,为进程内部的数据交换。
Flume数据监控:
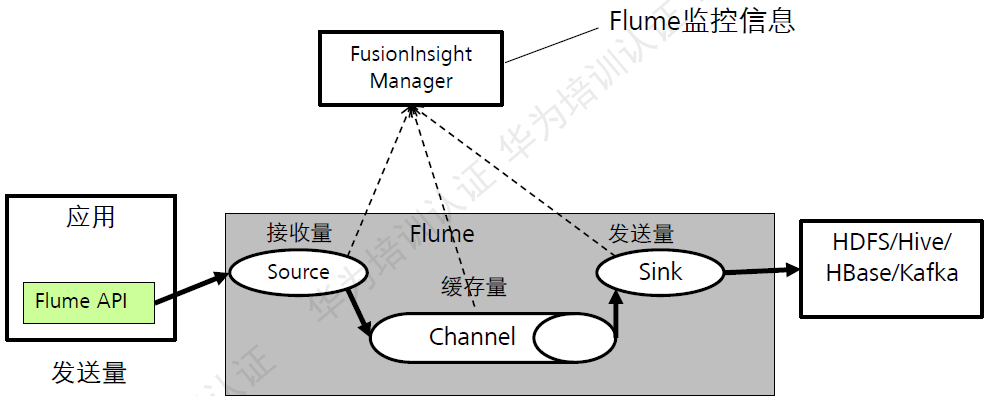
图:Flume数据监控
Source接收的数据量,Channel缓存的数据量,Sink写入的数据量,这些都可以通过Manager图形化界面呈现出来。
Flume传输可靠性:
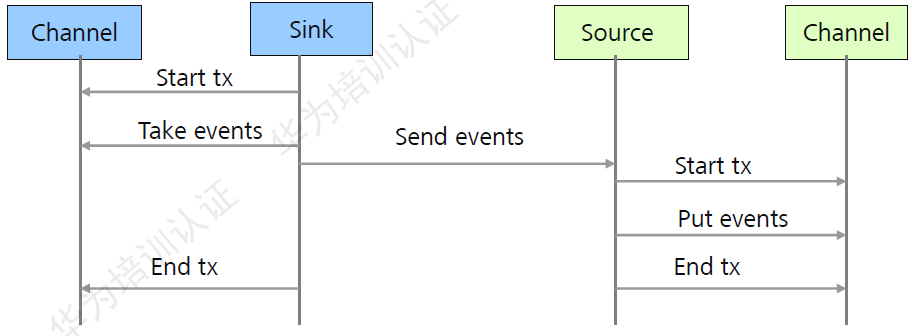
图:Flume传输可靠性原理
Flume在传输数据过程中,采用事物管理方式,保证数据传输过程中数据不会丢失,增强了数据传输的可靠性,同时缓存在channel中的数据如果采用了file channel,进程或者节点重启数据不会丢失。
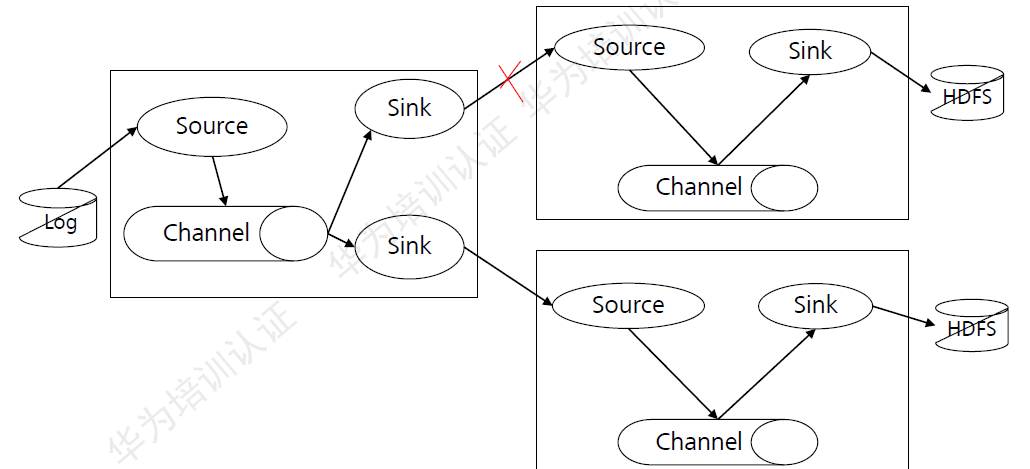
图:Flume传输过程中出错情况
Flume在传输数据过程中,如果下一跳的Flume节点故障或者数据接收异常时,可以自动切换到另外一路上继续传输。
Flume传输过程中数据过滤:
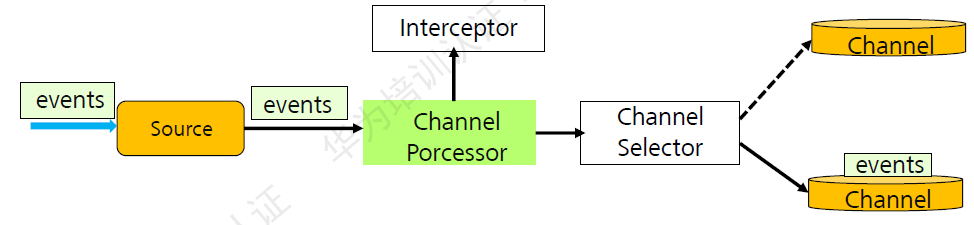
图:过滤原理
Flume在传输数据过程中,可以见到的对数据简单过滤、清洗,可以去掉不关心的数据,同时如果需要对复杂的数据过滤,需要用户根据自己的数据特殊性,开发过滤插件,Flume支持第三方过滤插件调用