GO、GSEA富集分析一网打进
GO、KEGG、GSEA富集分析,已经注释好的数据,自己注释的数据,都在这里
NGS系列文章包括NGS基础、转录组分析 (Nature重磅综述|关于RNA-seq你想知道的全在这)、ChIP-seq分析 (ChIP-seq基本分析流程)、单细胞测序分析 (重磅综述:三万字长文读懂单细胞RNA测序分析的最佳实践教程 (原理、代码和评述))、DNA甲基化分析、重测序分析、GEO数据挖掘(典型医学设计实验GEO数据分析 (step-by-step) - Limma差异分析、火山图、功能富集)等内容。
富集分析是生物信息分析中快速了解目标基因或目标区域功能倾向性的最重要方法之一。其中代表性的计算方式有两种:
一是基于筛选的差异基因,采用超几何检验判断上调或下调基因在哪些GO或KEGG或其它定义的通路富集。假设背景基因数目为m,背景基因中某一通路pathway中注释的基因有n个;上调基因有k个,上调基因中落于通路pathway的数目为l。简单来讲就是比较l/k是否显著高于n/m,即上调基因中落在通路pathway的比例是否高于背景基因在这一通路的比例。(实际计算时,是算的odds ratio的差异,l/(k-l) vs (n-l)/(m-k-n+l))。这就是常说的GO富集分析或KEGG富集分析,可以做的工具很多,GOEAST是其中一个最好用的在线功能富集分析工具,数据库更新实时,操作简单,并且可以直接用之前介绍的方法绘制DotPlot。
另一种方式是不硬筛选差异基因,而是对其根据表达量或与表型的相关度排序,然后判断对应的基因集是否倾向于落在有序列表的顶部或底部,从而判断基因集合对表型差异的影响和筛选有影响的基因子集。这叫GSEA富集分析,注释信息可以是GO,KEGG,也可以是其它任何符合格式的信息。GSEA富集分析 - 界面操作详细讲述了GSEA分析的原理、可视化操作和结果解读 (一文掌握GSEA,超详细教程)。
R包clusterProfiler囊括了前面提到的两种富集分析方法。并且不只支持GO、KEGG数据库,还支持Disease Ontology、MsEH enrichment analysis、Reactome通路分析等。具体可见软件的文档页 https://guangchuangyu.github.io/clusterProfiler/。
这么强大的工具,学习起来的路子却不是一帆风顺,最开始的拦路虎是软件的安装,系统较老配合上软件包更新较快(作者勤快也是问题),导致经常安装的是旧版本,用起来会遇到不少坑。直到有了conda,安装再也不是问题。解决了动态库依赖后,可以在Github安装最新的开发版本。
另外一个是文档较少,在R终端,直接使用help命令查看到的使用提示信息较少,寥寥几句,看过总觉得不踏实。~在线文档页内容少、更新慢。这是最开始学习时遇到的问题,这次秉着负责的精神,又重新读了文档页,发觉不需要再写一遍了,内容挺全的,但有几个地方需要更新下。自己对着文档页核对了下之前写的程序,再补充几点。
GO富集分析
首先还是列一个完整的例子。输入最好是用ENTREZ ID,值比较固定,不建议使用GeneSymbol,容易匹配出问题 (Excel改变了你的基因名,30% 相关Nature文章受影响,NCBI也受波及)。
entrezID_text <- "4312
8318
10874
55143
55388
991
6280
2305
9493
1062
3868
4605
9833
9133
6279
10403
8685
597
7153
23397"
entrezID <- read.table(text=entrezID_text, header=F)
head(entrezID)V1
1 4312
2 8318
3 10874
4 55143
5 55388
6 991转换为向量
entrezID <- entrezID$V1
head(entrezID)[1] 4312 8318 10874 55143 55388 991# 这里的ENTREZ ID是从clusterProfiler里面提取是,是人的,
# 所以用了人的注释库, org.Hs.eg.db# 这个库半年左右更新一次,也有可能漏更新,还是自己准备数据的靠谱
library(org.Hs.eg.db)开始富集分析
# readable=T: 原文档无这个参数,使用的是setReadble函数
MF <- enrichGO(entrezID, "org.Hs.eg.db", ont = "MF", keytype = "ENTREZID",
pAdjustMethod = "BH", pvalueCutoff = 0.05,
qvalueCutoff = 0.1, readable=T)
head(summary(MF))
去除冗余度高的条目
(参考http://guangchuangyu.github.io/2015/10/use-simplify-to-remove-redundancy-of-enriched-go-terms/)
result <- simplify(MF, cutoff=0.7, by="p.adjust", select_fun=min)
# 去除前
dim(MF)
# [1] 367 9
# 去除后
dim(result)
[1] 142 9绘制泡泡图 (这里还有一个可以直接在线绘制泡泡图的网站:http://www.ehbio.com/ImageGP/)
dotplot(result, showCategory = 10)绘制网络图 (边的宽度代表两个富集的Term共有的基因数目,点大小代表条目内基因数目多少,颜色代表P-value,值越小越红;如果想改变网络布局,参考igraph文档)
enrichMap(result, vertex.label.cex=1.2, layout=igraph::layout.kamada.kawai)另外一种网络图由cnetplot函数获得,可以映射基因的表达量。
# geneList为一个vector,每个元素的名字为基因名,值为FoldChange,用于可视化点。
# > str(geneList)
# Named num [1:12495] 4.57 4.51 4.42 4.14 3.88 ... - attr(*, "names")= chr [1:12495] "4312" "8318" "10874" "55143" ...
# 这个geneList怎么获得的,会在后面的GSEA分析时提到
cnetplot(result, foldChange=geneList)自己尝试了下,展示的有些乱,需要调整字体和显示的条目多少。故盗图展示如下便于解释,基因与其被注释的条目连线,点的颜色代表表达变化,圈的大小代表对应注释内基因数目多少。
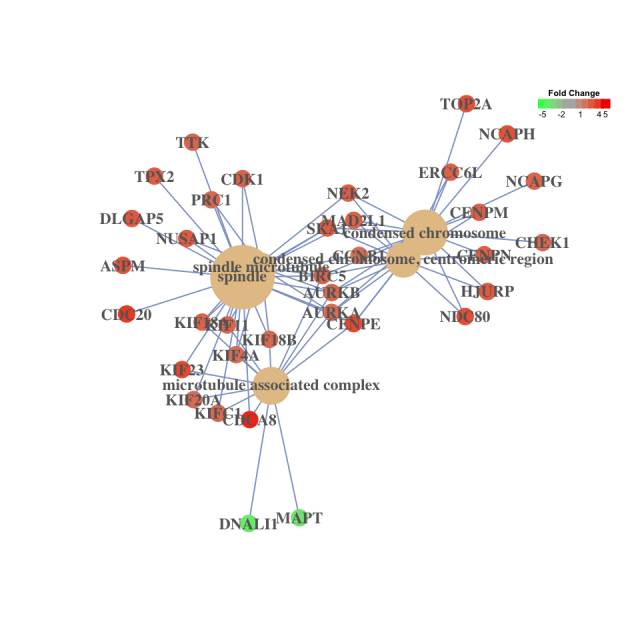 如果想自己调整图的布局,还是建议把输出结果转换为Cytoscape(点击查看视频教程)可以识别的两列表格形式(如下),再赋值不同的属性就可以了。
如果想自己调整图的布局,还是建议把输出结果转换为Cytoscape(点击查看视频教程)可以识别的两列表格形式(如下),再赋值不同的属性就可以了。
awk 'BEGIN{OFS=FS="\t"}{if(FNR==1) print "Gene\tTerm"; else {split($8,geneL,"/"); for(i in geneL) print geneL[i],$2}}' MF | head
Gene Term
PRDX6 cell adhesion molecule binding
MFGE8 cell adhesion molecule binding
FSCN1 cell adhesion molecule binding
ATXN2L cell adhesion molecule binding
YWHAZ cell adhesion molecule binding
CTNNA2 cell adhesion molecule binding
ADAM15 cell adhesion molecule binding
LDHA cell adhesion molecule binding
PKM cell adhesion molecule bindingKEGG富集分析
输入Gene ID的格式和类型与enrichGO一致。参考
http://guangchuangyu.github.io/2015/02/kegg-enrichment-analysis-with-latest-online-data-using-clusterprofiler/。
# clusterProfiler3.4.4版本是没有readable参数的,原文档有
kk <- enrichKEGG(entrezID, organism="hsa", pvalueCutoff=0.05, pAdjustMethod="BH",
qvalueCutoff=0.1)输出结果的格式和可视化方式与上面GO富集一致,不再赘述。
另外一个没有解决的问题是setReadable函数的使用 (用测试文档提供的数据集报出如下错误)
setReadable(kk, "org.Hs.eg.db")
Error in EXTID2NAME(OrgDb, genes, keytype) : keytype is not supported...
# 即便是如下操作也没有作用
a = bitr_kegg(names(geneList), fromType = 'ncbi-geneid', toType="kegg", organism="hsa")
# Warning message:
# In bitr_kegg(names(geneList), fromType = "ncbi-geneid", toType = "kegg", :
# 0.77% of input gene IDs are fail to map...
kk <- enrichKEGG(a$kegg, organism="hsa", keyType="kegg", pvalueCutoff=0.05, pAdjustMethod="BH",
qvalueCutoff=0.1)
setReadable(kk, org.Hs.eg.db, key)
# Error in EXTID2NAME(OrgDb, genes, keytype) : keytype is not supported...经过多次尝试发现,可以这么解决
setReadable(kk, org.Hs.eg.db, keytype="ENTREZID")为什么会有这个问题呢?setReadable中自动判断keytype的语句是
if (keytype == "auto") {
keytype <- x@keytype
if (keytype == "UNKNOWN") {
stop("can't determine keytype automatically; need to set 'keytype' explicitly...")
}
}根据富集结果中定义的keytype,也就是enrichKEGG函数中设定的keyType的值来定的。而setReadable不支持默认的keyType=kegg。
没有测试小鼠,可能需要设置不同的keytype值。
另外对拟南芥来说,分析之前需要先把Entrez ID转换为kegg再用上述命令做富集分析
entrezID <- bitr_kegg(entrezID, fromType='ncbi-geneid', toType='kegg', organism="ath")
kk <- enrichKEGG(entrezID$kegg, organism="ath", pvalueCutoff=0.05, pAdjustMethod="BH",
qvalueCutoff=0.1)
# 这个setreadble是可以转换成功的
result <- setReadable(kk, "org.At.tair.db", keytype="TAIR")GSEA分析
GSEA的解释和介绍见GSEA富集分析 - 界面操作。
注意读入的基因列表是要按照表达差异降序排列 (升序也可以,相当于样品做了对调)。这里排序方式可以是表达差异,也可以是其它方式,只要方便解释即可,即从上到下,或从前到后,基因对表型的贡献有一致的变化趋势就好。不同的排序参数和排序方式需要不同的对结果的解释。
id_with_fc = "ID;FC
4312;2
8318;3
10874;4
55143;5
55388;6
991;7"
id_with_fc <- read.table(text=id_with_fc, header=T, sep=";")
id_with_fc2 <- id_with_fc[,2]
names(id_with_fc2) <- id_with_fc[,1]
# 排序是必须的,记住排序方式
id_with_fc2 <- sort(id_with_fc2, decreasing=T)
gsecc <- gseGO(geneList=id_with_fc2, ont="CC", OrgDb=org.Hs.eg.db, verbose=F)
# 昨天测试了其它数据,参数无问题。这里没有实际运行,盗用数据,每列的解释见本段开头的文章
head(as.data.frame(gsecc))
## ID Description setSize
## GO:0031982 GO:0031982 vesicle 2880
## GO:0031988 GO:0031988 membrane-bounded vesicle 2791
## GO:0005576 GO:0005576 extracellular region 3296
## GO:0065010 GO:0065010 extracellular membrane-bounded organelle 2220
## GO:0070062 GO:0070062 extracellular exosome 2220
## GO:0044421 GO:0044421 extracellular region part 2941
## enrichmentScore NES pvalue p.adjust qvalues
## GO:0031982 -0.2561837 -1.222689 0.001002004 0.03721229 0.02816364
## GO:0031988 -0.2572169 -1.226003 0.001007049 0.03721229 0.02816364
## GO:0005576 -0.2746489 -1.312485 0.001009082 0.03721229 0.02816364
## GO:0065010 -0.2570342 -1.222048 0.001013171 0.03721229 0.02816364
## GO:0070062 -0.2570342 -1.222048 0.001013171 0.03721229 0.02816364
## GO:0044421 -0.2744658 -1.310299 0.001014199 0.03721229 0.02816364
# 绘制GSEA图
gseaplot(gsecc, geneSetID="GO:0000779")自定义数据集分析
如果想用clusterProfiler的函数对自己注释的数据进行功能富集分析或GSEA分析,需要提供如下格式的注释数据。后续分析就类似了。
self_anno <- "ont;gene
KEGG_GLYCOLYSIS_GLUCONEOGENESIS;gene1
KEGG_GLYCOLYSIS_GLUCONEOGENESIS;gene2
KEGG_GLYCOLYSIS_GLUCONEOGENESIS;gene3
KEGG_GLYCOLYSIS;gene1
KEGG_GLYCOLYSIS;gene4
KEGG_CYP;gene5"
self_anno <- read.table(text=self_anno, header=T, sep=";", quote="")
# 没具体看代码怎么写的,保险期间,设置跟示例一样的列名字
colnames(self_anno) <- c("ont", "gene")
geneL <- c("gene1", "gene2", "gene4")
# self_enrich与之前enrichGO的输出结果格式一致
self_enrich <- enricher(geneL, TERM2GENE=self_anno)
# self_gsea与之前gseGO的输出结果格式一致
self_gsea <- GSEA(geneL, TERM2GENE=self_anno, verbose=F)Reference
https://guangchuangyu.github.io/clusterProfiler/
http://guangchuangyu.github.io/2016/01/go-analysis-using-clusterprofiler/
http://igraph.org/c/doc/igraph-Layout.html
你可能还想看
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集