编辑:好困 桃子
【新智元导读】AI大模型「环球影城」正式开业!汽车人、霸天虎共集结,这次不是为了赛博坦,也不是元宇宙,而是为了疯狂争夺「火种源」。现实世界中,AI巨头在也在为这一生命之源——大模型展开了无尽的争夺战 。
AI大模型领域的「环球影城」正式开业!

汽车人、霸天虎集结,这次不是为了赛博坦,而是为了疯狂争夺「火种源」。

现实世界中,AI巨头们在也在为这一「生命之源」——大模型展开争夺战,进行巅峰对决。
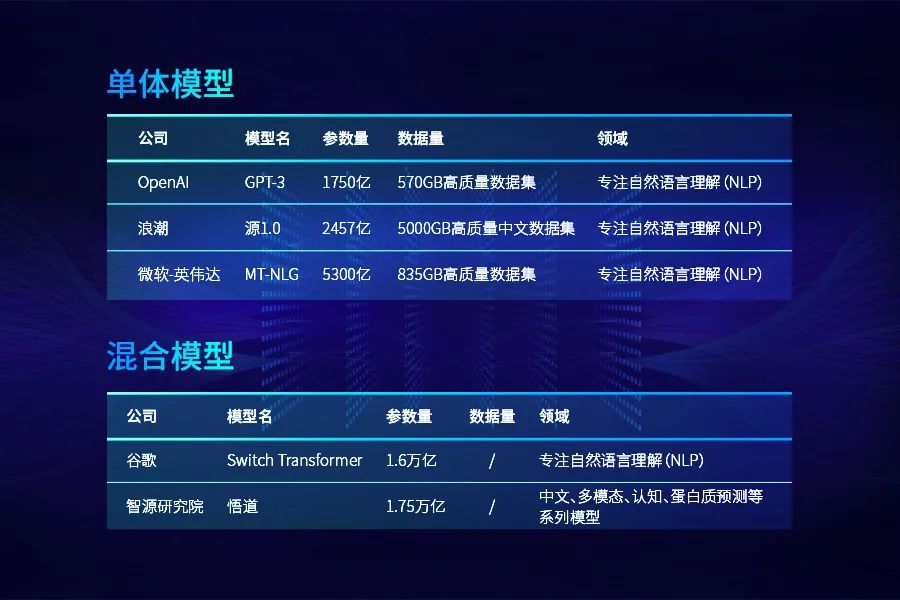
5300亿参数,烧了4480块英伟达GPU,威震天-图灵(MT-NLG)可以说是当前最大的语言模型。此外,GPT-3有1750亿参数,浪潮「源1.0」2457亿参数...
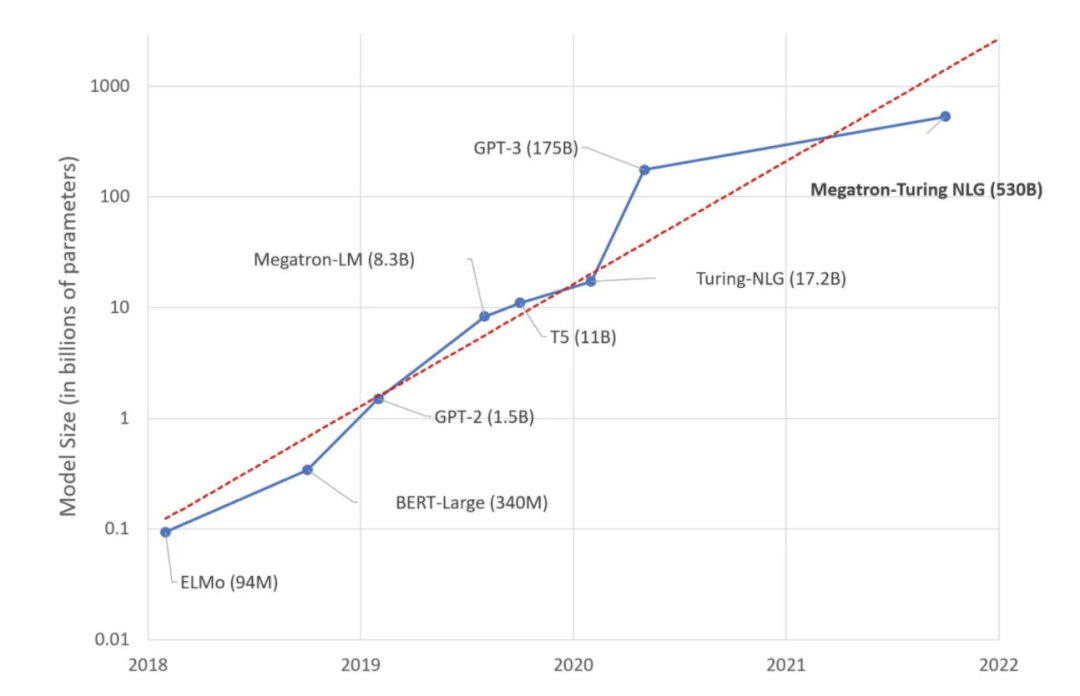
自从2018年谷歌推出BERT模型以来,语言模型做的越来越大,仿佛没有终点。短短几年,模型参数已经从最初的3亿,扩张到万亿规模。
然而,这并不是终点,争夺「火种源」角逐还在继续。
那么,这些AI巨头到底在争什么,在探索什么?
大模型究竟是否是一条正确的道路?
从国外来看,2018年,谷歌提出3亿参数BERT模型惊艳四座,将自然语言处理推向了一个前所未有的新高度。
紧接着,OpenAI在2019年初推出GPT-2,15亿参数,能够生成连贯的文本段落,做到初步的阅读理解、机器翻译等。还有英伟达威震天(Megatron-LM)83亿参数,谷歌T5模型110亿参数,微软图灵Turing-NLG模型170亿参数。这些模型一次次不断地刷新参数规模的数量级,而2020年却成为这一数量级的分界线。大火的GPT-3,1750亿参数,参数规模达到千亿级别,直逼人类神经元的数量。就在近日,微软和英伟达联手发布了Megatron-Turing自然语言生成模型(MT-NLG),5300亿参数。号称同时夺得单体Transformer语言模型界「最大」和「最强」两个称号。除了千亿规模的稠密单体模型,还有万亿规模的稀疏混合模型。如果将单体模型比作珠穆朗玛峰,那么混合模型就是喜马拉雅山脉其他的小山峰。谷歌在今年年初推出了1.6万亿参数的Switch Transformer。而智源「悟道2.0」1.75万亿参数再次刷新万亿参数规模的记录。为什么会这样?一句话,大模型是大势所趋,更是必争的高地!就好比十几年前深度学习的崛起一样,国内外AI巨头看到了这个技术的未来,于是纷纷入局于此,各种各样深度学习的模型不断涌现。在讨论这个问题之前,需要先搞懂大模型都有哪些分类。比如说,从模型架构角度:单体、混合;功能角度:NLP、CV、对话等等。
其中,谷歌「Switch Transformer」采用Mixture of Experts (MoE,混合专家) 模式将模型进行了切分,其结果是得到的是一个稀疏激活模型。虽然节省了计算资源,但是精度却很难提高。
目前来说,自然语言处理领域单体大模型的顶流是:「GPT-3」、「MT-NLG」以及「源 1.0」。https://arxiv.org/pdf/2110.04725.pdf
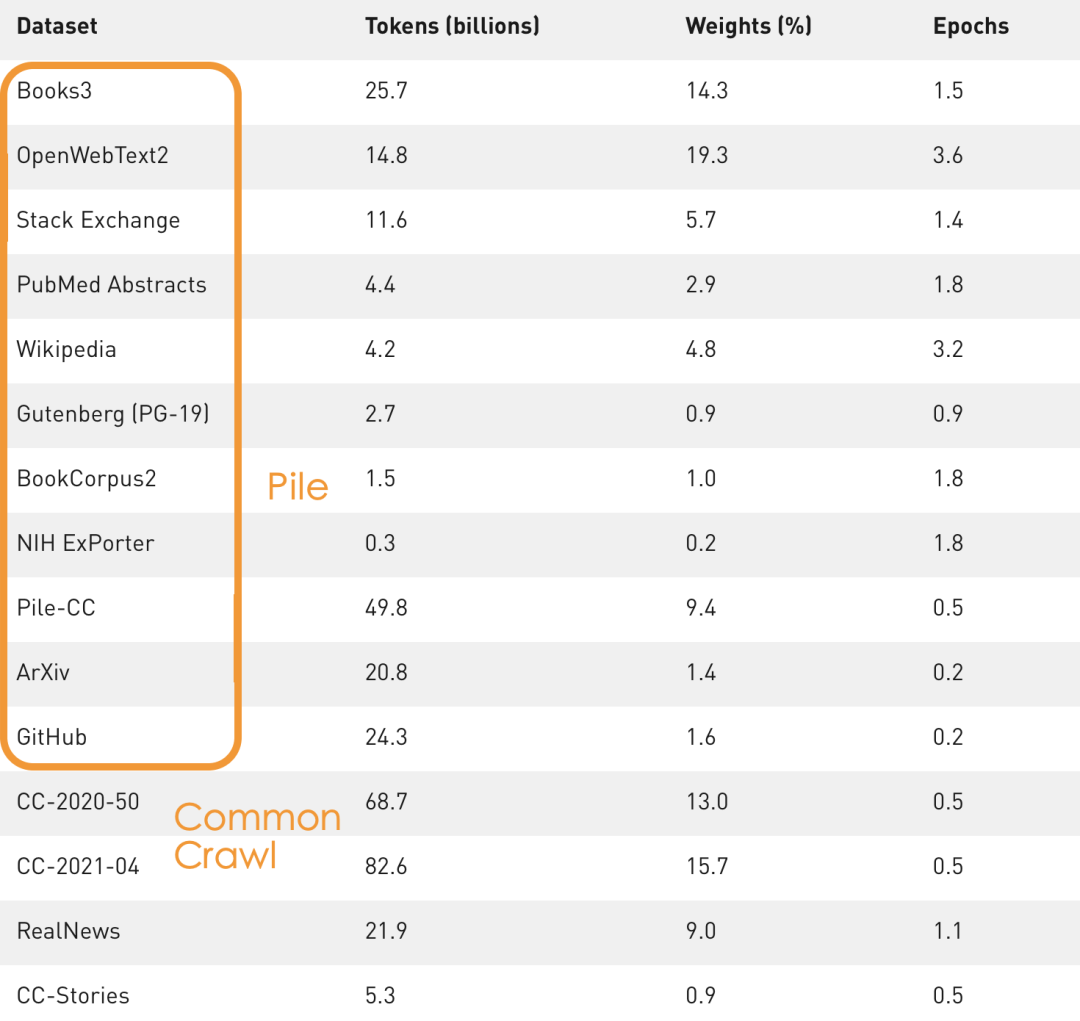
在自然语言理解方面,由于分词方式不同、同一词组不同歧义以及新词汇等方面挑战,所以中文训练的难度更高。例如分词难点:中国科学技术大学;中国\科学技术\大学;中国\科学\技术\大学。这三种不同的分词形式,表达的意思有着天壤之别。这还仅仅是其中之一。因此,训练中文NPL模型的训练难度要比同量级英文模型难度更高。有包含HackerNews、Github、Stack Exchange、ArXiv甚至还有YouTube字幕的The Pile;有包含了超过50亿份网页元数据的数据平台Common Crawl;甚至还可以用Reddit论坛的内容来进行训练。就拿The Pile来说吧,其中包含了825GB的多样化开源语言建模数据,由22个较小的、高质量的数据集合组成。GPT-3采用了规模超过292TB,包含499亿个token的数据集。
| | | |
| | | |
| | | |
| Books2 (Libgen or similar) | | | |
| Books1/BookCorpus (Smashwords) | | | |
| | | |
| |
| |
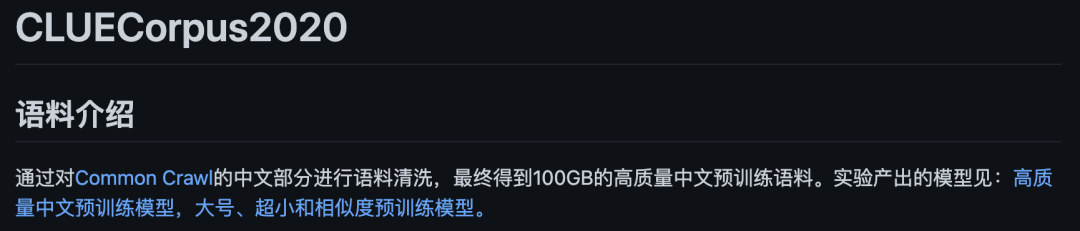
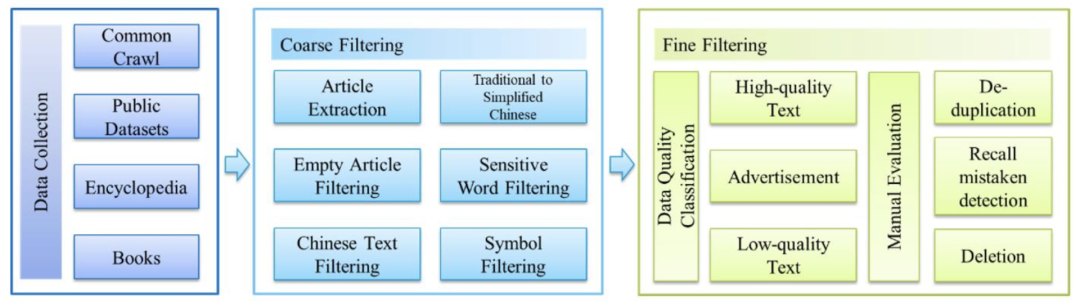
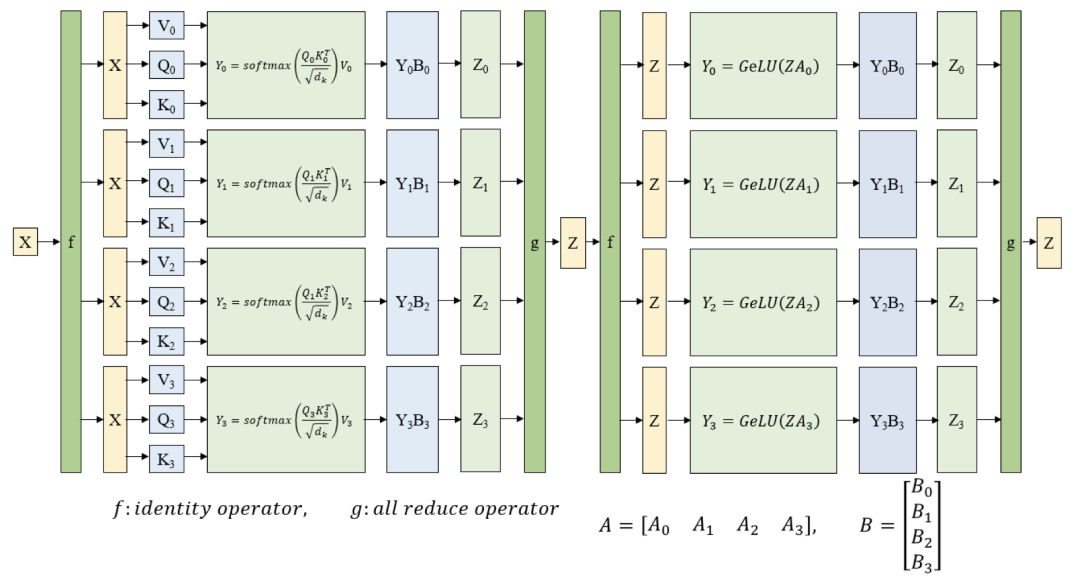
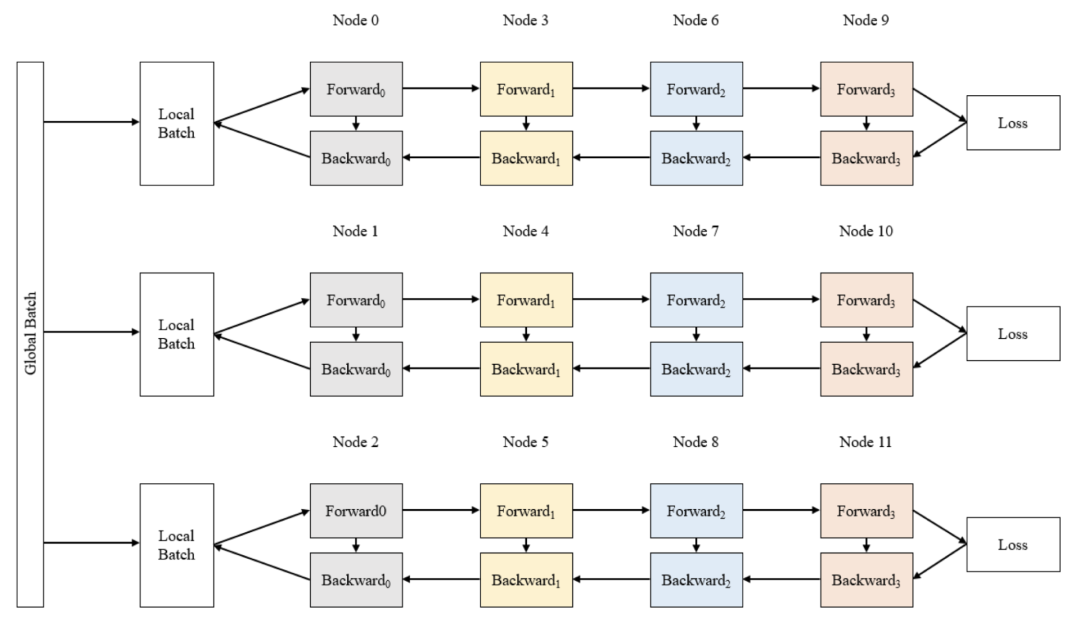
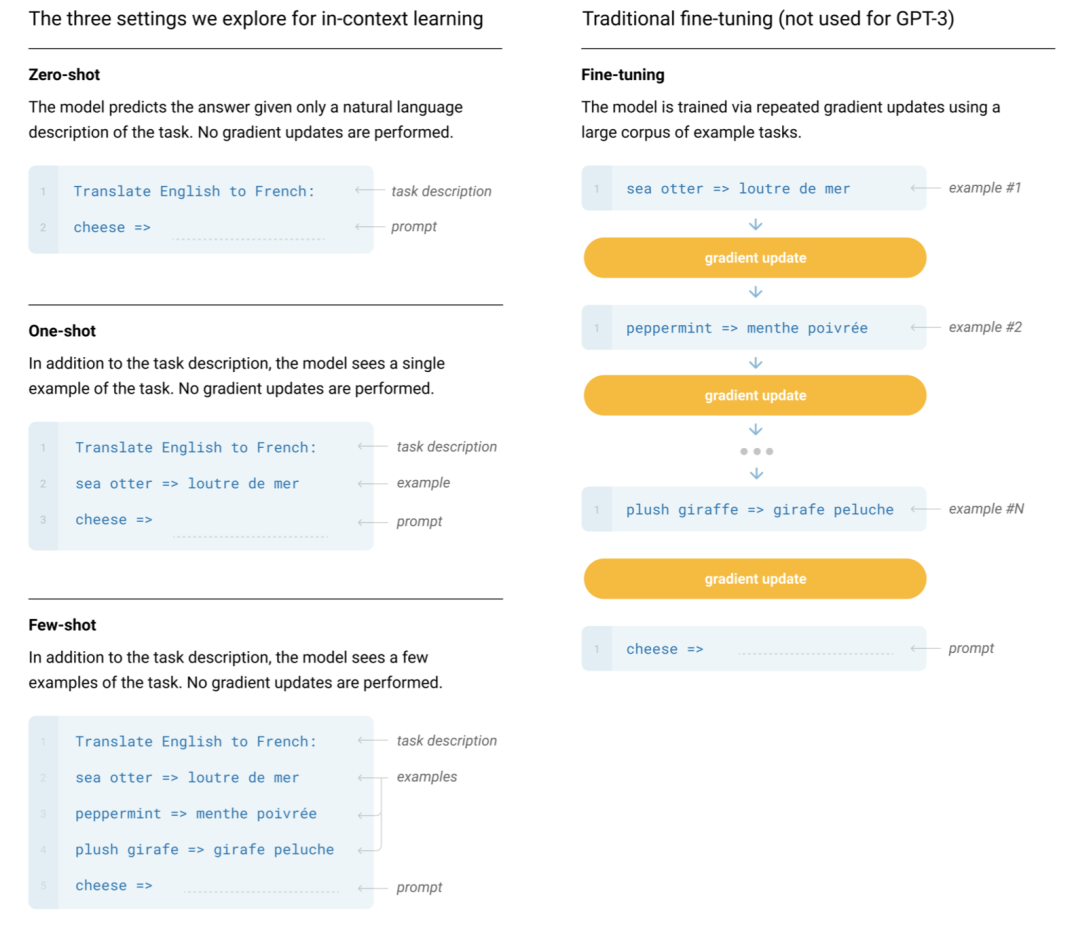
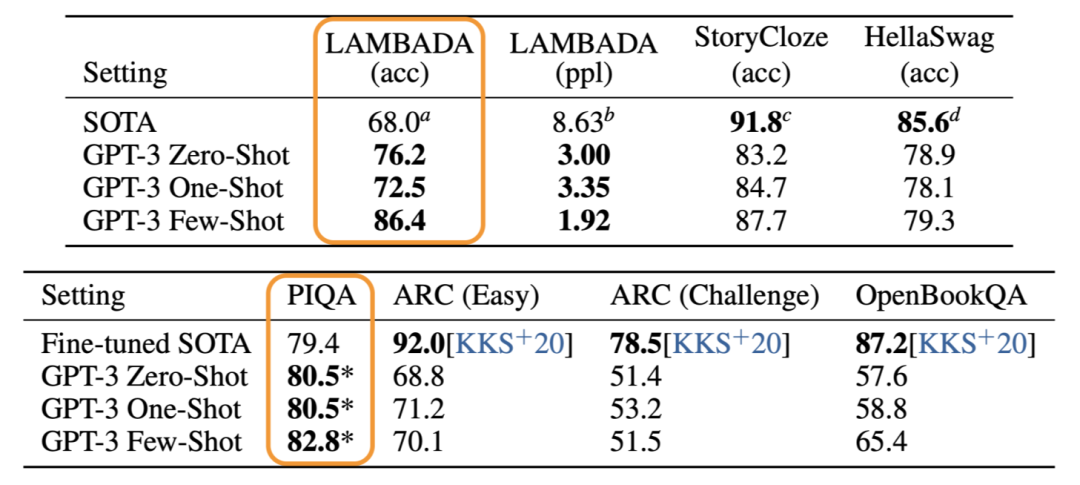
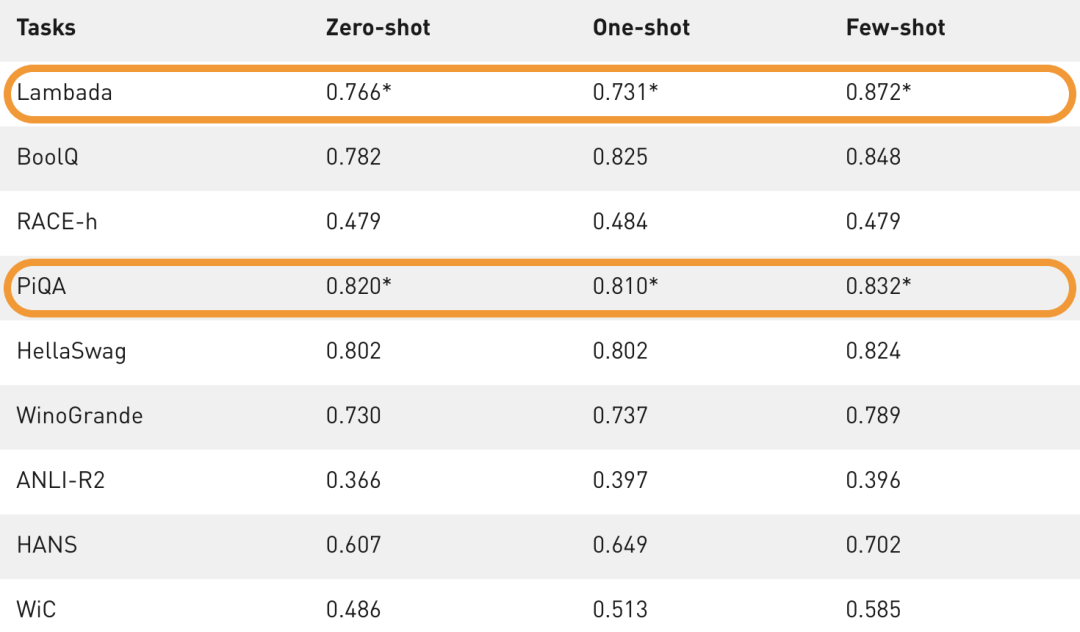
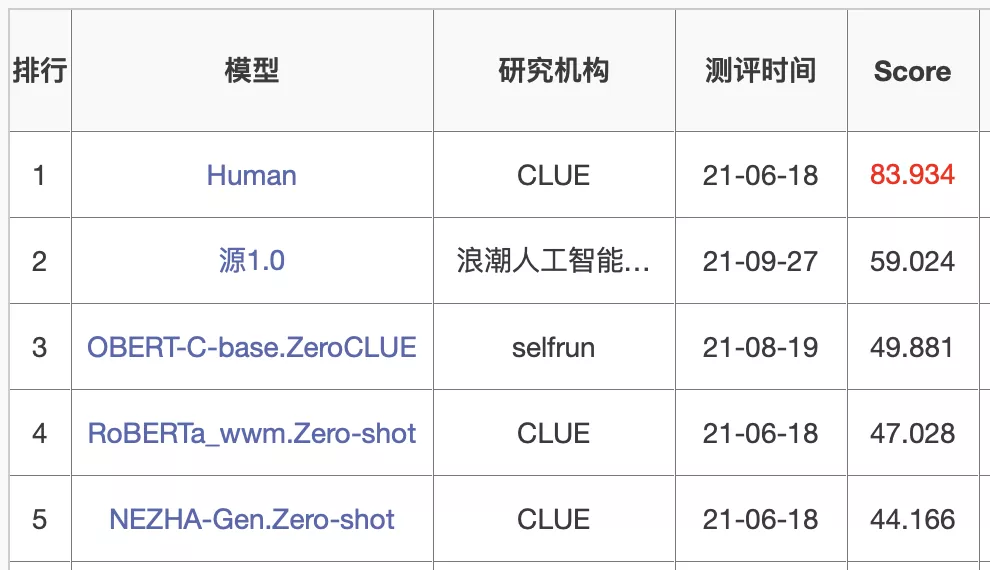
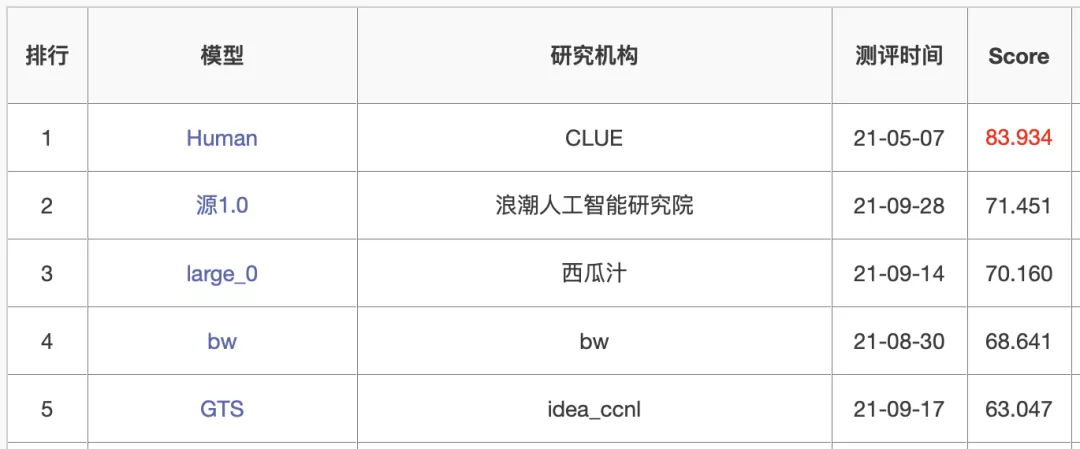
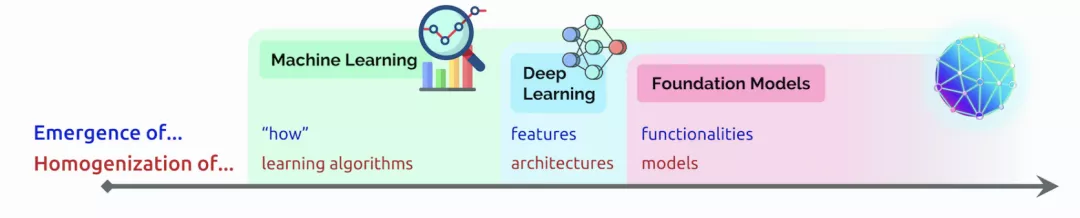
MT-NLG则使用了15个数据集,总共包含3390亿个token。最大的开源项目CLUECorpus2020只包含了100GB的高质量数据集。https://github.com/CLUEbenchmark/CLUECorpus2020为了获得高质量的数据集, 「源1.0」的团队开发了一套大数据过滤系统 Massive Data Filtering System (MDFS),其中包括数据收集、粗略过滤、精细过滤三部分。数据主要来自Common Crawl、搜狗新闻(SogouN)、搜狗互联网语料库版本(SogouT,2016)、百科数据和书籍数据。在对原始语料进行粗筛选之后,团队又训练了一个基于Bert的模型来对高质量、低质量和广告内容进行分类,并辅以人工筛查。最后终于得到了5TB高质量中文数据集,其中包括近5年中文互联网的全部内容和近2000亿个词。有了数据集,也构建好了模型,现在就可以来谈一谈训练了。对于最新的「MT-NLG」,由560台DGX A100服务器提供动力,其中每个DGX A100都有8个NVIDIA A100 80GB张量核心图形处理器,也就是4480块A100显卡。每个GPU的算力直接飙到每秒113万亿次浮点运算。GPT-3的训练则是在超过28.5万个CPU核心以及超过1万个GPU上完成,GPU在训练过程中达到每秒2733亿次浮点运算。而「源1.0」只用了2128张GPU,并在短短的16天就完成了训练。「源1.0」的团队创新性地采用了张量并行、流水线并行和数据并行的三维并行策略。在张量并行策略中,模型的层在节点内的设备之间进行划分。Transformer结构在进行前向计算和反向传播时,注意力层和多层感知机 层的张量将会被按行或列进行拆分。输入端的张量首先会发送给每个加速器,在加速器中各张量独立进行前向计算。流水线并行将 LM 的层序列在多个节点之间进行分割,以解决存储空间不足的问题。每个节点都是流水线中的一个阶段,它接受前一阶段的输出并将结果过发送到下一阶段。如果前一个相邻节点的输出尚未就绪,则当前节点将处于空闲状态。采用数据并行时,全局批次规模按照流水线分组进行分割。每个流水线组都包含模型的一个副本,数据在组内按照局部批次规模送入模型副本。从结果上看,「源1.0」的训练共消耗约4095PD(PetaFlop/s-day),相较于「GPT-3」的3640PD,计算效率得到大幅提升。原因很简单,人类可以仅通过一个或几个示例就可以轻松地建立对新事物的认知,而机器学习算法通常需要成千上万个有监督样本来保证其泛化能力。而是否拥有从少量样本中学习和概括的能力,是将人工智能和人类智能进行区分的明显分界点。其中,零样本学习更是可以判断计算机能否具备人类的推理和知识迁移能力,无需任何训练数据就能够识别出一个从未见过的新事物。简单来说,零样本学习,就是训练的分类器不仅仅能够识别出训练集中已有的数据类别,还可以对于来自未见过的类别的数据进行区分;小样本学习,就是使用远小于深度学习所需要的数据样本量,达到接近甚至超越大数据深度学习的效果。不管是「GPT-3」还是「MT-NLG」,都在强调自己在这两方面的学习能力。当然,二者的区别在于,作为前任SOTA的「GPT-3」被「MT-NLG」以微弱的优势「干」掉了。 「GPT-3」在LAMBDA和PIQA测试集上取得的成绩「MT-NLG」在LAMBDA和PIQA测试集上取得的成绩「源1.0」虽然没有办法直接和二者进行对比,不过在中文最大规模的语言评估基准——CLUE上的成绩还是很有说服力的。在ZeroCLUE零样本学习榜单中,「源1.0」以超越业界最佳成绩18.3%的绝对优势遥遥领先。在文献分类、新闻分类,商品分类、原生中文推理、成语阅读理解填空、名词代词关系6项任务中获得冠军。在FewCLUE小样本学习榜单中,「源1.0」获得了文献分类、商品分类、文献摘要识别、名词代词关系等4项任务的冠军。刷榜终究是刷榜,虽然成绩很好,但实战起来还是很容易被人类「一眼看穿」。不过,其实从成绩单上的分数也能看出,不管是英文还是中文的模型,和人类比起来差距还是很大的。尤其是在情感理解和话题表达方面这类没有特定规则的情景下,比如作诗、写故事等等。AI巨头竞相追逐模型规模的新高度,这自然带来一个灵魂之问:他们在探索什么?当前,语言模型的训练已经从「大炼模型」走向「炼大模型」的阶段,巨量模型也成为业界关注的焦点。近日,Percy Liang,李飞飞等一百多位学者在发表的 200 多页的研究综述 On the Opportunities and Risk of Foundation Models 中阐述了巨量模型的意义在于「突现和均质」。论文中,他们给这种大模型取了一个名字,叫基础模型(foundation model),其在NLP领域表现出了强大的通用性和适用性。 从ELMo到Bert再到之后的GPT-3等一系列模型,预训练模型的性能一直在提升,这是一个非常强的证据。而现在威震天-图灵的参数量是5300多亿,可见,当前模型的参数规模可能也没有达到通用人工智能所要求的水平。那么,构建越来越大的模型,真的能够通向通用人工智能(AGI)吗?OpenAI 的无监督转化语言模型 GPT-3,展现出了从海量未标记数据中学习,且不限于某一特定任务的「通用」能力。因此让许多人看到了基于大规模预训练模型探索通用人工智能的可能。坦白讲,我们开始对大模型认识不太清晰的时候,认为它只是用来作首诗,对个对子,但其实这些并不是大模型的魅力所在。大模型真正的魅力在于「不可知」,而在于对未来的一个探讨。一位清华教授曾表示,GPT-3已经越来越接近人类水平,但它有一个「阿喀琉斯之踵」。GPT这说明,GPT-3很聪明,但它仍有一些认知局限——没有常识。自然语言处理研究员、康奈尔大学数据科学家Maria Antoniak表示,「谈到自然语言,更大的模型是否是正确的方法是一个悬而未决的问题。虽然目前一些最好的基准性能得分来自大型数据集和模型,但是将大量数据倾倒到模型中的回报是不确定的。」这足以证明,对大模型进行探索是一个持续不断的过程。全球AI巨头争的是,探索的是大模型未知领域的「处女地」,可以说是面向通用智能最高阶智能的探索。其实,不仅仅是科学探索,它必然会产生一种催化效应,探索的成果也会带动CV、OCR、语音等领域的发展。这对于人类来说是一直探索的哲学问题,那么机器会如何回答?「源1.0」便是一个非常好的开始,但未来的路还很长。
参考资料:
https://arxiv.org/pdf/2005.14165.pdf
https://arxiv.org/pdf/2004.05986.pdf
https://arxiv.org/pdf/2110.04725.pdf
https://developer.nvidia.com/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/
https://easyai.tech/ai-definition/tokenization/
https://lifearchitect.ai/models/#contents