
吴恩达:2020 年,这些 AI 大事件让我无法忘怀...


凡是过往,皆为序章。
亲爱的朋友们,在过去的十年中,每年我都会飞往新加坡或香港,与我的母亲一起庆祝她的12月22日的生日。今年,我们则是通过Zoom线上庆生。尽管距离遥远,但我仍然感到很高兴,我的家人们可以从美国,新加坡,香港,香港和新西兰一起线上聚会,并演唱同步性很差的“Happy Birthday To You”。
我希望我也可以和大家一起在Zoom上通话,以祝大家节日快乐,新年快乐! 节假日期间,我经常想一想重要的人,回顾他们为我或他人所做的事,并默默地表示我对他们的感谢。这使我感到与他们的联系更加紧密。
我觉得在我们远离社交的假期中思考这一点非常有价值:谁是您生活中最重要的人,您可能出于什么原因要感谢他们? 无论是面对面的还是在线的,我都希望您能找到属于自己的方式——在这个假期里培养于最重要的人之间的关系。 Keep learning!
1 2020年回顾


一、AI用于应对新冠疫情


 摄影:环球影业集团/阿拉米
摄影:环球影业集团/阿拉米
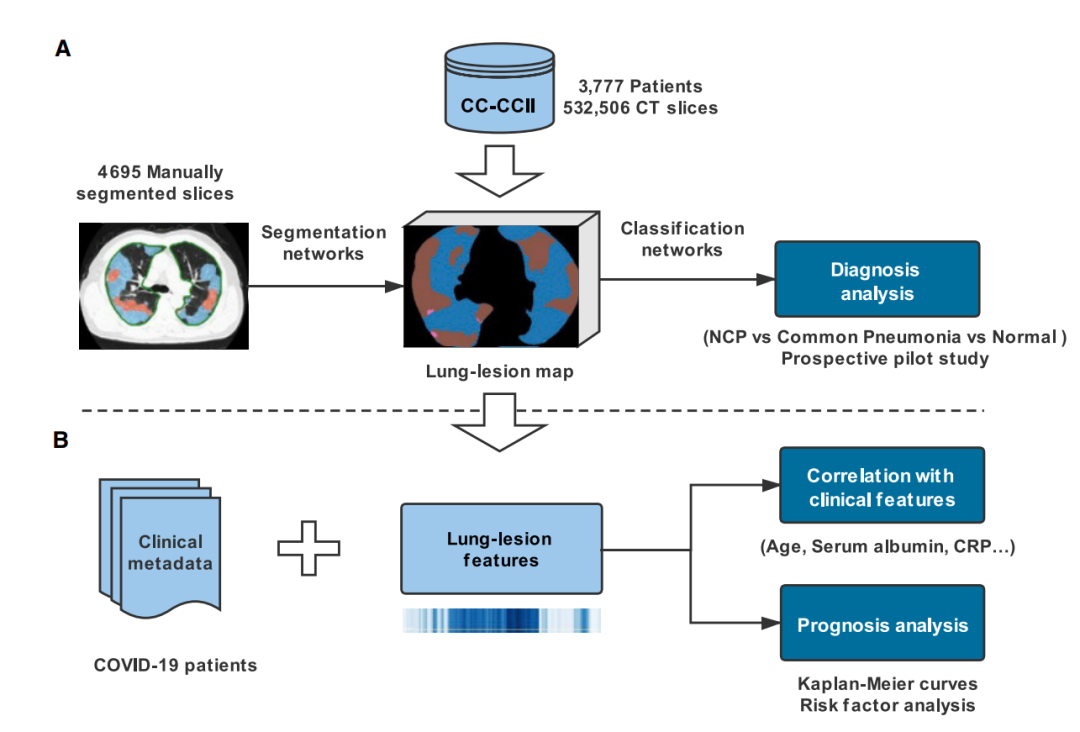 相关链接:https://www.cell.com/cell/pdf/S0092-8674(20)30551-1.pdf
相关链接:https://www.cell.com/cell/pdf/S0092-8674(20)30551-1.pdf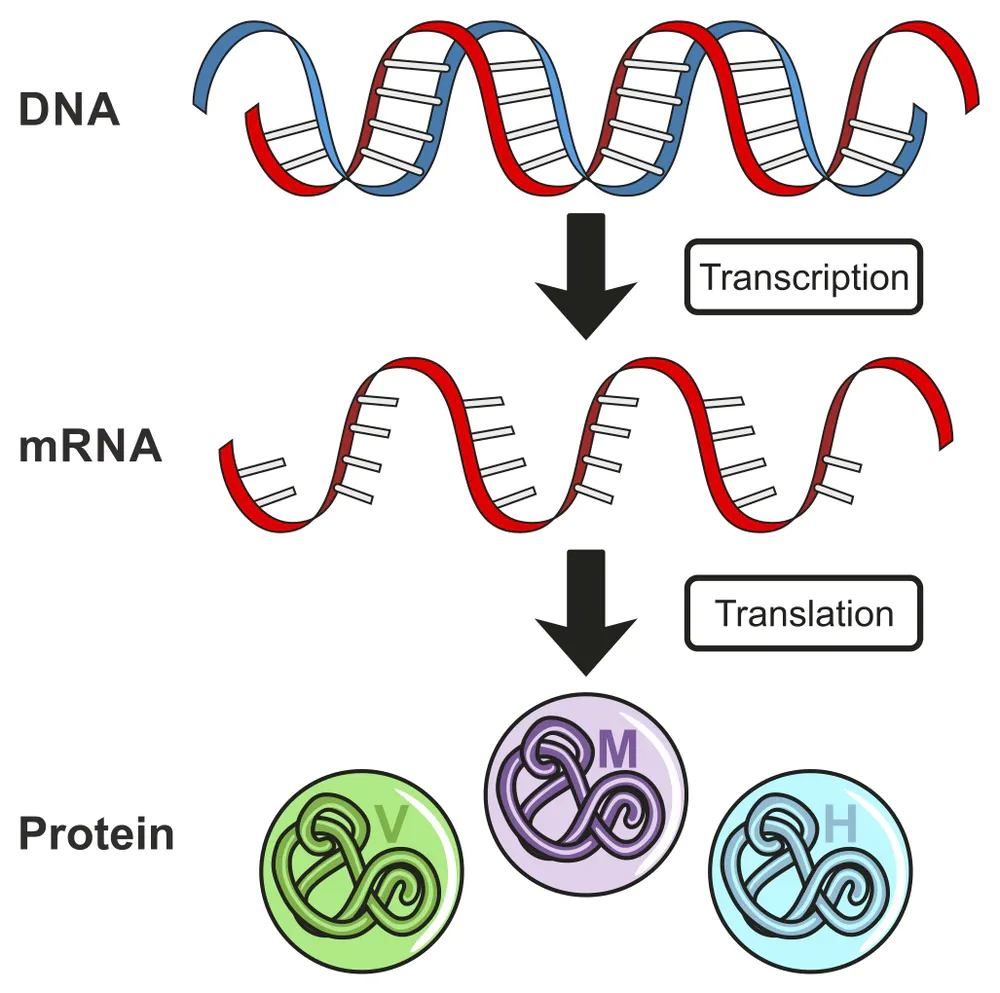 图源:https://www.shutterstock.com/
图源:https://www.shutterstock.com/二、Deepfake伪造“一切”
 图源:Techtalk
图源:Techtalk AI生成的假的鸟瞰图 图源:http://thiscitydoesnotexist.com/
AI生成的假的鸟瞰图 图源:http://thiscitydoesnotexist.com/

 论文链接:https://arxiv.org/pdf/2011.05552.pdf
论文链接:https://arxiv.org/pdf/2011.05552.pdf




今年6月,《华尔街日报》报道说,一些Facebook高管已经停止使用部分监管工具。该公司后来撤销了在选举期间使用的修改算法,因为它促进了某些新闻源的知名度。Facebook不够诚意的做法已经导致了一些员工辞职。 YouTube采用的算法成功减少了虚假信息内容的创作者的访问量。但是,它也增加了某些经常传播同样可疑信息的大型实体网站的访问量。
五、AlphaFold预测蛋白质三维结构
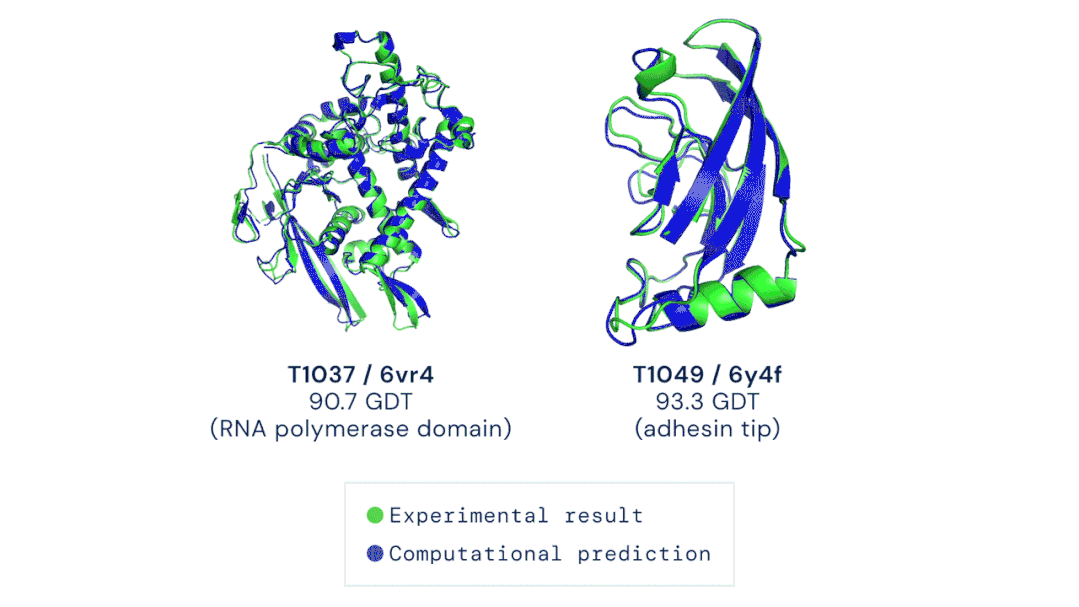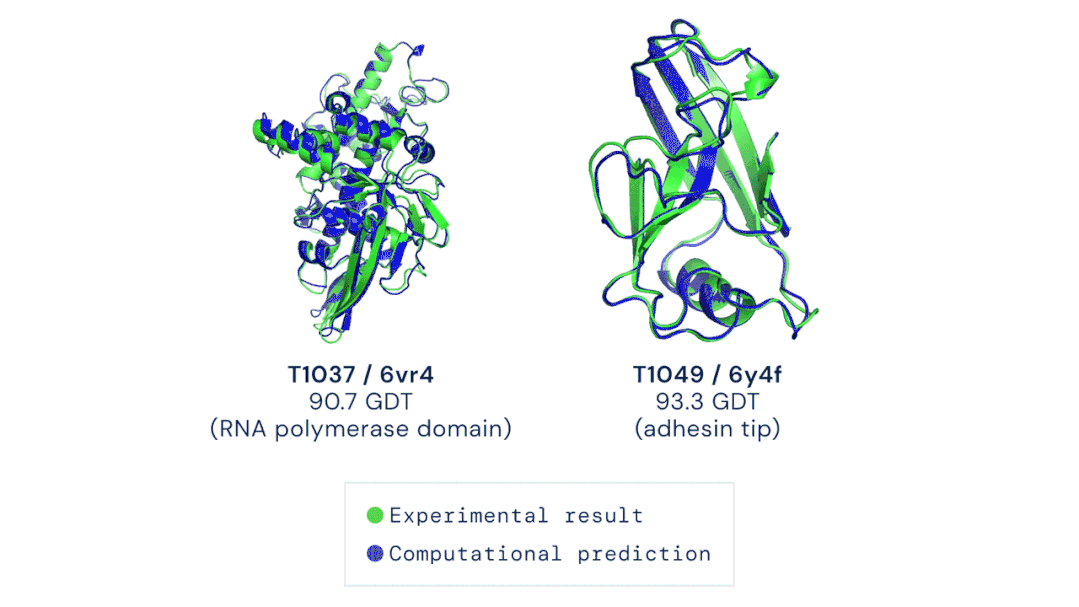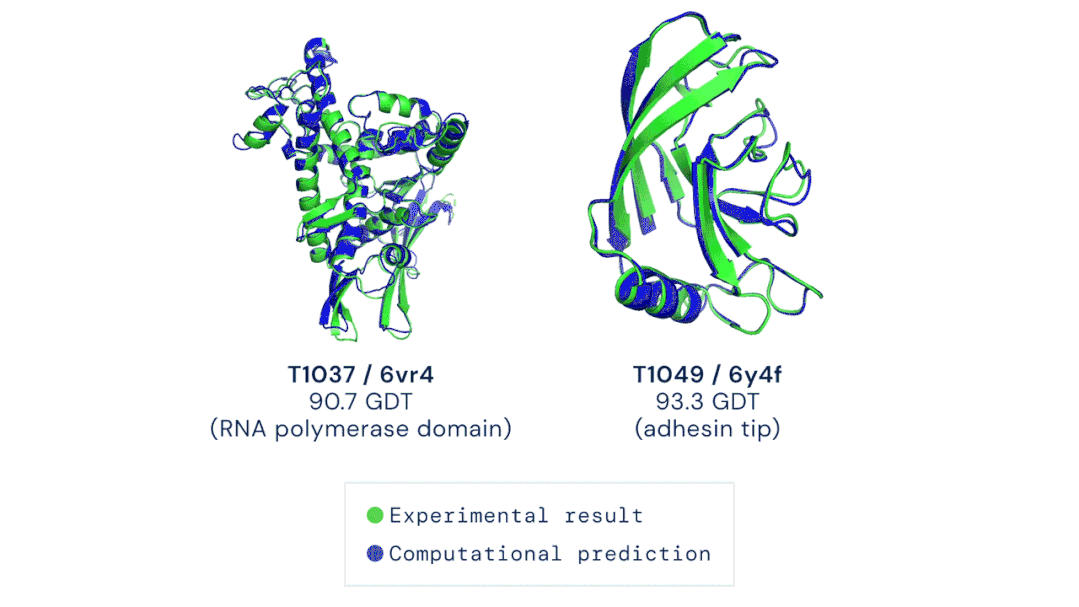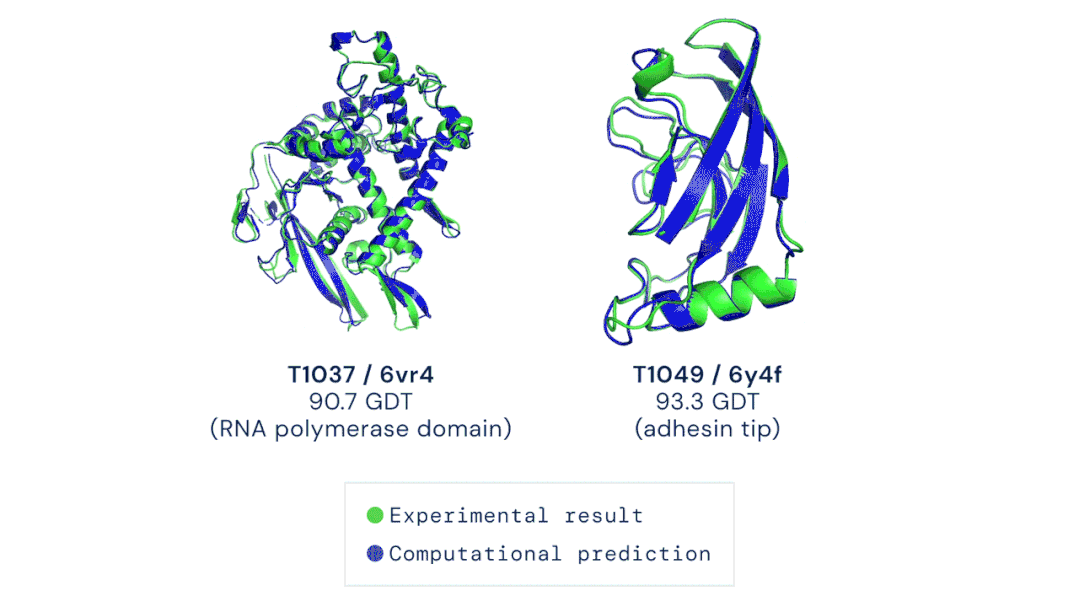

 图源:Musings about Librarianship
图源:Musings about Librarianship 图注:AI生成的哲学文章
图注:AI生成的哲学文章
2 2021年展望

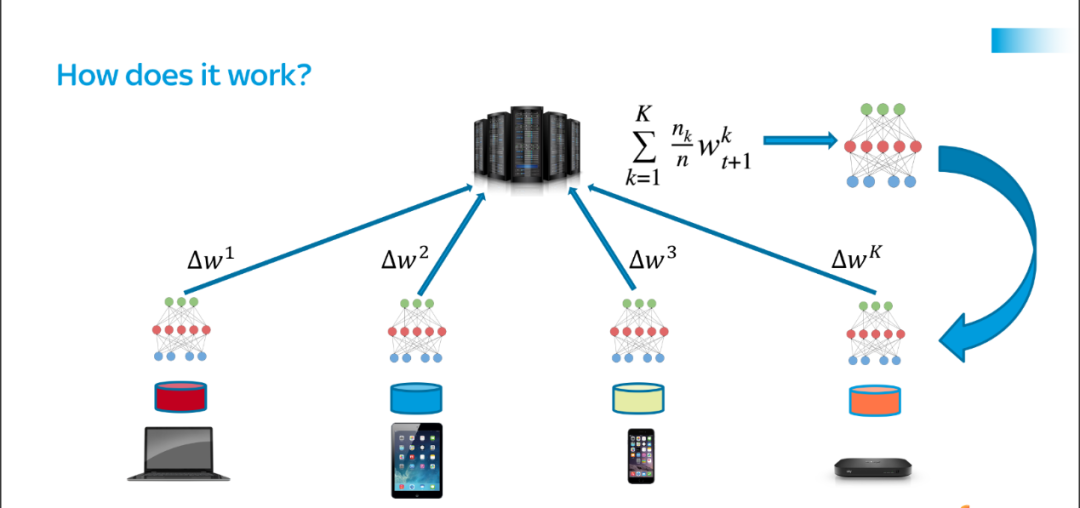 (来源:Proandroidde)
(来源:Proandroidde) (来源:Designnews)
(来源:Designnews) (来源:Nature)
(来源:Nature)
 图 | 多家公司参加反垄断调查(来源:Venture Beat)
图 | 多家公司参加反垄断调查(来源:Venture Beat)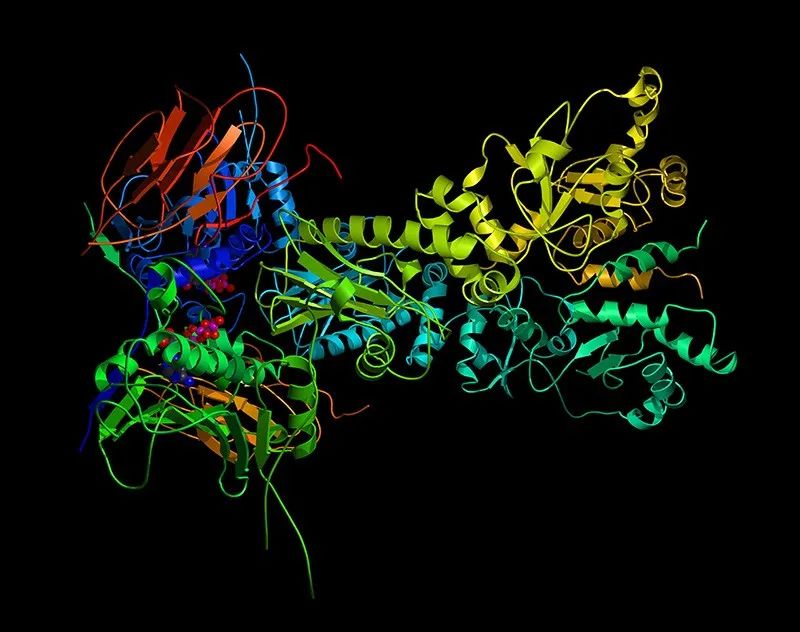 图 | AlphaFold 解决蛋白质结构问题(来源:Edward Kinsman)
图 | AlphaFold 解决蛋白质结构问题(来源:Edward Kinsman)推荐阅读

评论