
小心 Serverless | IDCF

来源:Thoughtworks洞见
一、技术乐观主义陷阱

技术具有商品属性,这是常常被我们忽略的一个事实。且不谈垄断之后带来的商业利益,一方面技术依赖市场的认可来彰显它的价值,另一方面技术还需要依靠大众的反馈才得以完善自己,所以庞大的用户群体是它繁荣的基石,它需要尽可能的为人所知。无论你是想吸引更多的项目和开发者加入某个社区中,还是想让某个框架摆脱默默无闻乃至脱颖而出,过程都务必依赖于大量的运营活动,其中不少也要倚靠背后大厂的资源投入。从近乎寿终正寝的 Silverlight 到近些年大火的 Flutter,无不遵循着类似的模式。
既然是面向大众的商品,商家必然会以利益相关者的姿态为其辩护和呐喊,这无可厚非。但在此影响之下,当技术人员对某项技术进行调研或者在被动接收来自行业内的更新时,得到的信息会不知不觉的向积极侧偏移,这对技术人员来说未必是好事情。因为我们很难分辨感官里的哪一些是事实,哪一些是观点,哪一些是有条件成立,更重要的是还有哪一些是它没有告诉你的。
Serverless 就是其中一个例子。
这篇文章不是对 Serverless 的批评。Serverless 是云原生架构(Cloud Native )下水到渠成的必然产物,从 IaaS(Infrastructure as a Service) 到 Paas(Platform as a Service) 甚至再到 Saas (Software as a Service),我们看到的是运维能力不断外包的迁移过程,这有助于塑造精锐团队专注于交付业务价值以及灵活应对市场变化——为什么我们要千篇一律的写登陆注册模块?如何才能将代码的维护成本降至最低?Serverless 便是在这些前提下诞生的。但 Serverless 只是其中一种解决方案(a solution),而非唯一的解决方案(the solution),更重要的是这篇文章会让你意识到它绝非是方案中的理想首选。
例如在每一篇介绍 Serverless 的文章中,都一定会提到因为冷启动缘故导致 Serverless 函数具有较慢的首次响应时间问题,但它们能够提供的信息通常到此便戛然而止了,这无法给我们带来任何帮助,我们也不会对它产生任何的警惕。如果我继续告诉你不同供应商的延迟各不相同,我所在项目中 Azure Serverless 的第一次启动延迟可以长达6秒,那么我相信此时你会更慎重的看待这条信息,并开始降低对于它作为 web server 的预期。
本文想强调的另一点是,虽然 Serverless 看似是近几年才诞生的“新”技术,但它背后遵循最佳实践依然是“旧”世界下人们早已达成的共识;在实际将它应用到现有产品的过程中,你需要关心内容与前 Serverless 时代也并无二致。例如在 OWASP 整理出的有关 Serverless 排名前十的安全问题 中,我不认为有哪一则是 Serverless架构“独享”的。Serverless 与传统服务相比的优势之一可能是前人的宝贵经验被固化到了平台和产品形态之中,用以确保你不必再走弯路。
考虑到通识性,本文主要使用 Azure 和 AWS 旗下的 Serverless 服务对问题进行说明。
二、被轻视的供应商锁定(vendor lock-in)
2.1 供应商的三道锁
供应商锁定在云原生架构下是无法避免的问题,如果你选择 Azure 作为你的云服务提供商,那么你大概率会顺带选择 Azure Blob Storage 而不是 AWS S3 作为你的存储服务,因为来自于同一个供应商下的服务契合度更高,维护起来更容易。同样考虑到成本和风险,自此之后更换服务的可能性也几乎为零。
好在编程语言和编程框架依然通用无界,加之容器化技术早已成熟,在开发常规业务代码的方面供应商并没有给我们造成太大的困恼。此时的供应商只充当配角,无论你是选择 AWS EventBridge 还是 Azure Event Grid,背后 Event-Driven 的决策不会发生改变,核心的业务代码不会受到影响,用 ExpressJS 写出的代码在不同服务商之间仍可复用。这种模式最明显的特点是业务人员可以专心开发业务代码,它们不用关心公司购买的是哪家提供商的产品。虽然听起来有些反模式,但代码与环境的适配可以全权交给运维人员去处理的这条路是可行的。
而 Serverless模式恰恰相反,它的崛起像是一道命题作文,在概念先行的前提下不同的供应商根据自己现存基础设施优先推出自己的解决方案。对于这一点有意思的是,如果你现在去看市面上讲解 Serverless 的技术图书,书中谈及的概念和代码实施方案一定是围绕某个单一平台编写的。
Serverless 中有一个很重要的概念正是这方面的体现:trigger。
顾名思义,trigger 是 function(本文的 function 泛指广义各个云平台上 Serverless 的实现代码,同时代指 Azure Function 和 AWS Lambda)的触发器,由它来负责启动 function。例如对于一个响应前端请求的 function 而言,http 请求就是它的 trigger。
但在 Serverless 生态中,http 是最不重要的。你不妨回想一下我们最经典的 Serverless 用例,离线创建略缩图:

在该流程中需要有 function 响应处理略缩图的消息,在存储之后需要有 function 将数据更新进数据库中。其中的消息服务和储存服务就是 function 的 trigger。
此时不难发现当你开始编写 function 时,你需要确认你的云供应商提供这类服务的具体产品是什么,消息服务在 Azure 中可以是 Azure Service Bus,但是到了 AWS 则变成了Message Queuing Service。不同服务提供的 API 和模型不尽相同,同时代码与服务集成的方式也是量身定做的,这是第一层锁。
其次为了在 function 代码中访问这类服务,裸写的代码是不被允许的,因为你需要在访问服务时用指定的方式传递 API Key,通常解决这个问题的办法是直接集成供应商提供的 client SDK,比如 @azure/service-bus 或是 AWS SDK。事实上从接收到请求的那一刻起,代码差异就已经注定了,虽然 Azure 和 AWS 都同意以 event handler 函数的形式来响应 trigger 的请求,但两者的函数签名差异明显,你能取得的函数所在的上下文也各有千秋。这是第二层锁。
这两者看上去似乎把硬件和软件层面都覆盖到了,最重要的“隐形锁”却无形中被忽略了——那就是供应商的意志,即它们希望你以什么样的方式去设计和编写 function。
以 API 架构为例,Azure 提供的服务比如 Azure Serverless 或者是 App Service 可以是相互独立的,哪怕你只购买其中的一项服务,你也可以单独为其配置 API Management, Identity 等属性。服务被允许对外暴露 HTTP 端口。在其官网给出的架构模式中,移动端设备可以直接访问 Azure Serverless 服务。
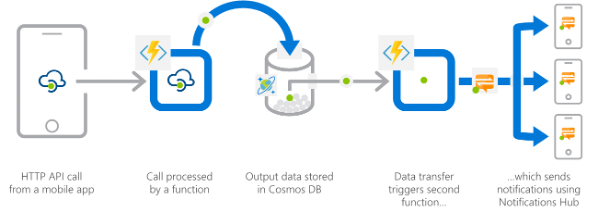
而在 AWS 中,服务的职责更为垂直,而非 Azure 般全能。HTTP 端点大多要被托管在 API Gateway 上,它为你提供了丰富的功能,比如权限验证、日志监控、缓存等等。同样在 AWS 官网给出的后端架构模式中,移动设备的请求必须要经过 API Gateway。
在 Azure Serverless 中每一个 Serverless 项目都有属于自己的配置文件 host.json,如果我们想要限制 function 处理的最大请求数,你只需要修改该文件的配置项即可:
{
"extensions": {
"http": {
"routePrefix": "api",
"maxConcurrentRequests": 100,
"customHeaders": {
"X-Content-Type-Options": "nosniff"
}
}
}
}上面代码中的 maxConcurrentRequests 就能用来控制并发请求数。
而在在 AWS 中,对于同步的 HTTP 端请求,官方建议你可以通过 API Gateway 限流功能(throtting)和设定 AWS WAF 规则来实现。
这层锁的危害在于你必须从一开始就在供应商的框架内来设计自己的解决方案。在 AWS 中你当然可以不选择 API Gateway 的 Lambda authorizer 功能作为 function 权限校验的解决方案,但我不确定其他路会让你绕多远。
即使你没有接触过 Lambda authorizer 也没有关系,我后面会有详细的讲解。在后面的章节我们也会看到,在抱怨它的同时我们不得不承认它背后遵循的依然是业内的最佳实践,我们看似无路可选,但实际上我们唯一能走的恰恰是前任留下的捷径。
2.2 解“锁”
好消息是在这一层可见的危机面前我们依然有能够缓和的余地。
2019 年 Thoughtworks 刚好发布了一篇关于如何避免 Serverless供应商锁定的文章 Mitigating Serverless lock-in fears,文章从硬件到软件层面都给出了很多减少迁移成本的建议。但在我看来其中最为实用的一则是:为程序设计一组好的架构。
虽然低入门门槛是 Serverlesss 不争的卖点之一,但是它的天花板依然可以达到传统技术栈程序相同的高度,一脉相承的优秀设计可给予后期维护上的便利。
例如一个对外发送邮件的用例首先采用 Azure Serverless Function 编写,我们在 httpTrigger 入口函数中可以直接引用 Azure SendGrid SDK 执行发送服务。
import * as SendGrid from "@sendgrid/mail";
SendGrid.setApiKey(process.env["SENDGRID_API_KEY"] as string);
const httpTrigger: AzureFunction = async function (context: Context, req: HttpRequest): Promise {
const email = {
to: 'test@example.com', // Change to your recipient
from: 'test@example.com', // Change to your verified sender
subject: 'Sending with SendGrid is Fun',
text: 'and easy to do anywhere, even with Node.js',
html: 'and easy to do anywhere, even with Node.js',
}
await SendGrid.send(email);
} 之后如果想将它迁移至 AWS Lambda 的话,发送邮件部分需要完全替换为调用 AWS 的 SES 服务:
import { SendEmailCommand } from "@aws-sdk/client-ses";
import { sesClient } from "./libs/sesClient.js";
// Set the parameters
const params = {
Destination: {},
Message: {},
};
const data = await sesClient.send(new SendEmailCommand(params));但事实上我们并不关心谁在为我们提供邮件发送服务,无论是 SendGrid 或者 SES 功能上并无差别。所以在设计这个程序时,我们完全可以提取一个公共的 email client,让 httpTrigger 入口函数调用 client 即可:
import emailClient from "./email-client";
const httpTrigger: AzureFunction = async function (context: Context, req: HttpRequest): Promise {
// ...
await emailClient.send(email);
} 那么在迁移的过程中,入口函数几乎无需改动,更改只发生在 client 中,我们也只需对 client 重新测试验证即可。如果你使用的是 C#,我们甚至可以将 EmailClient 抽象为一个接口注入后使用。说白了我们又回到了分离关注点,甚至可以说是六边形架构的老路。
针对接口编程还有一个优势——便于我们进行组件测试。
我们可以把上面的流程扩展一下,再被 trigger 之后首先需要从 KeyVault 中获取用于使用 SendGrid 的 API_KEY,在发送完毕 SendGrid 之后再使用 Application Insights 记录日志,流程如下图所示:

你可能有兴趣对虚线框内整套功能进行E2E(端到端)测试,这并非无法实现,但是难且代价极大。它的难首先体现在E2E本身的测试性质上,如果你对测试金字塔还有印象的话,处于金字塔顶端的 E2E 测试无论是运行成本还是维护成本都是最高的;其次由于 Serverless 第三方提供服务的差异性,你很难在每个人的本地搭建出一套线下稳定的测试环境来,由此产生的不确定和对线上环境的依赖有悖于我们对于测试能够快速反馈和重复执行的期望。
所以我建议在Serverless 中从代码中抽象出服务层(Service Layer),优先针对服务层进行测试。服务层是应用的边界和对业务逻辑和用例的封装,即使发生技术栈迁移它也应该是最不被影响的功能,它应该作为测试中的一个风险点。

而服务层打交道的对象不再是具体的供应商服务而是抽象的接口,这也便于我们在针对服务层的测试中对依赖进行 mock,优化测试流程。
三、Serverless 里的旧酒
3.1 身份验证
无论你使用什么样的技术栈,微服务、Serverless、Low-Code 等等,认证(Authentication)和授权(Authorization)始终是你无法逃避的问题。但不同技术栈下解决授权问题的模式并无不同。在这里先统一一下语言,以下用“验证”同时代指“认证”和“授权”。
以微服务架构为例,服务于接口背后的每一组微服务不可能都拥有独立的验证机制。如果你执意这么做的话需要解决不仅限于以下的问题:
如果每一组微服务有需要共享的验证逻辑,那么将相似的代码散布在不同的代码库中的做法会在将来带来散弹式修改的成本 具体的业务发开人员需要学习它们本不应该关心的认证逻辑,暴露出去的认证代码难免与业务代码耦合 如果在访问每一组微服务之前都要验证一次权限,势必整体会增加我们的系统延迟以及带来重复工作。
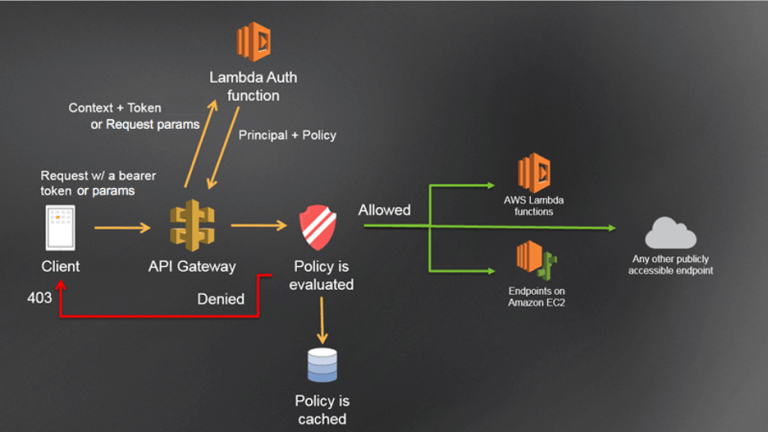
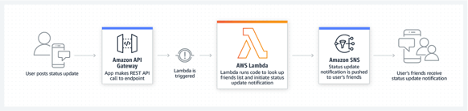
当客户端请求到达 API Gateway 时,authorizer 函数可以从请求中获取到用于验证的关键信息,比如 JWT。 假设客户端使用的是 Auth0 进行登陆,authorizer 则需要将 JWT 交由 Auth0 进行验证。 如果验证成功,authorizer 便会返回对应的 policy,API Gateway 根据 policy 来决定时许允许访问后续资源。
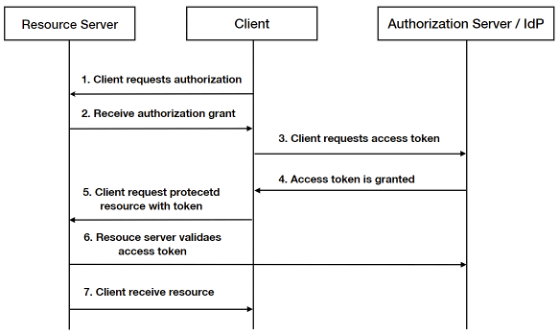
因为不用把用户名和密码暴露给客户,安全性得到提升。 限定访问期限,支持随时撤销访问权限。 细粒度的控制用户可访问的资源。
尾声

玩乐高,学敏捷,【规模化敏捷联合作战沙盘之「乌托邦计划」】,12月25-26日登陆深圳,将“多团队敏捷协同”基因内化在研发流程中,为规模化提升研发效能保驾护航!!🏰⛴
企业组队和个人均可报名参加,一起挑战极客乌托邦