
2020 AI 研究大盘点!这些大牛的论文你都看过吗?

极市导读
AI发展日新月异,但又具有时代性!本文介绍了一些2020年那些有趣且重要的AI研究工作,涵盖了nlp, cv等多个AI领域。快来看看哪些番你还没补!>>加入极市CV技术交流群,走在计算机视觉的最前沿
人工智能领域的发展逐渐迅猛,在各个分支领域上不止两开花!
但每年研究关注的内容都有所变化,有学者整理了2020年中最重要的、最有意思的人工智能相关论文,其中人工智能伦理 、模型偏见等都受到了比以往更多的重视。
目前这项分享在Reddit上已经获得了近100赞,网友纷纷留言「无价之宝」,「感谢楼主」。
快看看下面哪些论文你还没有读过,赶紧来补番,下面选取10项工作在文中作简单介绍,每份工作都有保姆级教程,包教包会!

1、YOLOv4
该算法的主要目标是制作一个有更高精度、更快速度的目标检测器(object detector)。

通常一个目标检测器的模型架构由几个组件组成:首先是输入(图像),然后是骨干,以此图像作为输入,使用深层神经网络提取特征映射。
最后使用像 YOLO 或 SSD 这样的对象检测器来做出并处理这些预测。
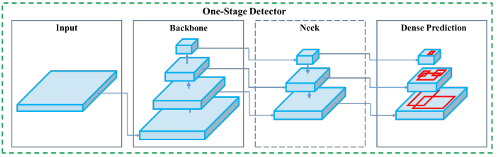
YOLOv4 引入了一种新的数据增强方法,称为马赛克和自我对抗训练。

与以前的版本和其他对象检测器相比,在多种 GPU 体系结构上进行了测试,比如 Maxwell,Pascal 和 Volta,YOLOv4在速度和性能方面都有了显著的提升。
对于诸如自动驾驶汽车、扑克牌作弊检测等多个需要进行实时目标检测的领域来说,YOLOv4是一个巨大的改进。
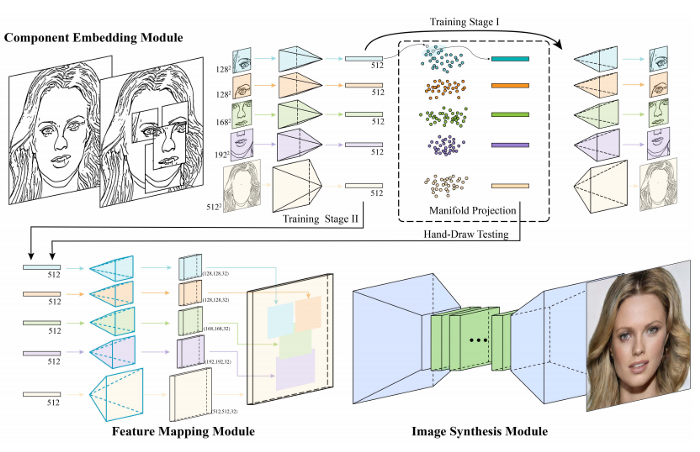
2、DeepFaceDrawing:根据粗糙的人脸图像,甚至不完整的草图来生成高品质的人脸图像。

这个模型的关键思想是隐式模拟合理的人脸图像的形状空间,并在这个空间合成一个人脸图像,以逼近输入的草图,所以系统能够允许用户在很少或根本没有从粗糙或甚至不完整的徒手草图生产高质量的人脸图像的模式中训练。
该方法输入笔画时忠实地复述用户的意图,这更像是一种软约束来指导图像合成,因此即使是从这些粗糙的草图也能够产生高质量的人脸图像。
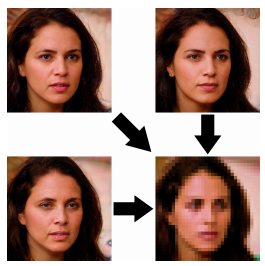
3、PULSE算法:把一张超低分辨率的16x16图像变成一张1080p高清晰度的人脸。
还在为拍的照片糊了而感到后悔吗?PULSE的目标是在一组合理的解决方案中生成逼真的图像。
这意味着他们想要依赖于一个真实的图像是现实的,其缩小版本将看起来与原来的低分辨率图像相同。而不是必须直接从低分辨率图像猜测。
因此,他们引入了一种新的自监督技术,遍历高分辨率的自然图像流形,寻找图像向下缩放到原始的低分辨率图像。
4、Unsupervised Translation of Programming Languages
由Facebook AI提出的一种编程语言之间的无监督转换方法,这种新的模式可以把代码从一种编程语言以无监督的形式转换到另一门语言上,例如它可以将 Python 函数转换为 C++ 函数,反之亦然。
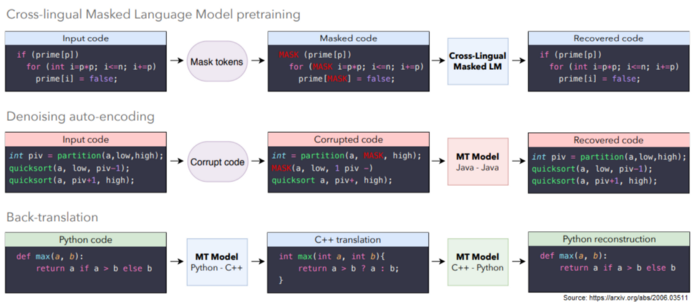
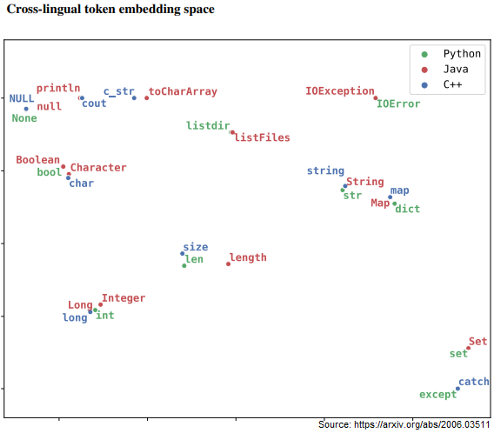
训练数据来自开源的GitHub项目,并且主要训练C++, Java, Python之间的函数变换。
基本架构是一个seq2seq的模型,该模型由一个编码器和一个具有Transformer结构的解码器组成。以无监督的方式专门针对函数进行训练。
在训练结束后,相似的词在表示空间中有更近的距离。
5、GPT-3: Language Models are few-shot learners
GPT-3是OpenAI开发的一个新的文本生成程序。该模型经过预训练后参数即固定。
他们在1750亿个参数的5万亿个单词的数据集上训练GPT-3,这个参数量是以前非稀疏语言模型的10倍,所以这个模型就不再需要微调了,只有few-shot示例通过与模型的文本交互来指定。
例如,在翻译任务中,只给定一个英语句子及其法语翻译。
few-shot的工作原理是给出一定数量的上下文和完成示例(completion),然后给定一个待定的上下文示例,预期模型将在不更改模型参数的情况下提供补全。
该模型甚至可以通过直接针对特定任务进行微调达到现有sota模型的效果。
总之,GPT-3的效果很好,因为它的记忆中几乎包含了人类在互联网上发布的所有文本。
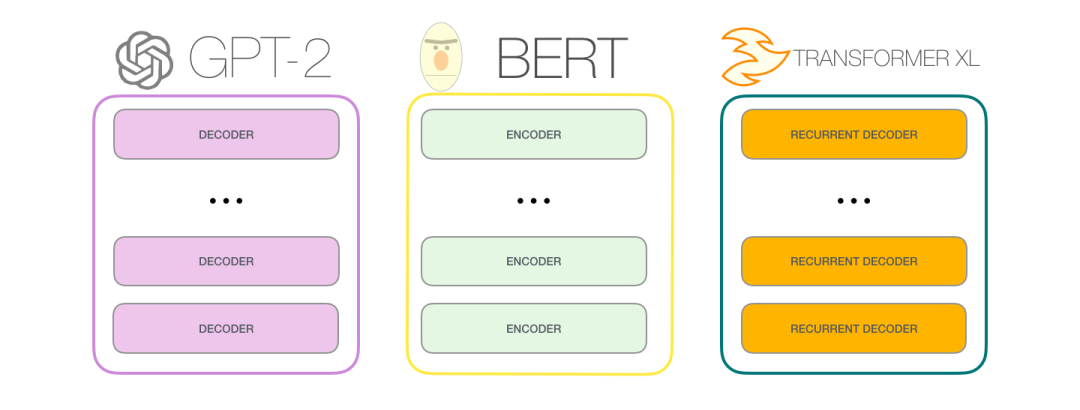
6、Image GPT — Generative Pretraining from Pixels
在之前Gmail展示的新功能中,一个最有趣的能力就是可以根据已经写的邮件内容来推测剩下的连贯文本。
OpenAI提出的Image GPT就是根据不完全的图像,来预测剩余的像素,而不考虑二维图像结构的知识。
他们想知道一个主要用于自然语言处理的架构是否可以与图片一起「重建」图像。就像Gmail预测你信息的结尾一样。

他们使用了的模型是Transformers双向编码器表示(BERT),Google开发的自然语言处理预训练模型。
应用GPT-2序列架构预测像素而不是语言标记。
这两个模型,BERT和GPT-2是领域不可知的,这意味着它们可以直接应用于任何形式的一维序列,例如像素序列,而不是单词和字母。
他们发现该模型甚至可以理解二维图像的特征,比如物体的外观和类别!
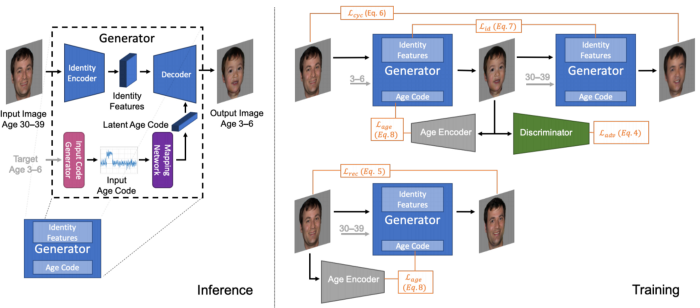
7、Lifespan Age Transformation Synthesis
来自 Adobe 研究所的一组研究人员开发了一种新的技术,用于年龄转换合成,这种技术仅仅基于人的一张照片。它可以从你发送的任何图片生成不同年龄段的照片。

他们同样使用GAN模型,但做了一些修改,他们称他们的新方法为「多域图像到图像生成对抗网络」。
它基本上是学习代表连续双向老化过程的潜在空间模型。这意味着它学习如何表现一个特定的人的图片,无论是年长的还是年轻的。
主要目标是了解头部形状随时间的变形,而目前的方法往往都忽略了这一点。当然,这不是唯一的挑战,他们还需要了解不同年龄段的外貌变化,这不是一项容易的任务。
由于没有数据集可以为我们提供同一个人在不同年龄的多张照片,所以无法使用监督学习来完成这项任务。
否则的话他们可以获得所有这些照片,并对照片上的人的性别和年龄进行注释,从而使任务实现更简单。
8、DeOldify:对旧的黑白照片进行上色,目前SOTA的黑白图像着色方式,并且也是开源的。

主要模型同样是GAN来完成。
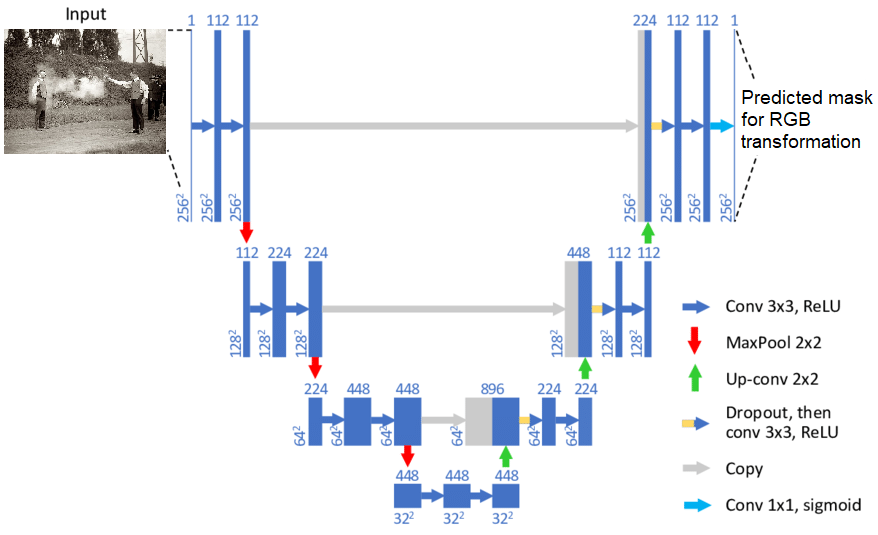
生成器的训练是通过像常规深度网络的架构(如ResNet),由于已经预训练过了,所以在训练完整的GAN架构之前,该模型已经非常擅长对图像进行着色。
然后,只需对这种景点的生成器判别器进行少量训练,即可优化生成图片的“真实感”。
高斯噪声还随机应用于图像中,以在训练期间生成假噪声。
9、Stylized Neural Painting:风格化神经绘画

图像到图像的翻译是一个非常有趣的任务,最近主要涉及到GANs和风格转换。当前最先进的方法,如pix2pix网络或CycleGANs,都使用GANs。
它们在这样的应用中表现效果非常好,因为这里的目标是将一幅图片转换为另一幅图片,同时保留其属性,并且只更改图像的整体样式。
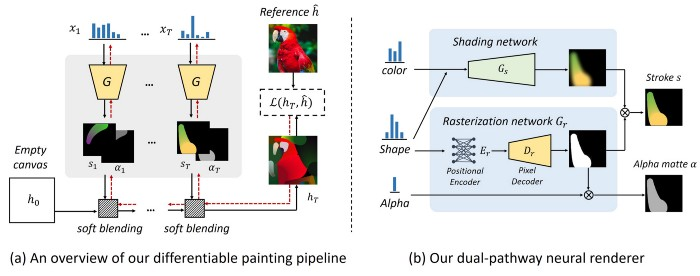
研究人员在一个空画布上开始上图中的过程(a)。然后使用两个生成器网络绘制真实的笔划向量,也称之为「双路径神经渲染器」。重复这个过程直到我们得到最终结果。
过程(b)展示了这些笔划是如何生成的,以及网络如何知道它们看起来是否真实(b)。
10、Neural Re-Rendering of Humans from a Single Image
这篇文章是关于Facebook Reality Labs的一篇新论文,该论文将在2020年欧洲计算机视觉会议(ECCV)上发表。
该算法将身体姿势和形状表示为一个参数化网格(parametric mesh),该网格可以从单个图像重建,并且很容易恢复。
给定一个人的图像,他们能够创建从另一个输入图像中获得的不同姿势或穿着不同服装的人的合成图像。

大多数方法使用基于颜色的UV纹理贴图。其中,对于特征贴图的每个纹理像素,指定源图像中的对应像素坐标。
然后使用该对应贴图来估计公共曲面UV系统上输入图像和目标图像之间的颜色纹理。
而Facebook的新技术的主要区别在于,他们没有使用这种基于颜色的UV纹理贴图,而是使用学习过的高维UV纹理贴图对外观进行编码。
这是一种获取照片中姿势、视点、个人身份和服装样式之间外观变化的更多细节的方法。
除了上述十篇文章外,作者总共总结了28篇有趣的AI研究工作,完整的列表可以在https://github.com/louisfb01/Best_AI_paper_2020中找到。

参考资料:
https://github.com/louisfb01/Best_AI_paper_2020
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
