
2020 PyTorch全球开发者日:Pytorch 2021 将走向何方?

极市导读
PyTorch 开发者日在11月12日结束,本文总结了该场活动的一些最值得关注的部分,主要内容包括Pytorch目前的挑战、发展方向以及技术细节方面的核心框架等。>>加入极市CV技术交流群,走在计算机视觉的最前沿
作者利益相关:Facebook员工,业余PyTorch开源贡献者。

PyTorch Dev Day 2020(https://pytorchdeveloperday.fbreg.com/schedule)在11/12号举办。尽管没有现场参与,我还是把全场视频看了一遍,这里会根据个人的理解尽可能总结个人认为最有价值、值得关注的部分,和大家分享。
第一部分:KeyNote
这部分对于高屋建瓴地了解PyTorch Leadership的想法很关键,毕竟他们的决定对整个PyTorch的发展方向而言举足轻重。基本上可以分解为如下几点:
#1 - PyTorch目前所处的形势
首先,PyTorch应该大概率是目前最好用的深度学习框架(不是第一也是之一)
1.6K贡献者, 4.5万下游项目 70% NIPS2019论文引用 PyTorch不再是一个仅适用于研究不适合生产环境的框架:
众多公司在生产环境采用PyTorch(比如Uber) 在Facebook内部有750+个生产环境部署的模型用的是PyTorch 目前PyTorch团队最新开拓的的三个技术领域分别是
Composability以提高PyTorch的可拓展性 分布式RPC原语以支持分布式训练 兼容Google的XLA以在TPU上运行PyTorch

非常高的adoption rate和增长势头
#2 - PyTorch从哪来,要到哪去
PyTorch一开始是主要给Research Community用的框架,但是由于各方面的需求逐步转化成当前这样一个生产环境兼容,并拥有自己不可忽视的生态圈的产品。以下原则贯彻过去,且将指导未来:
Community Co-Development: 开源、社区共赢,而不是闭门造车 Cutting Edge Research:紧跟研究前沿,保证易用性 Production Grade:生产环境不能落下 Interoperable Ecosystem:跟其他系统兼容整合,壮大整个生态圈
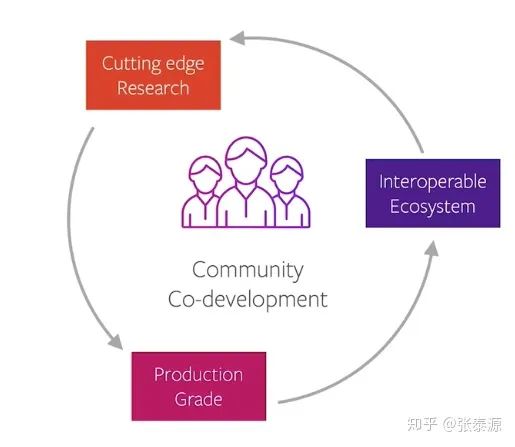
坚持基本路线一百年不动摇
#3 - PyTorch 前路会遇到哪些挑战
易用性:用户量/模型数量迅速增长,新的Operator不断出现(95%都不是简单的卷积操作),这意味着PyTorch必须继续在易用性上投入才能更好应对人/代码复杂度提升。
Facebook AI Research 正在研究一种新的前端"语言" Tensor Statement,可以让Operator的实现变得更加简单 计算资源:模型/用户的数量增加意味着计算资源消耗的大量增加,提高程序效率迫在眉睫。因此:
PyTorch团队利用TorchScript来优化模型,提高运行效率 FAIR 甚至还利用强化学习来提到模型优化器本身的性能,进一步提高优化后的模型的执行效率 雨后春笋般涌现的Accelerator: 一个深度学习框架如果不能适配涌现的新硬件,则会很容易失去市场竞争力,因此必须大力发展AI Compiler
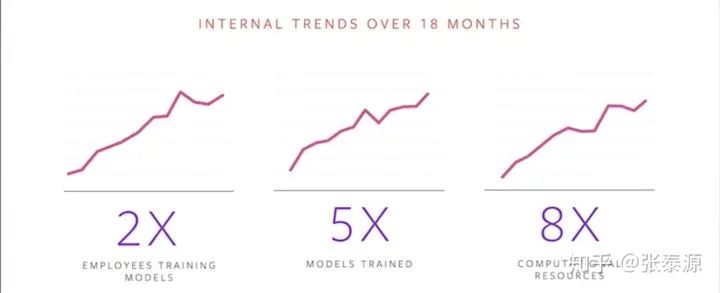
极高的增长……对计算资源、存储、网络传输带宽的scale up都是挑战
第二部分:技术细节介绍
每个Track我都会摘一些个人觉得比较有亮点/有趣的工作,想要全面了解的话请移步官网。
#1 - Core 核心框架
Distributed RPC:这是一套框架/原语,使得开发分布式训练变得更加快速、直观。
比如说,利用rpc.remote就可以在本地创建一个在另外一台机器上面的Tensor的引用,对其操作就如同操作一个本地Tensor一样方便 Profiling & Visualization: 讲述了如何对PyTorch代码进行profiling,如何追踪并可视化训练过程。
个人看法:这在我看来表示PyTorch向一个成熟的开源软件又迈进一步 在开发和线上部署的时候,很多工程师的时间其实花在了性能调优,打日志调试/定位问题上面,而profiling/visualization相关的工具链的发展对这个大有帮助 PyTorch on Windows: 微软负责PyTorch的经理举的数字很有意思:如果我们考虑全球所有的开发者的话(而不是我们常说的互联网/机器学习开发者),大部分开发者使用的还是Windows平台。
这就意味着,尽管现在大部分PyTorch的用户还是在Linux/Mac平台开发,PyTorch在Windows上的运行还是存在一些坑,但是PyTorch到后面的用户增长很可能会来自于这些Windows平台开发者 PyTorch Mobile: PyTorch在移动平台端的支持得到进一步提升,而且可以用一行代码把一个模型转换为针对移动平台优化的格式
这项Effort也得到了Android的合作与支持,看来提升移动端性能是行业共同的需求 这也很符合前面提到的Production Grade原则
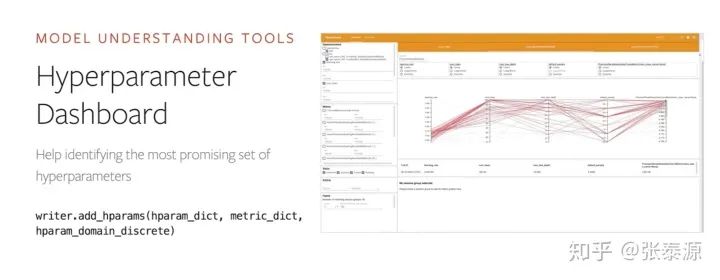
利用Tensorboard对模型调试、理解的一个例子:以可视化的方式帮助分析超参数对模型的影响
#2 - Research 科研领域
Torch for R & Hasktorch: 众所周知PyTorch的前身是Torch(现在的内核依然是C++的LibTorch)。这块讲的是怎么在R和Haskell里面实现类似PyTorch的API(但是用的同一套内核),从而让这些语言的用户不需要切换到Python也可以享受到PyTorch一般的爽感
这个感觉可能跟 @王益 大神参与的golang + Torch类似? 但个人判断:Python的势头是止不住的。目前大部分的研究+生产环境生态系统都是围绕着Python来打造。就算横空出世了另外一门语言的Binding可以跟Python一样好用(不太可能做到比Python的版本还好用),跑起来更快,但是想要在用户群体和生态上追赶基本不可能 Model Interpretability: 介绍了一个专门做模型可解释性的Library,叫Captum (Captum · Model Interpretability for PyTorch)
前两年在组内做Planning的时候其实想过做一个类似的东西,没想到现在已经出来了这么成熟的产品,支持了包括LIME在内的各种算法 个人看法:可以预见它很可能会成为模型可解释性方面的头号产品。很多诸如MLFlow的机器学习模型管理平台都在抢着把它整合进自己的工具链,其抢手程度可见一斑 DeepSpeed: 微软发布的基于PyTorch的深度学习库
这个目测是目前唯一一个能训练参数量达1T(=一万亿)的库。鉴于这个库是在太牛逼,之后我会专门写一篇文章讲解,这里略过细节
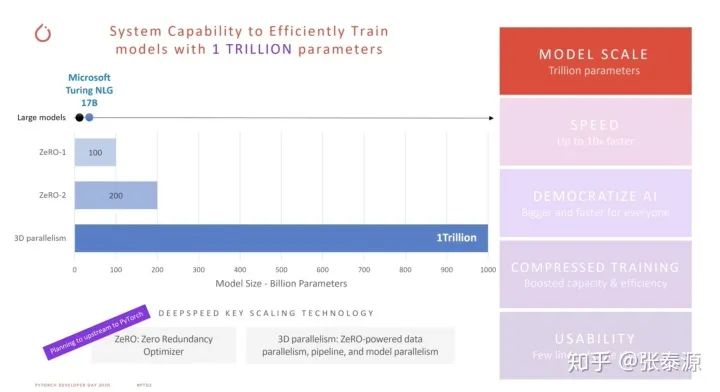
DeepSpeed 霸气1T参数。而且还有很多别的牛逼的功能(看右边的全家桶)
#3 - Production Ecosystem 生产环境相关的生态
MLFlow: Databrick (Spark创始人开的公司) 做的机器学习管理平台,从而可以更好、更工程化地管理/开发机器学习项目。
MLFlow一开始出来的时候,我关注了一下,当时支持的主要还是sklearn等比较基础的机器学习库。现在看来已经开始官方地支持PyTorch模型的训练和追踪、可视化等,这对于PyTorch进一步工程化、平民化有很重要的意义 PyTorch + XLA: 讲的是如何把PyTorch模型转变成XLA可支持的格式,从而可以在TPU上跑
这就是前面提到的Interoperable原则的一个很好的体现。XLA这个其实是Google搞出来,让机器学习模型可以更好适配不同硬件的东西。Facebook把自己的PyTorch弄成跟XLA兼容,一定程度上可以借XLA之手可以更容易地适配不同的硬件,自己可以少费点功夫,最后大家双赢
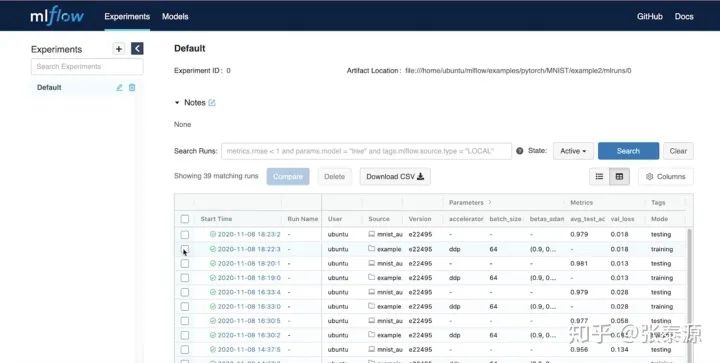
ML Flow的一个示意图,用于追踪模型训练的参数,结果比较,相关的文件/asset等
#4 - Privacy 用户隐私相关
Differential Privacy: 现在只需几行代码改动便可以使得一个PyTorch模型的训练符合Differential Privacy的要求
这块应该是最近比较热门的方向——我的理解是,如何让机器学习模型学习数据集整体的特性,同时无法得知单独数据点的细节(因为这样单个用户的隐私可能就会被泄漏),如果理解有误的话还有望指正 个人看法:PyTorch内置Differential Privacy的支持应该对于大公司内部做ML Infra,以及做机器学习平台的公司来说利好——简单的修改即可以说自己符合Differential Privacy,产品卖的好,面对政客/媒体底气更足了 OpenMined: 一个可以让数据科学家在不直接获取私有数据的前提下,训练模型或者查询聚合过的数据(比如说,医院不开放他们的病人数据,但我可以通过这个平台用我的算法和医院的数据训练模型给医院用,同时我自己得知不了任何病人的隐私)
个人看法:这是个很有意思的想法(跟前段时间火的用区块链解决隐私问题感觉还有那么一丢丢联系),但是看现在的发展程度还处于比较早期阶段,怎么落地,怎么证明商业价值,还有比较多需要探索的地方,可以长期关注一下
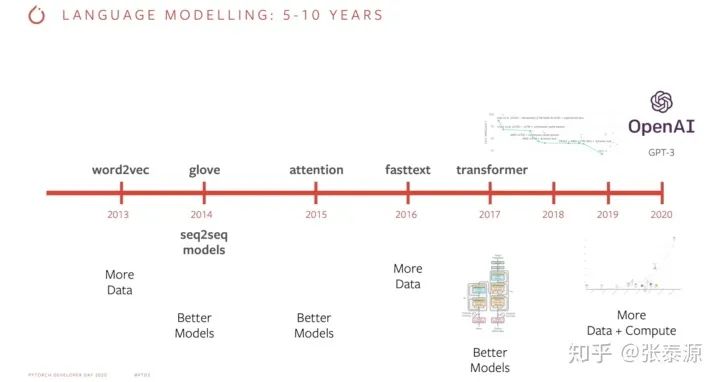
OpenMined的Leader举的例子,以证明他的观点:机器学习的众多飞跃里,有很多来自于数据量的提升,而不是算法的提升。因此,他认为隐私安全的数据共享,可以提高机器学习的数据集数量和大小,从而继续推动机器学习的飞跃。
第三部分:总结
以下纯属个人看法/预测:
对于PyTorch以及核心团队来说,易用性是立身之本,永远不可能放弃,它也很有可能在"最好用的深度学习框架“榜单长期称霸。因此PyTorch用户基本不用担心他会变得难用,感觉research community就放心大胆用吧
PyTorch接下来最大的挑战和机会,就是在生产环境中证明自己,尤其是服务器端Inference。这块是一个刚开始大力投入且还有很多可以深挖的技术领域,著名大神们会介入,也会出现新的大神
对于在考虑生产环境用PyTorch的工程师团队来说,我的建议是
选取一些有意义(但又不至于至关重要以至于不容许任何失败)的Use Case开始试水 及早和PyTorch团队建立联系,提供反馈。我的猜想是PyTorch团队有极大的动力来和用户深度合作来改进PyTorch在生产环境的技能以及修Bug。作为Early Adopter可以获得更多的支持以及建立自己公司在这个技术领域的口碑,对于未来的招聘会有帮助 接下来将会是PyTorch Ecosystem的高速发展期。配套设置的需求会增多,也会有越来越多的类似于Captum [见上文] 这样基于PyTorch而开发的辅助工具/轮子出现,对于有兴趣的开源程序猿来说是个机会
对于做机器学习平台型产品的公司来说,暂时还不是All-in-PyTorch的时候,但是一定对PyTorch的支持不能懈怠
最后多说两句:我个人对PyTorch还是非常看好的,甚至有点想把它跟Apache Hive类比起来:后者可以让人写SQL来执行MapReduce,对于开发生产力提升是个极大的飞跃;性能可能不一定有手写的MR代码好,但是通过引擎不停优化也不影响在生产环境的广泛应用。PyTorch以易用性/开发生产力为第一位,同时不断优化底层性能,因此我认为它最终也会被极为广泛的采用。
推荐阅读
