
Spark+Kudu的广告业务项目实战笔记(一)
点击上方蓝色字体,选择“设为星标”




1.简介
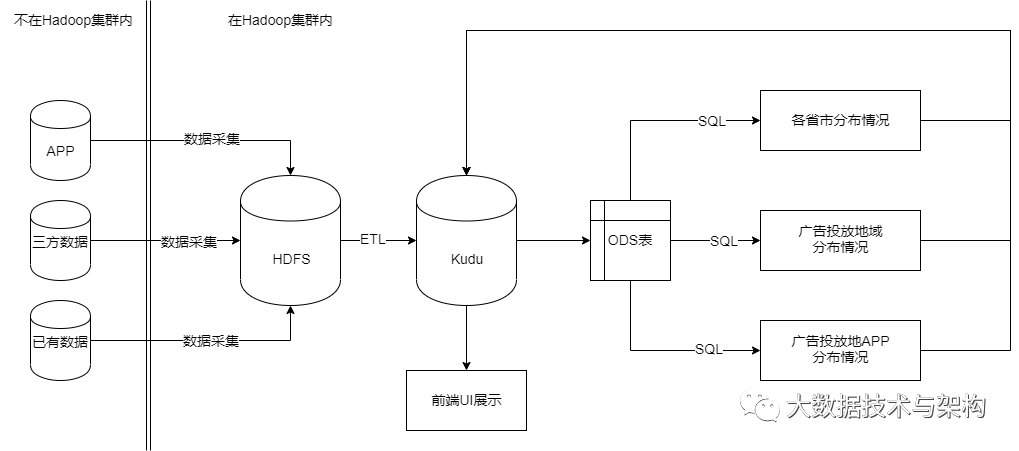
本项目需要实现:将广告数据的json文件放置在HDFS上,并利用spark进行ETL操作、分析操作,之后存储在kudu上,最后设定每天凌晨三点自动执行广告数据的分析存储操作。
2.项目需求
数据ETL:原始文件为JSON格式数据,需原始文件与IP库中数据进行解析
统计各省市的地域分布情况
统计广告投放的地域分布情况
统计广告投放APP分布情况
3.项目架构
4.日志字段
{"sessionid": "qld2dU4cfhEa3yhADzgphOf3ySv9vMml","advertisersid": 66,"adorderid": 142848,"adcreativeid": 212312,"adplatformproviderid": 174663,"sdkversion": "Android 5.0","adplatformkey": "PLMyYnDKQgOPL55frHhxkUIQtBThHfHq","putinmodeltype": 1,"requestmode": 1,"adprice": 8410.0,"adppprice": 5951.0,"requestdate": "2018-10-07","ip": "182.91.190.221","appid": "XRX1000014","appname": "支付宝 - 让生活更简单","uuid": "QtxDH9HUueM2IffUe8z2UqLKuZueZLqq","device": "HUAWEI GX1手机","client": 1,"osversion": "","density": "","pw": 1334,"ph": 750,"lang": "","lat": "","provincename": "","cityname": "","ispid": 46007,"ispname": "移动","networkmannerid": 1,"networkmannername": "4G","iseffective": 1,"isbilling": 1,"adspacetype": 3,"adspacetypename": "全屏","devicetype": 1,"processnode": 3,"apptype": 0,"district": "district","paymode": 1,"isbid": 1,"bidprice": 6812.0,"winprice": 89934.0,"iswin": 0,"cur": "rmb","rate": 0.0,"cnywinprice": 0.0,"imei": "","mac": "52:54:00:41:ba:02","idfa": "","openudid": "FIZHDPIKQYVNHOHOOAWMTQDFTPNWAABZTAFVHTEL","androidid": "","rtbprovince": "","rtbcity": "","rtbdistrict": "","rtbstreet": "","storeurl": "","realip": "182.92.196.236","isqualityapp": 0,"bidfloor": 0.0,"aw": 0,"ah": 0,"imeimd5": "","macmd5": "","idfamd5": "","openudidmd5": "","androididmd5": "","imeisha1": "","macsha1": "","idfasha1": "","openudidsha1": "","androididsha1": "","uuidunknow": "","userid": "vtUO8pPXfwdsPnvo6ttNGhAAnHi8NVbA","reqdate": null,"reqhour": null,"iptype": 1,"initbidprice": 0.0,"adpayment": 175547.0,"agentrate": 0.0,"lomarkrate": 0.0,"adxrate": 0.0,"title": "中信建投首次公开发行股票发行结果 本次发行价格为5.42元/股","keywords": "IPO,中信建投证券,股票,投资,财经","tagid": "rBRbAEQhkcAaeZ6XlTrGXOxyw6w9JQ7x","callbackdate": "2018-10-07","channelid": "123528","mediatype": 2,"email": "e4aqd67bo@263.net","tel": "13105823726","age": "29","sex": "0"}
5.IP规则库解析
本项目利用IP规则库进行解析,在生产中应该需要专门的公司提供的IP服务。IP规则库中的一条如下:
1.0.1.0|1.0.3.255|16777472|16778239|亚洲|中国|福建|福州||电信|350100|China|CN|119.306239|26.075302其中第三列是该段ip起始地址(十进制),第四列是ip终止地址(十进制)。
新建LogETLApp.scala:
package com.imooc.bigdata.cp08import com.imooc.bigdata.cp08.utils.IPUtilsimport org.apache.spark.sql.SparkSessionobject LogETLApp {def main(args: Array[String]): Unit = {//启动本地模式的sparkval spark = SparkSession.builder().master("local[2]").appName("LogETLApp").getOrCreate()//使用DataSourceAPI直接加载json数据var jsonDF = spark.read.json("data-test.json")//jsonDF.printSchema()//jsonDF.show(false)//导入隐式转换import spark.implicits._//加载IP库,建议将RDD转成DFval ipRowRDD = spark.sparkContext.textFile("ip.txt")val ipRuleDF = ipRowRDD.map(x => {val splits = x.split("\\|")val startIP = splits(2).toLongval endIP = splits(3).toLongval province = splits(6)val city = splits(7)val isp = splits(9)(startIP, endIP, province, city, isp)}).toDF("start_ip", "end_ip", "province", "city", "isp")//ipRuleDF.show(false)//利用Spark SQL UDF转换json中的ipimport org.apache.spark.sql.functions._def getLongIp() = udf((ip:String)=>{IPUtils.ip2Long(ip)})//添加字段传入十进制IPjsonDF = jsonDF.withColumn("ip_long",getLongIp()($"ip"))//将日志每一行的ip对应省份、城市、运行商进行解析//两个DF进行join,条件是:json中的ip在规则ip中的范围内jsonDF.join(ipRuleDF,jsonDF("ip_long").between(ipRuleDF("start_ip"),ipRuleDF("end_ip"))).show(false)spark.stop()}}
工具类中将字符串转成十进制的IPUtils.scala:
package com.imooc.bigdata.cp08.utilsobject IPUtils {//字符串->十进制def ip2Long(ip:String)={val splits = ip.split("[.]")var ipNum = 0Lfor(i<-0 until(splits.length)){//“|”是按位或操作,有1即1,全0则0//“<<”是整体左移//也就是说每一个数字算完向前移动8位接下一个数字ipNum = splits(i).toLong | ipNum << 8L}ipNum}def main(args: Array[String]): Unit = {println(ip2Long("1.1.1.1"))}}
其实也可以用SQL语句达到相同的效果:
//用SQL的方式完成jsonDF.createOrReplaceTempView("logs")ipRuleDF.createOrReplaceTempView("ips")val sql = SQLUtils.SQLspark.sql(sql).show(false)
在SQLUtils中写上SQL,因为ip_long已经解析出来了,主要就做了一个left join:
package com.imooc.bigdata.cp08.utils//项目相关的SQL工具类object SQLUtils {lazy val SQL = "select " +"logs.ip ," +"logs.sessionid," +"logs.advertisersid," +"logs.adorderid," +"logs.adcreativeid," +"logs.adplatformproviderid" +",logs.sdkversion" +",logs.adplatformkey" +",logs.putinmodeltype" +",logs.requestmode" +",logs.adprice" +",logs.adppprice" +",logs.requestdate" +",logs.appid" +",logs.appname" +",logs.uuid, logs.device, logs.client, logs.osversion, logs.density, logs.pw, logs.ph" +",ips.province as provincename" +",ips.city as cityname" +",ips.isp as isp" +",logs.ispid, logs.ispname" +",logs.networkmannerid, logs.networkmannername, logs.iseffective, logs.isbilling" +",logs.adspacetype, logs.adspacetypename, logs.devicetype, logs.processnode, logs.apptype" +",logs.district, logs.paymode, logs.isbid, logs.bidprice, logs.winprice, logs.iswin, logs.cur" +",logs.rate, logs.cnywinprice, logs.imei, logs.mac, logs.idfa, logs.openudid,logs.androidid" +",logs.rtbprovince,logs.rtbcity,logs.rtbdistrict,logs.rtbstreet,logs.storeurl,logs.realip" +",logs.isqualityapp,logs.bidfloor,logs.aw,logs.ah,logs.imeimd5,logs.macmd5,logs.idfamd5" +",logs.openudidmd5,logs.androididmd5,logs.imeisha1,logs.macsha1,logs.idfasha1,logs.openudidsha1" +",logs.androididsha1,logs.uuidunknow,logs.userid,logs.iptype,logs.initbidprice,logs.adpayment" +",logs.agentrate,logs.lomarkrate,logs.adxrate,logs.title,logs.keywords,logs.tagid,logs.callbackdate" +",logs.channelid,logs.mediatype,logs.email,logs.tel,logs.sex,logs.age " +"from logs left join " +"ips on logs.ip_long between ips.start_ip and ips.end_ip "}
6.存入Kudu
打开Kudu:
cd /etc/init.d/llsudo ./kudu-master startsudo ./kudu-tserver start
在8050端口看下是否能进入Kudu的可视化界面。
val result = jsonDF.join(ipRuleDF, jsonDF("ip_long").between(ipRuleDF("start_ip"), ipRuleDF("end_ip")))//.show(false)//创建Kudu表val masterAddresses = "hadoop000"val tableName = "ods"val client = new KuduClientBuilder(masterAddresses).build()if(client.tableExists(tableName)){client.deleteTable(tableName)}val partitionId = "ip"val schema = SchemaUtils.ODSSchemaval options = new CreateTableOptions()options.setNumReplicas(1)val parcols = new util.LinkedList[String]()parcols.add(partitionId)options.addHashPartitions(parcols,3)client.createTable(tableName,schema,options)//数据写入Kuduresult.write.mode(SaveMode.Append).format("org.apache.kudu.spark.kudu").option("kudu.table",tableName).option("kudu.master",masterAddresses).save()
Schema数据如下所示:
lazy val ODSSchema: Schema = {val columns = List(new ColumnSchemaBuilder("ip", Type.STRING).nullable(false).key(true).build(),new ColumnSchemaBuilder("sessionid", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("advertisersid",Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("adorderid", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("adcreativeid", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("adplatformproviderid", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("sdkversion", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("adplatformkey", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("putinmodeltype", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("requestmode", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("adprice", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("adppprice", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("requestdate", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("appid", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("appname", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("uuid", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("device", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("client", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("osversion", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("density", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("pw", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("ph", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("provincename", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("cityname", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("ispid", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("ispname", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("isp", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("networkmannerid", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("networkmannername", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("iseffective", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("isbilling", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("adspacetype", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("adspacetypename", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("devicetype", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("processnode", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("apptype", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("district", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("paymode", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("isbid", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("bidprice", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("winprice", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("iswin", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("cur", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("rate", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("cnywinprice", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("imei", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("mac", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("idfa", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("openudid", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("androidid", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("rtbprovince", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("rtbcity", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("rtbdistrict", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("rtbstreet", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("storeurl", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("realip", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("isqualityapp", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("bidfloor", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("aw", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("ah", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("imeimd5", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("macmd5", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("idfamd5", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("openudidmd5", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("androididmd5", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("imeisha1", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("macsha1", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("idfasha1", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("openudidsha1", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("androididsha1", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("uuidunknow", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("userid", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("iptype", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("initbidprice", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("adpayment", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("agentrate", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("lomarkrate", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("adxrate", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("title", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("keywords", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("tagid", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("callbackdate", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("channelid", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("mediatype", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("email", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("tel", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("sex", Type.STRING).nullable(false).build(),new ColumnSchemaBuilder("age", Type.STRING).nullable(false).build()).asJavanew Schema(columns)}
数据写入成功后在Kudu可视化界面检查一下:
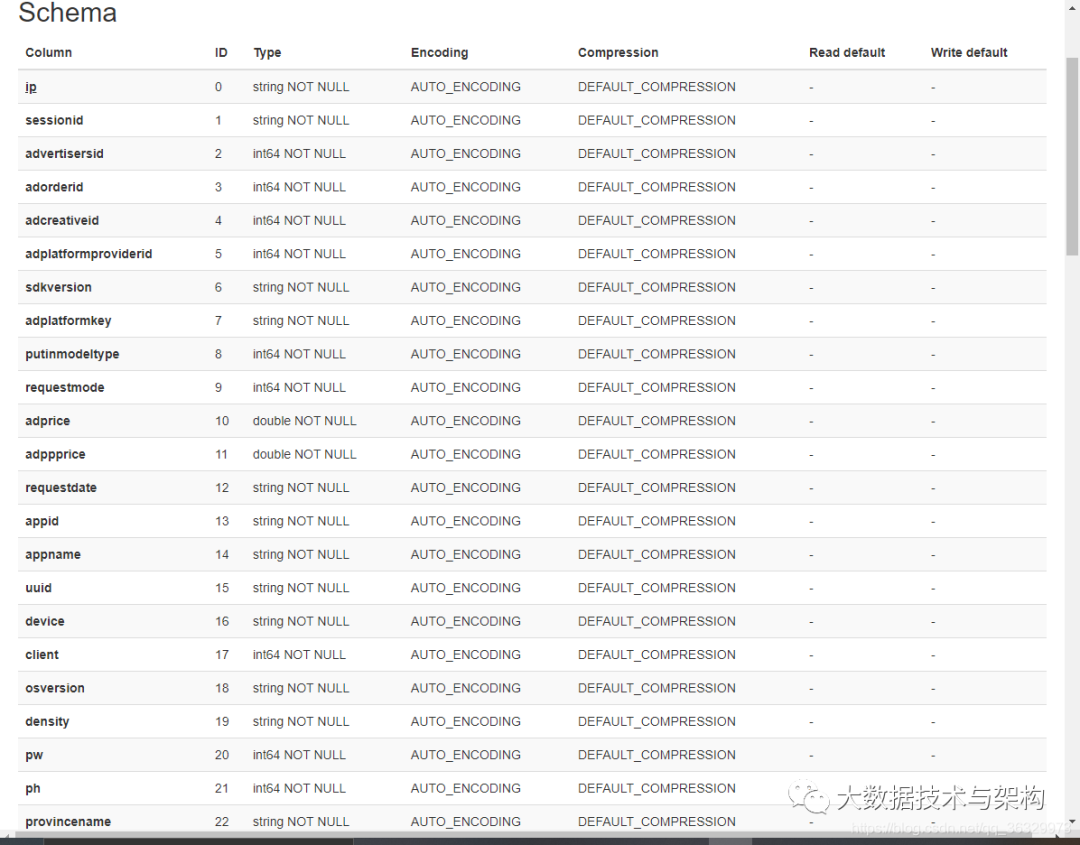
最后在IDEA里看下数据是否写入成功了:
spark.read.format("org.apache.kudu.spark.kudu").option("kudu.master",masterAddresses).option("kudu.table",tableName).load().show()
结果为:
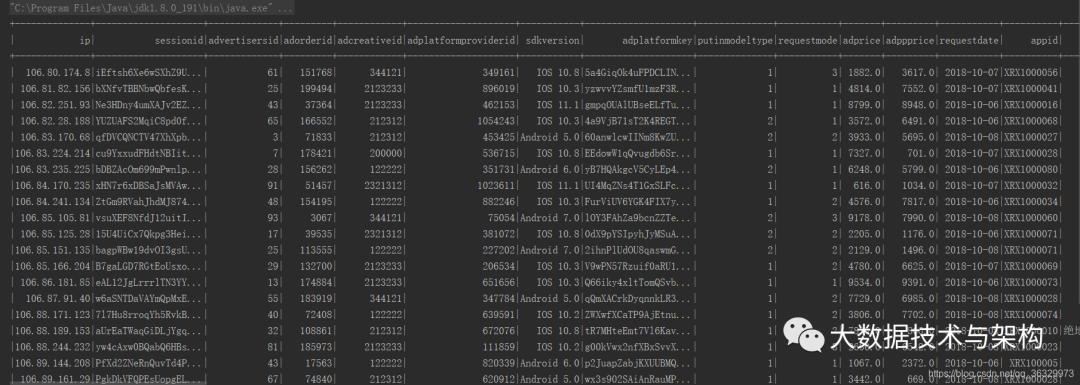
说明导入成功。
7.代码重构
建立KuduUtils.scala进行重构,需要传入的内容为result/tableName/master/schema/partitionId
package com.imooc.bigdata.cp08.utilsimport java.utilimport com.imooc.bigdata.chapter08.utils.SchemaUtilsimport org.apache.kudu.Schemaimport org.apache.kudu.client.{CreateTableOptions, KuduClient}import org.apache.kudu.client.KuduClient.KuduClientBuilderimport org.apache.spark.sql.{DataFrame, SaveMode}object KuduUtils {/*** 将DF数据落地到Kudu* @param data DF结果集* @param tableName Kudu目标表* @param master Kudu的Master地址* @param schema Kudu的schema信息* @param partitionId Kudu表的分区字段*/def sink(data:DataFrame,tableName:String,master:String,schema:Schema,partitionId:String)={val client = new KuduClientBuilder(master).build()if(client.tableExists(tableName)){client.deleteTable(tableName)}val options = new CreateTableOptions()options.setNumReplicas(1)val parcols = new util.LinkedList[String]()parcols.add(partitionId)options.addHashPartitions(parcols,3)client.createTable(tableName,schema,options)//数据写入Kududata.write.mode(SaveMode.Append).format("org.apache.kudu.spark.kudu").option("kudu.table",tableName).option("kudu.master",master).save()// spark.read.format("org.apache.kudu.spark.kudu")// .option("kudu.master",master)// .option("kudu.table",tableName)// .load().show()}}
val masterAddresses = "hadoop000"val tableName = "ods"val partitionId = "ip"val schema = SchemaUtils.ODSSchemaKuduUtils.sink(result,tableName,masterAddresses,schema,partitionId)
文章不错?点个【在看】吧! ?
评论