
给模型加入先验知识
点击上方“机器学习与生成对抗网络”,关注星标 获取有趣、好玩的前沿干货!
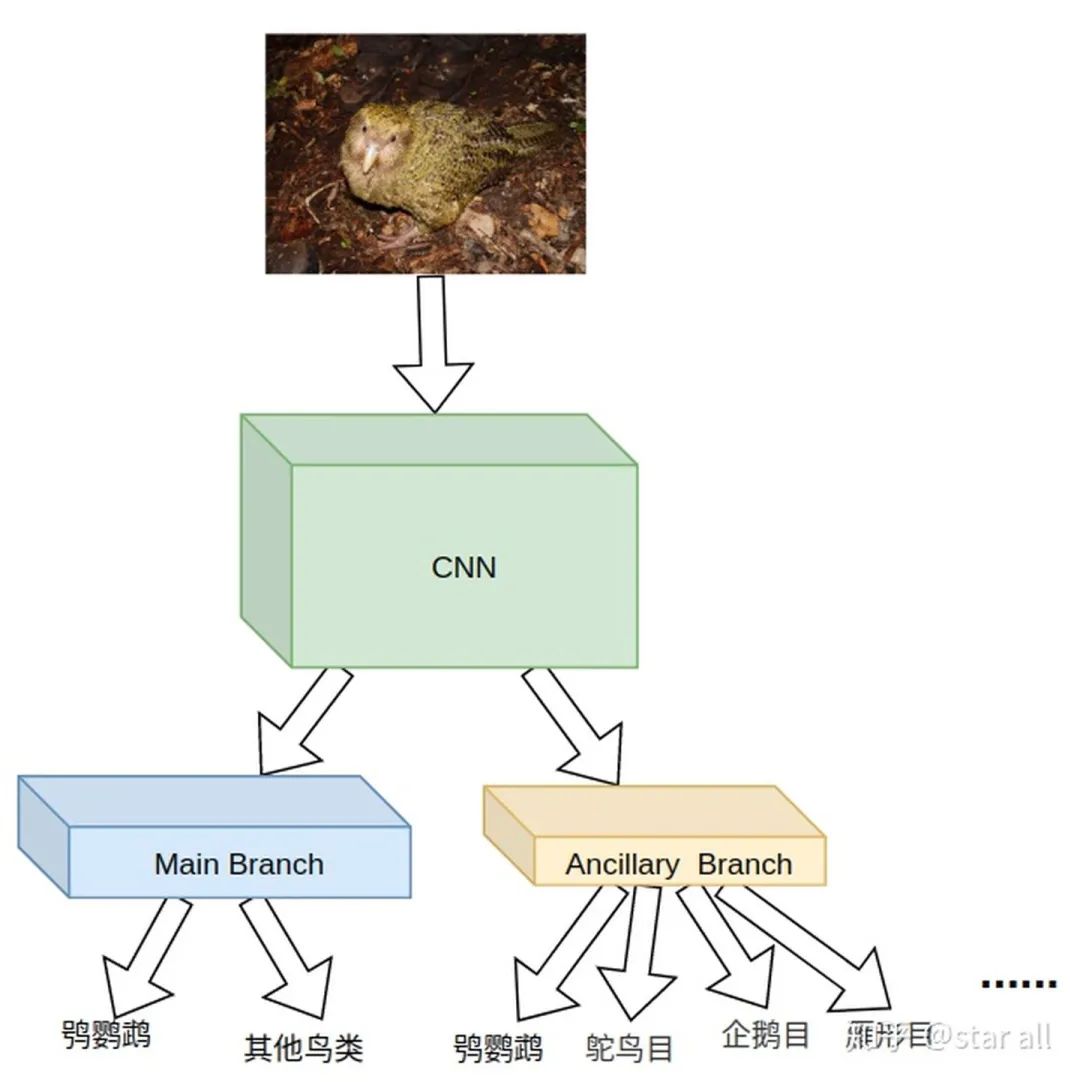
01

鸮(xiāo)鹦鹉
就是它可能出现在任何地方,但就是不可能在天上,因为它是世界上唯一一种不会飞的鹦鹉(不是唯一一种不会飞的鸟)。
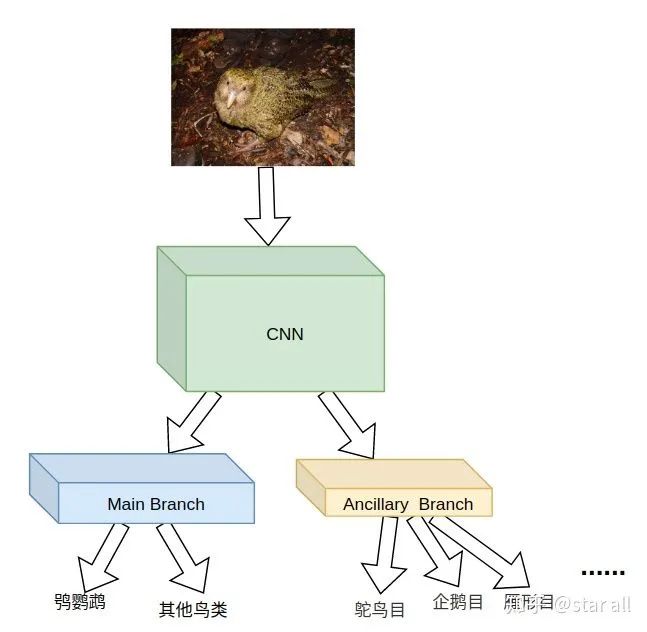
02
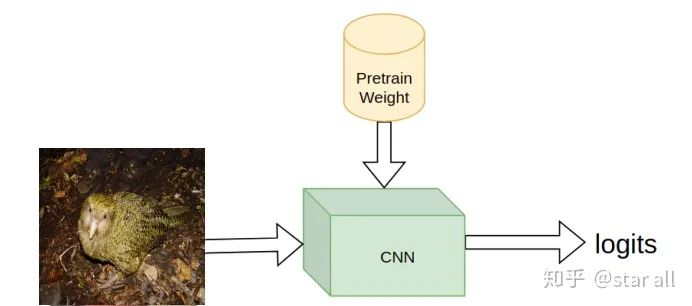
03
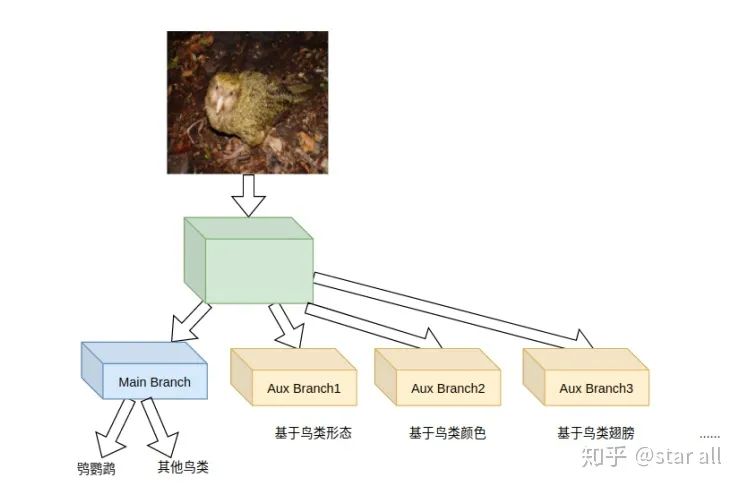
你觉得鸮鹦鹉的头是一个区别其他它和鸟类的重要部分,也就是说相比于身体,它的头部更能区分它和其他鸟类。
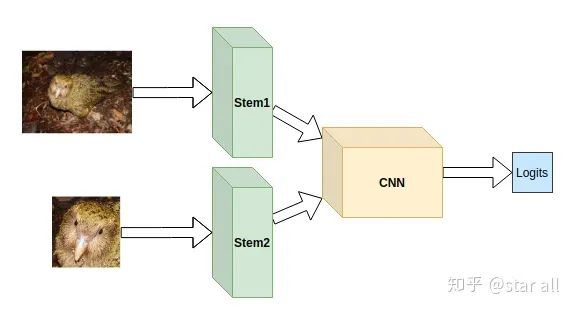
04
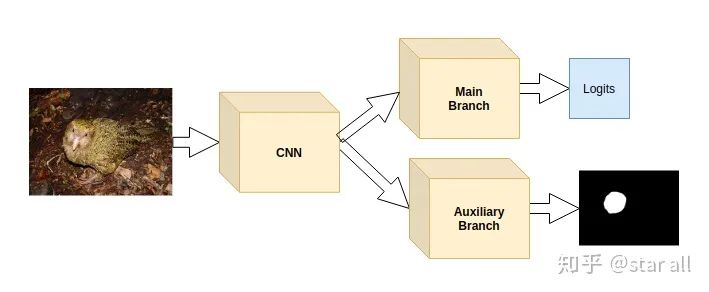
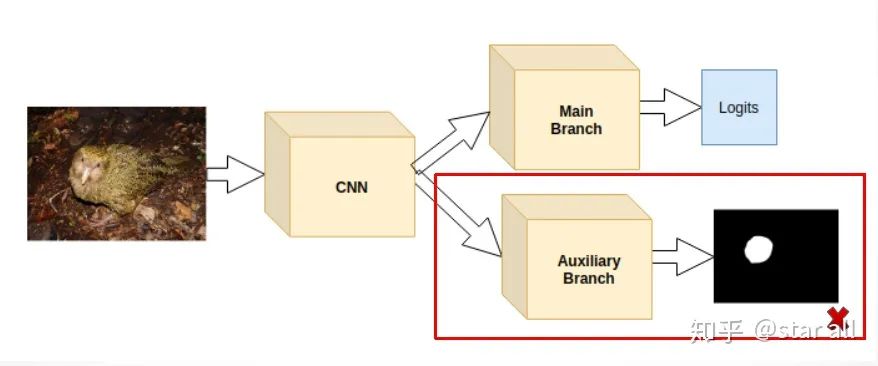
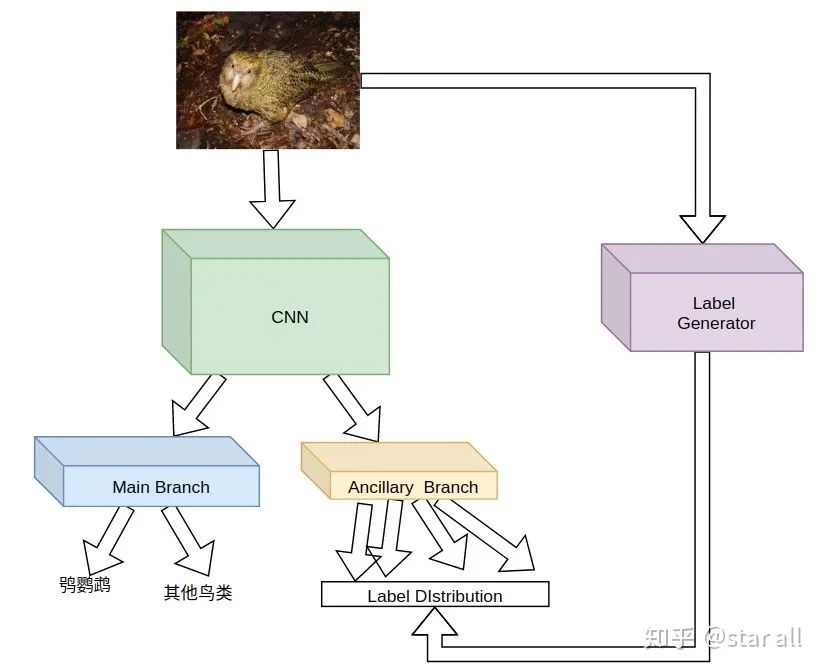
05
那就是鸮鹦鹉是世界上唯一一种不会飞的鹦鹉。

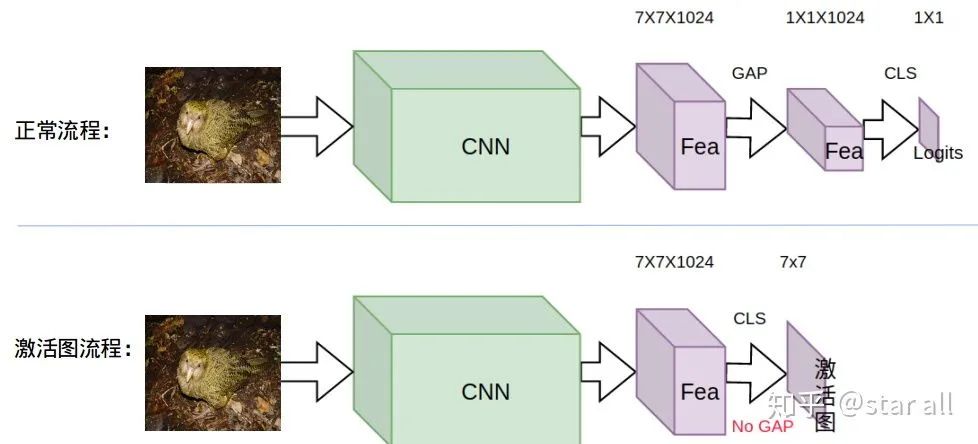




Loss_cam = -sum(where(bird_mask_outside<0))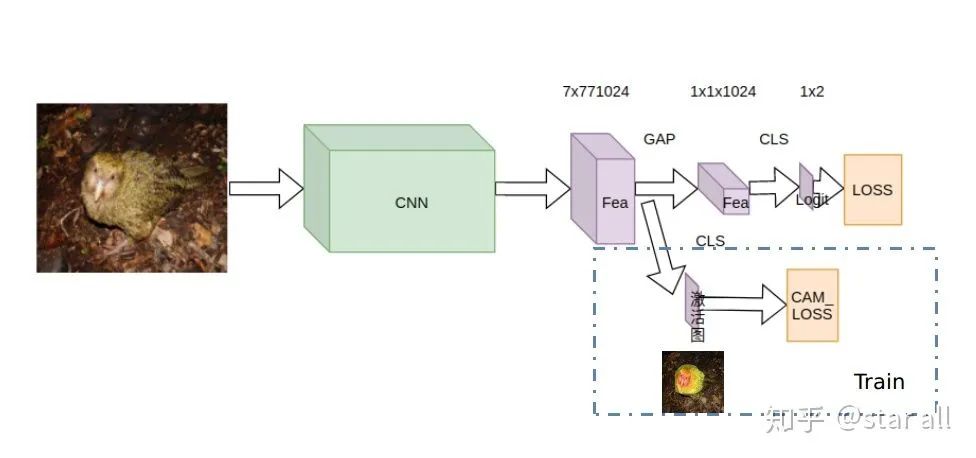
06

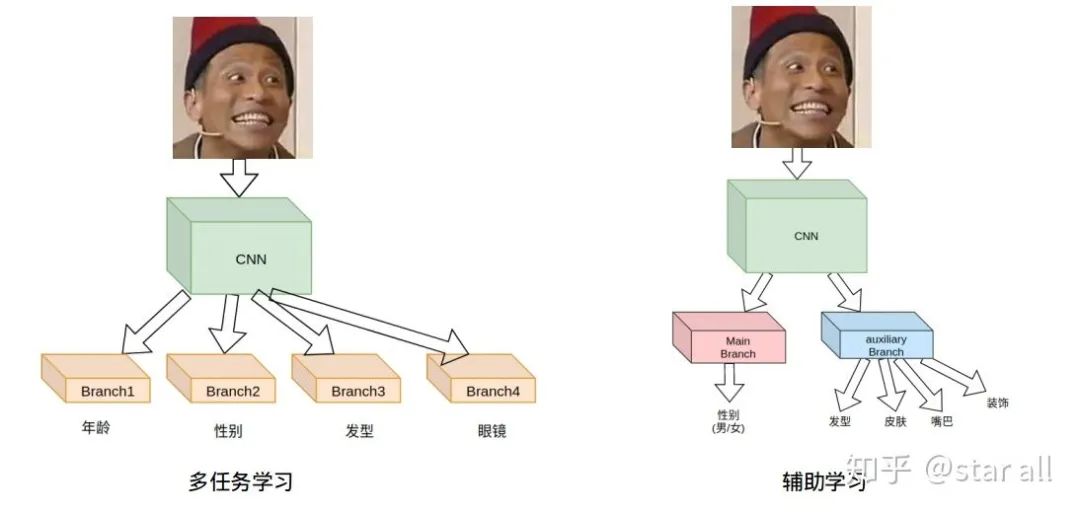
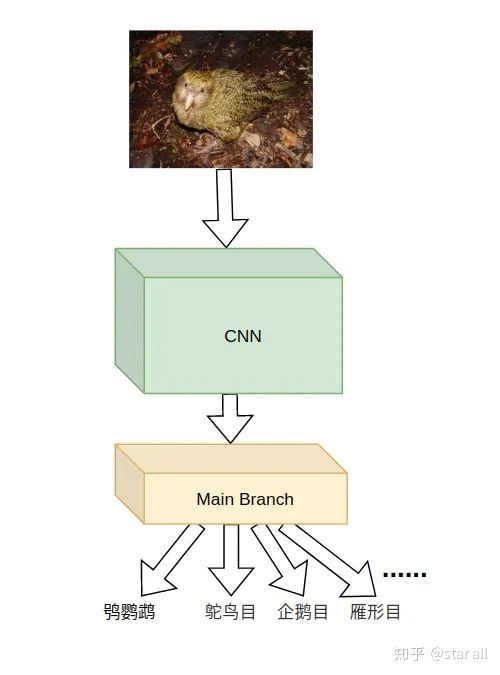
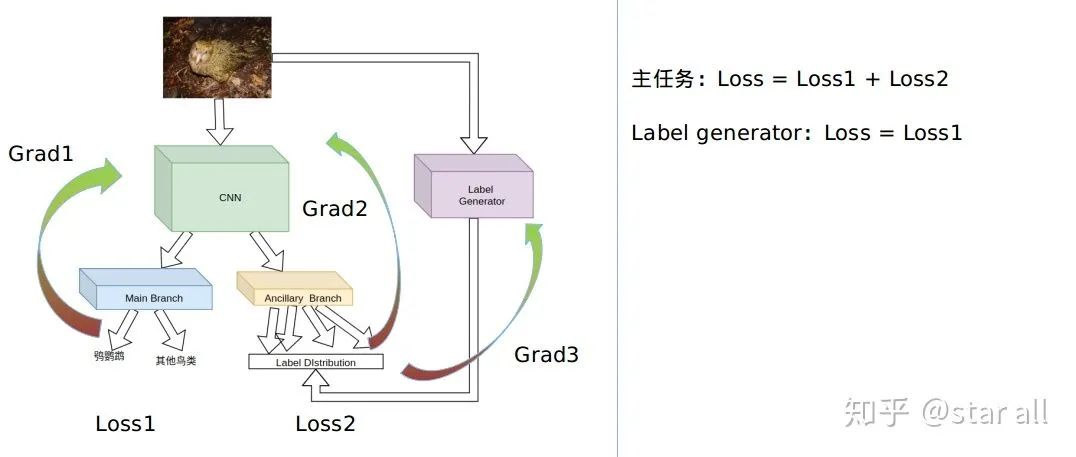
07
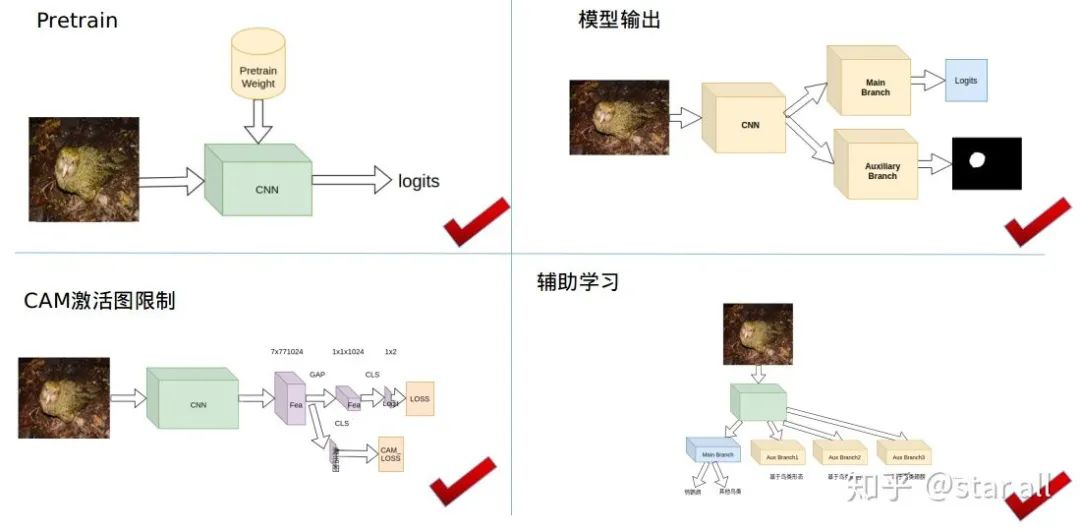
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
评论