
综述:如何给模型加入先验知识

来源:DASOU 本文约4300字,建议阅读10+分钟
本文为你总结五个给模型加入先验信息的方法。
模型加入先验知识的必要性

就是它可能出现在任何地方,但就是不可能在天上,因为它是世界上唯一一种不会飞的鹦鹉(不是唯一一种不会飞的鸟)。
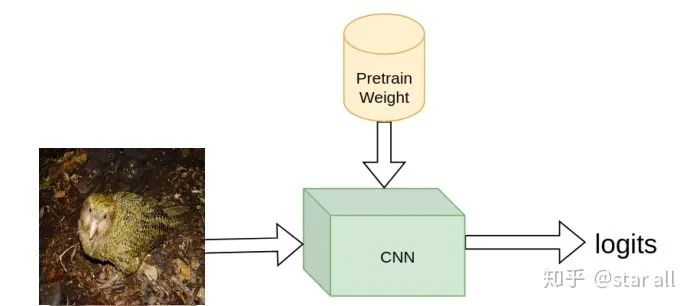
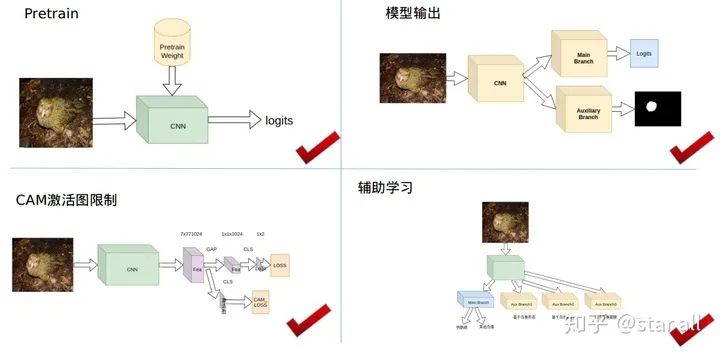
基于pretrain模型给模型加入先验
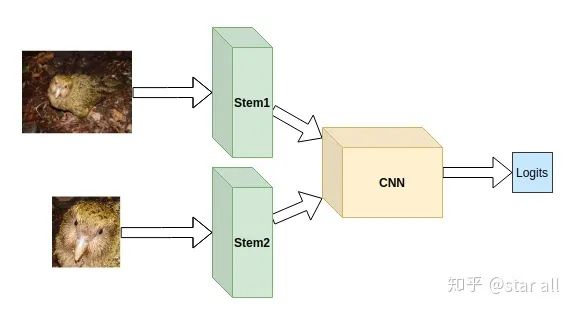
基于输入给模型加入先验
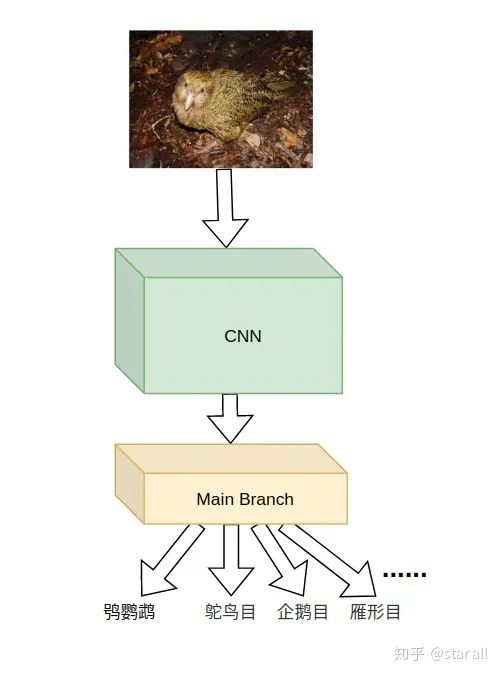
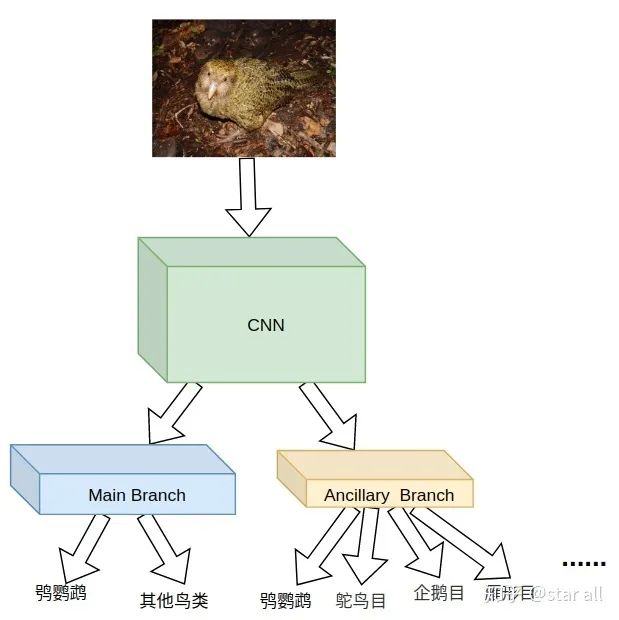
你觉得鸮鹦鹉的头是一个区别其他它和鸟类的重要部分,也就是说相比于身体,它的头部更能区分它和其他鸟类。
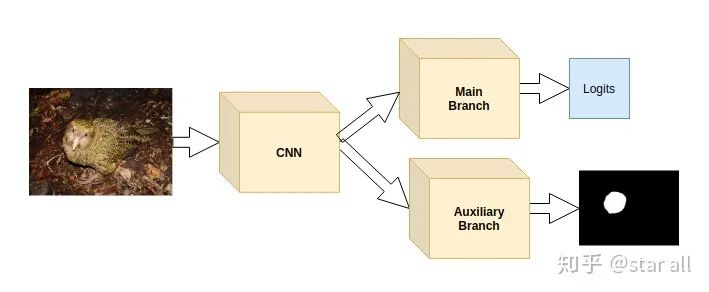
基于模型重现给模型加入先验
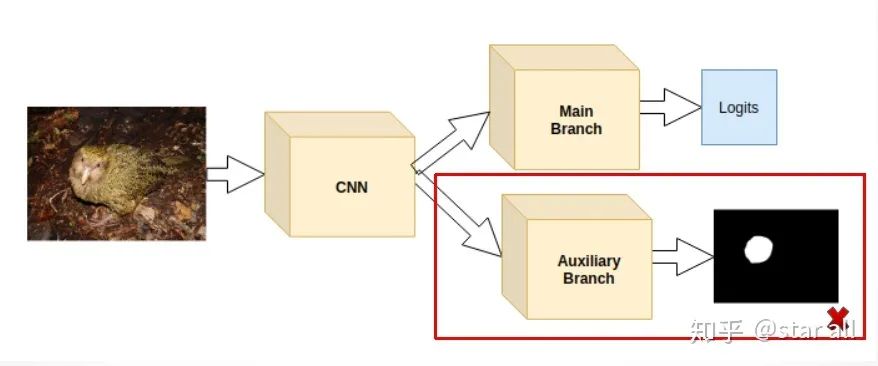
基于CAM图激活限制给模型加入先验
那就是鸮鹦鹉是世界上唯一一种不会飞的鹦鹉。

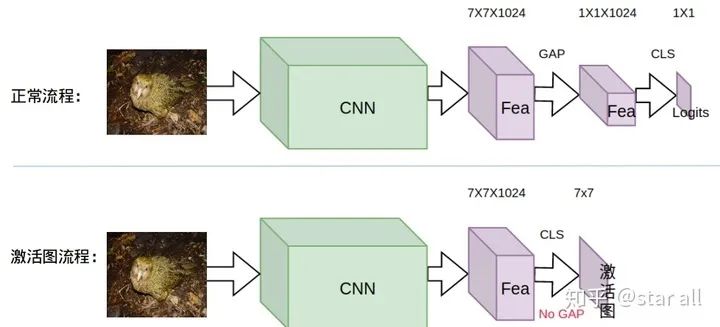




Loss_cam = -sum(where(bird_mask_outside<0))具体的网络的framework可以如下所示:
基于辅助学习给模型加入先验知识

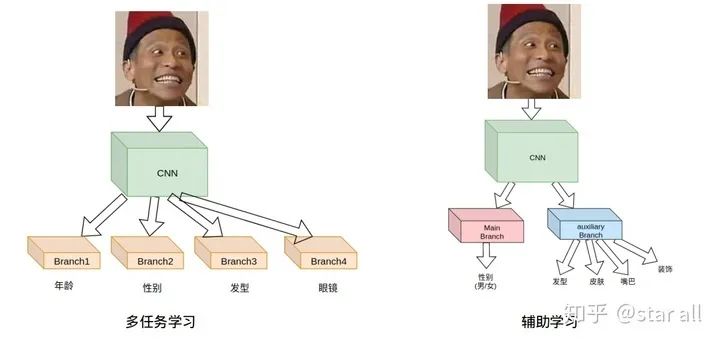
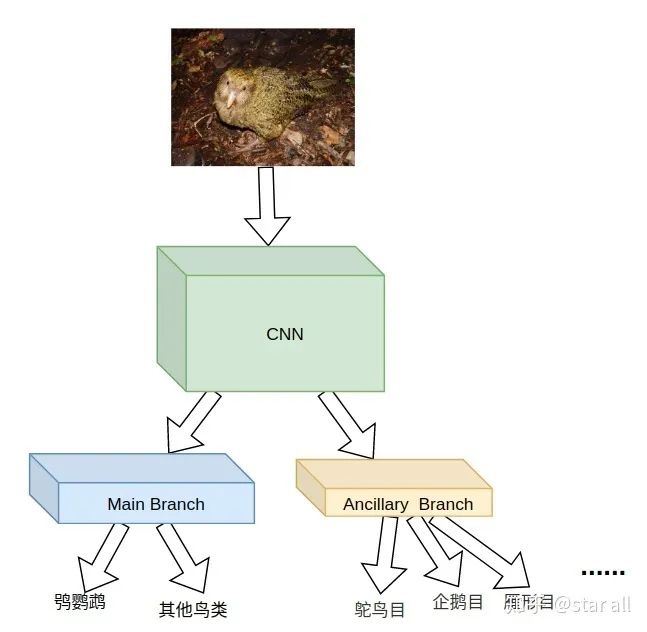
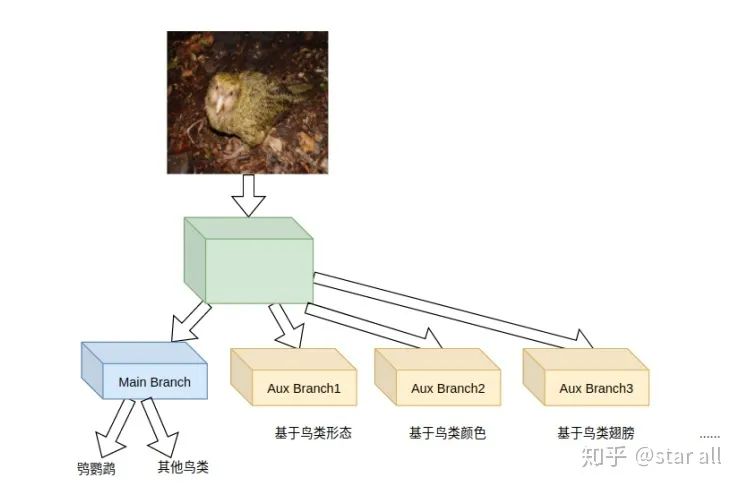
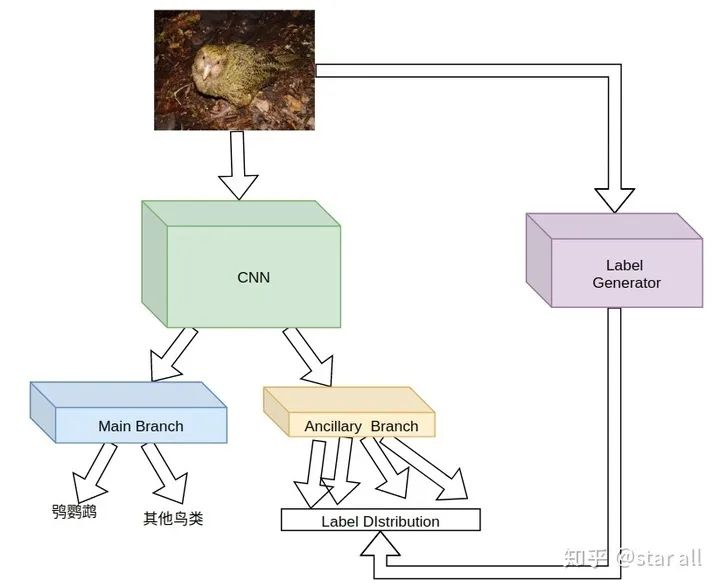
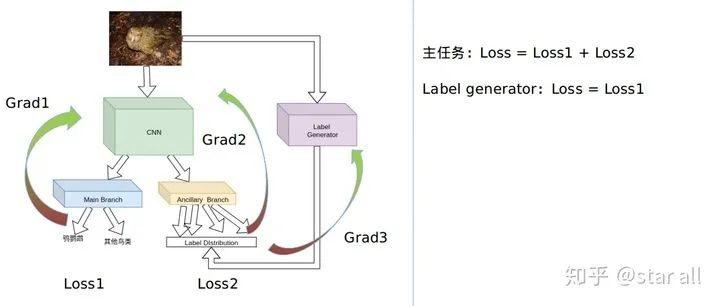
假设 primary 和 auxiliary task 是在同一个 domain,那么 primary task 的 performance 会提高当且仅当 auxiliary task 的 complexity 高于 primary task。 假设 primary 和 auxiliary task 是在同一个 domain,那么 primary task 的最终 performance 只依赖于 complexity 最高的 auxiliary task。
结语
评论