
再见,Excel数据透视表;你好,pd.pivot_table
导读
Excel作为Office常用办公软件之一,其在一名数据分析师的工作日常中也占有一定地位,比如个人就常常倾向于依赖Excel完成简单的数据处理和可视化作图,其中数据处理部分则主要是运用内置函数+数据透视表两大部分。
Excel数据透视表虽好,但在pandas面前它也有其不香的一面!

选择Excel菜单栏中插入数据透视表选项卡
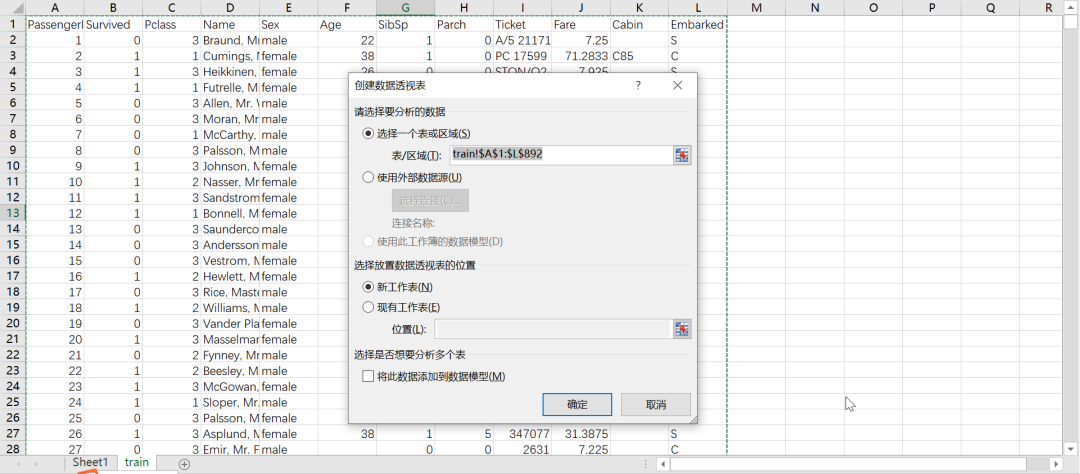
分别拖动目标字段到相应行列位置,设置统计函数为求和
得到统计好的数据透视表结果
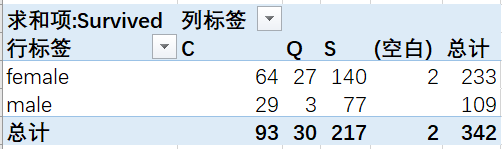
至此,我们可以发现数据透视表中实际存在4个重要的设置项:
行字段
列字段
统计字段
统计方式(聚合函数)
值得指出的是,以上4个要素每一个都可以不唯一,例如可以拖动多个字段到行/列字段中形成二级索引,也可完成对不同字段的统计,以及拖动相同字段设置不同统计方法实现多种聚合。
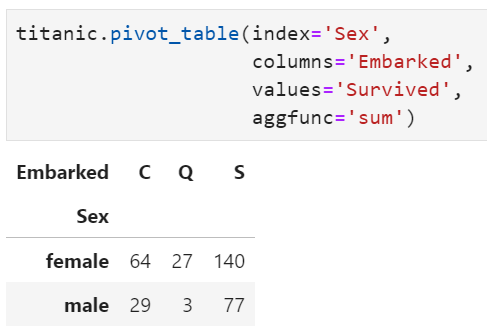
values : 待聚合的列名
index : 用于放入透视表结果中的行索引列名
columns : 用于放入透视表结果中列索引列名
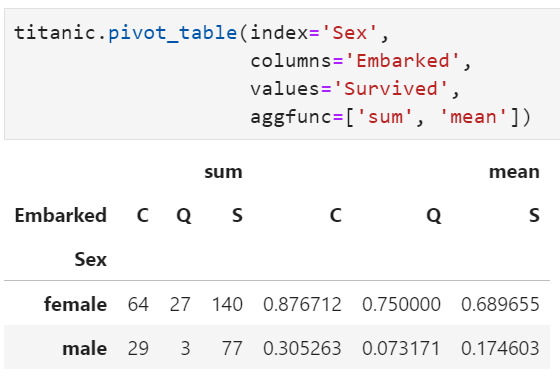
aggfunc : 聚合统计函数,可以是单个函数,也可以是函数列表,还可以是字典格式,默认聚合函数为均值。当该参数传入字典格式时,key为列名,value为聚合函数值,此时values参数无效
fill_value : 缺失值填充值,默认为None,即不对缺失值做任何处理。注意这里的缺失值是指透视后结果中可能存在的缺失值,而非透视前的原表中缺失值
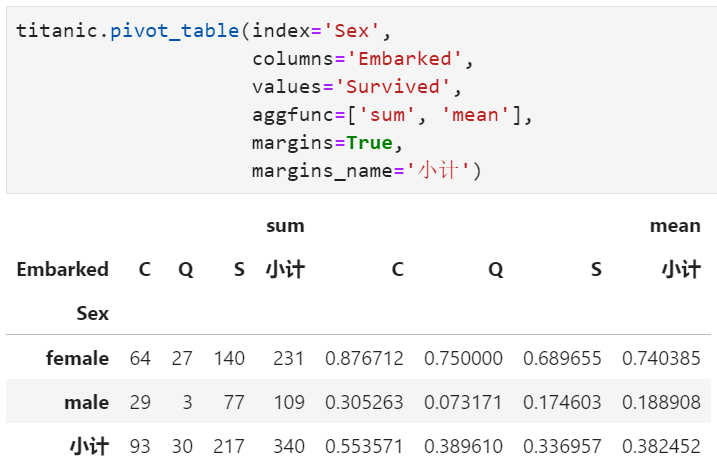
margins : 指定是否加入汇总列,布尔值,默认为False,体现为Excel透视表中的行小计和列小计
margins_name : 汇总列的列名,与上一个参数配套使用,默认为'All',当margins为False时,该参数无作用
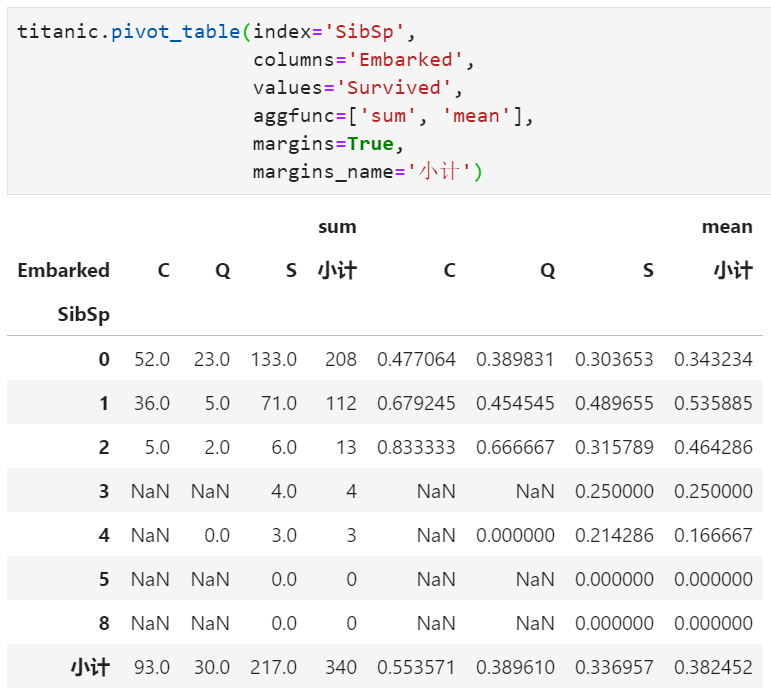
dropna : 是否丢弃汇总结果中全为NaN的行或列,默认为True。例如,行有3个取值,列有3个取值,经过透视表重组后理论上最多有3×3=9个结果,但实际可能只有3×2=6个非空值,其中全为空的一列默认舍弃
observed : 适用于分类变量,一般无需关注。
其中前4个参数是核心参数。
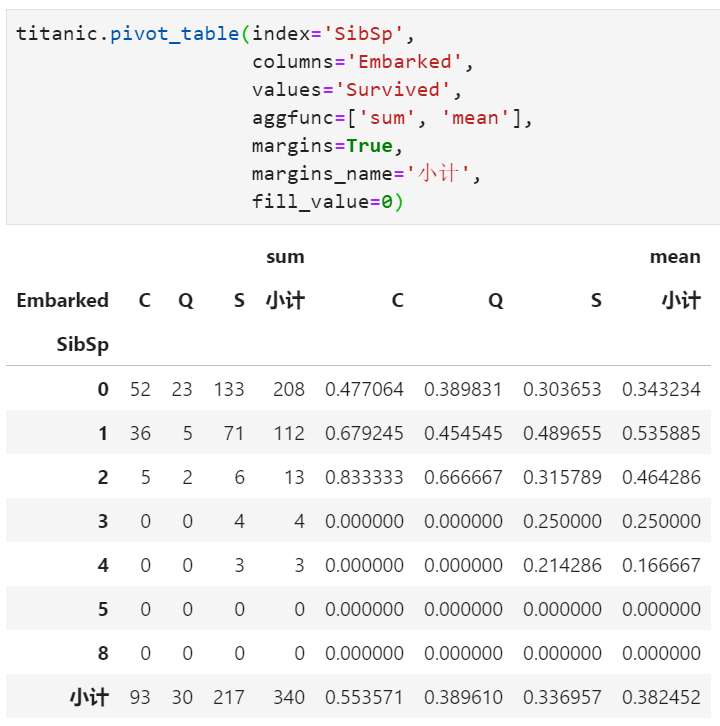
实际上,上述效果就相当于执行完pivot_table的基础上再加一个fillna()函数即可。
pivot仅适用于数据变形,即由长表变为宽表,相当于对数据进行了重组;而pivot_table除了数据重组外,还有一个额外的效果,即数据聚合,即若重组后对应的行标签和列标签下取值不唯一,此时按指定方法进行聚合;换言之,pivot能干的事情,pivot_table都能干,反之则不然。
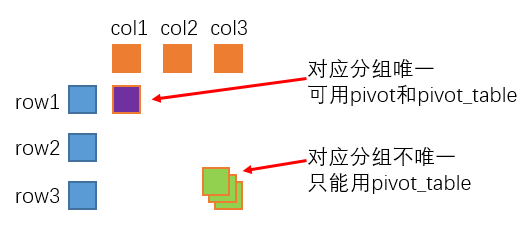
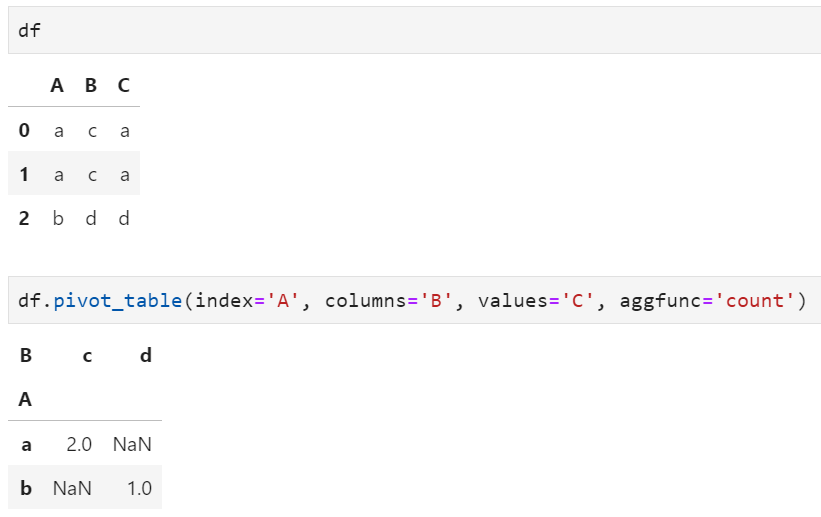
pivot由于仅涉及行列重组和变形,所以一般更适用于分类变量;而pivot_table在重组的基础上还增加了聚合统计的过程,所以一般更适用于数值型变量,但对于支持分类变量统计的聚合函数(例如count),则pivot_table也可适用。
相关阅读: