
springboot第32集:redis系统-android系统-Nacos Server
Error parsing HTTP request header HTTP method names must be tokens
检查发送HTTP请求的客户端代码,确保方法名中不包含非法字符。通常情况下,HTTP请求的方法名应该是简单的标识符,例如"GET"、"POST"、"PUT"等。
如果你使用的是浏览器发送HTTP请求(例如使用JavaScript中的Fetch或XMLHttpRequest),请检查你的代码中是否正确指定了HTTP方法名,并且没有包含非法字符。
and: SQL中的逻辑运算符,用于连接多个条件,表示所有条件必须同时满足。 示例:SELECT * FROM users WHERE age > 18 AND gender = 'male';
extractvalue: XML类型的SQL函数,用于从XML文档中提取特定值。 示例:SELECT EXTRACTVALUE(xml_column, '/path/to/node') FROM table;注解:由于容易导致XPath注入攻击,已被弃用。
updatexml: XML类型的SQL函数,用于在XML文档中更新指定的节点值。 示例:UPDATE table SET xml_column = UPDATEXML(xml_column, '/path/to/node', 'new_value') WHERE id = 1;注解:容易导致XPath注入攻击,已被弃用。
exec: SQL Server中的命令,用于执行存储过程或批处理命令。 示例:EXEC sp_who;注解:容易导致SQL注入攻击,已被弃用。
insert: SQL中的关键字,用于向数据库表中插入新的数据。 示例:INSERT INTO users (name, age) VALUES ('John Doe', 25);
select: SQL中的关键字,用于从数据库表中查询数据。 示例:SELECT * FROM products WHERE category = 'Electronics';
delete: SQL中的关键字,用于从数据库表中删除数据。 示例:DELETE FROM users WHERE status = 'inactive';
update: SQL中的关键字,用于更新数据库表中的数据。 示例:UPDATE employees SET salary = 50000 WHERE department = 'IT';
drop: SQL中的关键字,用于删除数据库表或其他数据库对象。 示例:DROP TABLE users;
count: SQL中的聚合函数,用于统计满足条件的记录数量。 示例:SELECT COUNT(*) FROM orders WHERE status = 'completed';
chr: SQL中的函数,用于返回指定编码的字符。 示例:SELECT CHR(65); -- 返回 'A'
mid: SQL Server中的函数,用于返回字符串的子串。 示例:SELECT MID('Hello, World!', 1, 5); -- 返回 'Hello'
master: SQL Server中的系统数据库。 示例:USE master;
truncate: SQL中的关键字,用于快速删除表中的所有数据。 示例:TRUNCATE TABLE logs;
char: SQL中的函数,用于返回指定ASCII码对应的字符。 示例:SELECT CHAR(65); -- 返回 'A'
declare: SQL中的关键字,用于声明变量或游标。 示例:DECLARE @name VARCHAR(50);
or: SQL中的逻辑运算符,用于连接多个条件,表示任意一个条件满足即可。 示例:SELECT * FROM products WHERE category = 'Electronics' OR price > 500;
+: SQL中的算术运算符,用于加法运算。 示例:SELECT price + tax AS total FROM products;
user(): SQL中的函数,用于返回当前登录用户。 示例:SELECT user();
like: SQL中的条件运算符,用于模糊匹配字符串。 示例:SELECT * FROM products WHERE name LIKE '%apple%';
between: SQL中的条件运算符,用于指定范围内的条件。 示例:SELECT * FROM sales WHERE amount BETWEEN 1000 AND 5000;
in: SQL中的条件运算符,用于指定多个条件之一的匹配。 示例:SELECT * FROM customers WHERE country IN ('USA', 'Canada', 'UK');
not: SQL中的逻辑运算符,用于取反条件。 示例:SELECT * FROM products WHERE NOT category = 'Electronics';
join: SQL中用于连接多个表的操作,常见的有INNER JOIN、LEFT JOIN等。 示例:SELECT orders.order_id, customers.name FROM orders INNER JOIN customers ON orders.customer_id = customers.customer_id;
union: SQL中用于合并多个查询结果集的操作。 示例:SELECT name, email FROM customers WHERE country = 'USA' UNION SELECT name, email FROM customers WHERE country = 'Canada';
group by: SQL中用于对查询结果进行分组的操作。 示例:SELECT category, COUNT(*) AS total FROM products GROUP BY category;
having: SQL中用于在GROUP BY子句中添加条件过滤。 示例:SELECT category, COUNT(*) AS total FROM products GROUP BY category HAVING total > 10;
order by: SQL中用于对查询结果进行排序的操作。 示例:SELECT * FROM products ORDER BY price DESC;
as: SQL中用于为列或表起别名。 示例:SELECT id AS product_id, name AS product_name FROM products;
case: SQL中的条件语句,类似于编程语言中的switch语句。 示例:SELECT name, grade, CASE WHEN grade >= 60 THEN 'Pass' ELSE 'Fail' END AS result FROM students;
AND、OR:用于逻辑条件的连接,在查询条件中使用。 示例:SELECT * FROM employees WHERE age > 30 AND department = '销售部门';
INSERT:用于向数据库表中插入新的行。 示例:INSERT INTO employees (name, age, department, salary) VALUES ('John', 35, '销售部门', 2000);
UPDATE:用于更新数据库表中的行。 示例:UPDATE employees SET salary = 2200 WHERE department = '销售部门';
DELETE:用于从数据库表中删除行。 示例:DELETE FROM employees WHERE age > 60;
SELECT:用于从数据库表中检索数据。 示例:SELECT name, age, department FROM employees WHERE salary > 3000;
DROP:用于删除数据库对象,如表、视图等。 示例:DROP TABLE employees;
COUNT:用于统计满足条件的行数。 示例:SELECT COUNT(*) FROM employees WHERE department = '人事部门';
CHAR、MID、MASTER:用于字符串处理和其他一些特定的操作。 示例:SELECT * FROM employees WHERE name LIKE '%Smith%';
DECLARE:用于声明存储过程或变量。 示例:DECLARE @deptName VARCHAR(50) = '销售部门';
EXEC:用于执行存储过程或动态SQL语句。 示例:EXEC usp_GetEmployeeByID @empID = 1001;
-- 错误示例(容易受到SQL注入攻击)
const name = userInput;
const query = `SELECT * FROM employees WHERE name = '${name}';`;
-- 正确示例(使用参数化查询)
const name = userInput;
const query = `SELECT * FROM employees WHERE name = ?;`;
db.query(query, [name]);
Redis配置:检查服务器上的Redis配置,确保其设置正确。可能存在与数据逐出策略或TTL(生存时间)相关的设置,导致缓存在一定时间后被清除。
Redis数据持久性:在某些情况下,Redis可能被配置为使用非持久性存储模式,这意味着数据仅保存在内存中而不保存到磁盘。这可能会导致服务器重新启动后数据丢失。
多个实例:如果您的应用程序在多个服务器实例上运行(负载均衡环境),而Redis缓存在它们之间没有共享,每个实例可能有自己的缓存,导致不一致的行为。
内存限制:服务器可能有限的可用内存,如果Redis缓存大小超过了限制,可能会导致数据逐出或清空。
缓存过期:检查存储在Redis缓存中的令牌是否设置了特定的到期时间(TTL)。如果令牌过期得太快,可能会导致缓存被清除。
user www www;: 指定Nginx运行的用户和用户组,通常设置为www用户和www组。
worker_processes auto;: 设置Nginx的工作进程数,auto表示根据系统的CPU核心数自动设置。
error_log /www/wwwlogs/nginx_error.log crit;: 指定错误日志文件的路径和日志等级,这里设置为crit表示只记录严重错误。
pid /www/server/nginx/logs/nginx.pid;: 指定Nginx主进程的PID文件路径。
worker_rlimit_nofile 51200;: 设置每个Nginx工作进程允许打开的最大文件数。
stream { ... }: 定义一个stream块,用于配置TCP/UDP代理和负载均衡。
events { ... }: 定义一个events块,用于配置Nginx的事件处理器,例如使用epoll作为事件驱动机制。
http { ... }: 定义一个http块,用于配置HTTP服务器的行为和虚拟主机。
include mime.types;: 包含mime.types文件,该文件定义了MIME类型与文件扩展名的映射关系。
include proxy.conf;: 包含proxy.conf文件,该文件用于配置Nginx的反向代理行为。
default_type application/octet-stream;: 设置默认MIME类型为application/octet-stream。
server_names_hash_bucket_size 512;: 设置服务器名称哈希桶的大小。
client_header_buffer_size 32k;: 设置接收HTTP请求头的缓冲区大小。
large_client_header_buffers 4 32k;: 设置接收大型HTTP请求头的缓冲区大小。
client_max_body_size 50m;: 设置客户端请求体的最大大小为50MB。
sendfile on;: 启用sendfile机制,提高文件传输性能。
tcp_nopush on;: 启用tcp_nopush选项,减少TCP传输的延迟。
keepalive_timeout 60;: 设置HTTP keep-alive连接的超时时间为60秒。
tcp_nodelay on;: 启用tcp_nodelay选项,提高TCP传输性能。
fastcgi_...: 一系列FastCGI相关的配置,用于设置FastCGI连接和缓冲区的参数。
gzip ...: 一系列Gzip相关的配置,用于启用Gzip压缩和设置压缩参数。
limit_conn_zone ...: 设置连接数限制的相关配置。
server_tokens off;: 禁止在响应头中显示Nginx版本号。
access_log off;: 禁用访问日志记录。
server { ... }: 定义一个虚拟主机,监听在端口888,用于处理名为phpmyadmin的请求。
location ~ /tmp/ { ... }: 匹配以/tmp/开头的URL,当请求该URL时返回403禁止访问。
location ~ .*.(gif|jpg|jpeg|png|bmp|swf)$ { ... }: 匹配以.gif、.jpg、.jpeg、.png或.bmp结尾的URL,设置其过期时间为30天。
location ~ .*.(js|css)?$ { ... }: 匹配以.js或.css结尾的URL,设置其过期时间为12小时。
location ~ /.: 匹配以.开头的URL,拒绝访问。
access_log /www/wwwlogs/access.log;: 设置访问日志文件的路径。
redis:
# 地址,根据实际情况填写
host: localhost
# 端口,默认为6379,根据实际情况填写
port: 6379
# 数据库索引,根据实际情况填写
database: 0
# 密码,如果设置了Redis密码访问限制,填写正确的密码,否则留空
password:
# 连接超时时间,根据实际网络状况和请求响应时间调整,10秒可能需要调整
timeout: 30s
lettuce:
pool:
# 连接池中的最小空闲连接,根据服务器并发连接数需求调整
min-idle: 10
# 连接池中的最大空闲连接,根据服务器并发连接数需求调整
max-idle: 50
# 连接池的最大数据库连接数,根据服务器并发连接数需求调整
max-active: 100
# 连接池最大阻塞等待时间(使用负值表示没有限制),根据服务器响应速度调整
max-wait: 500ms
# 开启RDB快照持久化,每900秒(15分钟)至少1个修改则持久化
save 900 1
# 开启AOF日志持久化,每秒fsync
appendonly yes
appendfsync everysec
# 指定RDB快照和AOF日志的存储位置,根据实际磁盘空间和目录权限调整
dir /path/to/redis-data/
# 开启tcp-keepalive,防止长时间空闲连接被关闭
tcp-keepalive 60
# 关闭Redis的服务器信息,避免泄露服务器信息
databases 16
# 关闭Redis的服务器信息,避免泄露服务器信息
server_tokens no
# 关闭访问日志,避免记录敏感信息
access_log off
# 如果服务器有足够的内存,开启内存碎片整理
activedefrag yes

image.png
AOF(Append-Only File)持久化是Redis一种持久化数据的机制,它可以在Redis服务器运行期间将写命令追加到AOF文件中,以保证数据在服务器重启后的持久性。
具体来说,以下两个配置参数与AOF持久化相关:
appendonly: 这个配置项用于开启(yes)或关闭(no)AOF持久化。如果设置为yes,表示开启AOF持久化,Redis会将每个写命令追加到AOF文件中,以记录所有数据更改操作。如果设置为no,则关闭AOF持久化,Redis将不会将写命令追加到AOF文件,从而不记录数据更改操作。
appendfsync: 这个配置项用于设置AOF文件刷新(sync)的频率。当AOF持久化开启时,Redis会将写命令追加到AOF文件中,但数据并不立即写入磁盘,而是先存放在操作系统的缓存中,然后根据appendfsync的设置进行刷新到磁盘。可选的值有以下三种:
always: 表示每个写命令都立即强制刷新到磁盘,保证数据的完全持久化。这是最安全的选项,但也会导致IO性能较差。
everysec: 表示每秒钟执行一次刷新操作,将缓存中的数据刷入磁盘。这在很多场景下是一个不错的折中方案,可以保证较好的持久性,同时又不会对IO性能造成太大影响。
no: 表示不进行强制刷新,由操作系统自行决定刷新时机。这种配置可以获得最好的性能,但在服务器发生故障时可能会有数据丢失的风险。
需要注意的是,如果关闭AOF持久化(appendonly设置为no),在Redis重启时可能会丢失从上次RDB快照以来的所有数据更改,因为写命令没有被记录在AOF文件中。因此,如果需要数据的持久性和较高的数据安全性,建议开启AOF持久化,并根据业务需求选择合适的appendfsync选项。如果服务器的磁盘空间较小,可以选择everysec,如果对数据持久性要求非常高,可以选择always,但要注意对IO性能的影响。
// 心跳消息
const heartbeatMessage = 'ping'
// 定时发送心跳消息
setInterval(() => {
socket.value.send(heartbeatMessage)
}, 5000000000)
// 监听消息事件
socket.value.onmessage = (event: { data: any }) => {
const message = event.data
if (message === heartbeatMessage) {
// 收到心跳消息,做相应处理
} else {
// 处理其他消息
}
}
// 为了保持 WebSocket 连接的活跃状态,可以使用心跳机制定期发送心跳消息。
Installed Build Tools revision 33.0.1 is corrupted. Remove and install again using the SDK Manager.
使用了el-row和el-col来构建网格布局。el-row代表一行,el-col代表网格列,通过在el-col上设置不同的响应式属性(如:md和:sm)来控制列在不同屏幕尺寸下的宽度。
installed build tools revision 31.0.0 is corrupted. remove and install again using the sdk manager
这个错误表明安装的 Build Tools 版本 31.0.0 是损坏的,需要使用 SDK Manager 删除并重新安装。
使用 SDK Manager 删除 Build Tools 的步骤如下:
打开 SDK Manager。
在左侧导航栏中选择 "SDK Tools"。
找到 "Android SDK Build-Tools",选择它并点击 "Uninstall" 按钮。
按照提示完成删除操作。
重新安装 Build Tools 的步骤如下:
打开 SDK Manager。
在左侧导航栏中选择 "SDK Tools"。
找到 "Android SDK Build-Tools",选择版本 31.0.0 并点击 "Apply" 按钮。
按照提示完成安装操作。
最后还需要配置环境变量,使系统可以找到这些工具。
完成以上操作后,应该能够解决 "installed build tools revision 31.0.0 is corrupted" 的错误。
服务注册与发现,配置中心,全链路监控,服务网关,负载均衡,熔断器等组件。
SpringCloud是基于SpringBoot提供的一套微服务解决方案,包括服务注册与发现,配置中心,全链路监控,服务网关,负载均衡,熔断器等组件。使用的组件包括 Eureka、Ribbon、Fegin、Hystrix、Zuul等。
Eureka 服务注册与发现
Ribbon和Feign负载均衡
Hystrix服务熔断
服务熔断
某个服务故障或者异常,类似现实世界中的“保险丝”,当某个异常条件被触发,直接熔断整个服务,而不是一直等到此服务超时。
服务降级
就是当某个服务熔断后,服务将不再被调用,此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值,这样做,虽然服务水平下降了,但好歹可用,比直接挂掉要强。

image.png
image.png
image.png

image.png

image.png

image.png
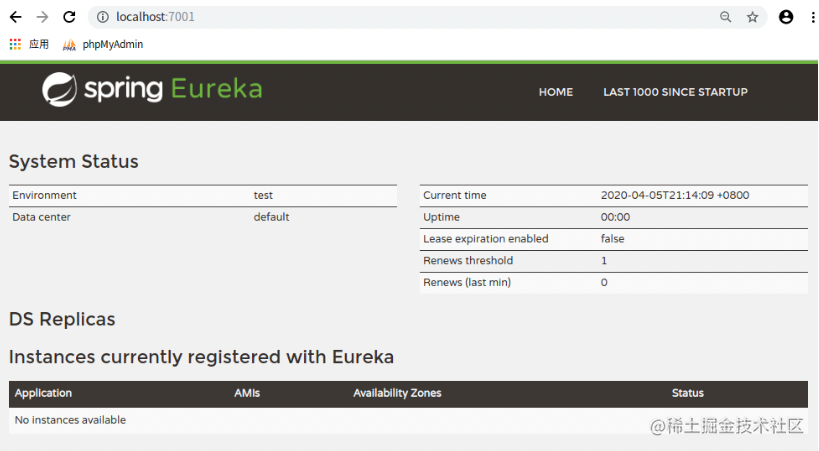
image.png
搭建Eureka Server集群
在本地的hosts文件中添加如下配置

image.png
image.png

image.png
微服务
Spring Cloud 是一个服务治理平台,是若干个框架的集合,提供了全套的分布式系统解决方案。包含了:服务注册与发现、配置中心、服务网关、智能路由、负载均衡、断路器、监控跟踪、分布式消息队列等等。
Nacos:阿里巴巴开源产品,一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
Sentinel:面向分布式服务架构的轻量级流量控制产品,把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
Dubbo:Apache Dubbo™ 是一款高性能 Java RPC 框架,用于实现服务通信。
Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
Spring Cloud Netflix Eureka:服务注册中心。
Spring Cloud Zookeeper:服务注册中心。
Spring Cloud Consul:服务注册和配置管理中心。
Spring Cloud Netflix Ribbon:客户端负载均衡。
Spring Cloud Netflix Hystrix:服务容错保护。
Spring Cloud Netflix Feign:声明式服务调用。
Spring Cloud OpenFeign(可替代 Feign):OpenFeign 是 Spring Cloud 在 Feign 的基础上支持了 Spring MVC 的注解,如 @RequesMapping等等。OpenFeign 的 @FeignClient 可以解析 SpringMVC 的 @RequestMapping 注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。
Spring Cloud Netflix Zuul:API 网关服务,过滤、安全、监控、限流、路由。
Spring Cloud Gateway(可替代 Zuul):Spring Cloud Gateway 是 Spring 官方基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等技术开发的网关,Spring Cloud Gateway 旨在为微服务架构提供一种简单而有效的统一的 API 路由管理方式。Spring Cloud Gateway 作为 Spring Cloud 生态系中的网关,目标是替代 Netflix Zuul,其不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/埋点,和限流等。
Spring Cloud Security:安全认证。
Spring Cloud Config:分布式配置中心。配置管理工具,支持使用 Git 存储配置内容,支持应用配置的外部化存储,支持客户端配置信息刷新、加解密配置内容等。
Spring Cloud Bus:事件、消息总线,用于在集群(例如,配置变化事件)中传播状态变化,可与 Spring Cloud Config 联合实现热部署。
Spring Cloud Stream:消息驱动微服务。
Spring Cloud Sleuth:分布式服务跟踪。
Spring Cloud Alibaba Nacos:阿里巴巴开源产品,一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
Spring Cloud Alibaba Sentinel:面向分布式服务架构的轻量级流量控制产品,把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Spring Cloud Alibaba RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
Spring Cloud Alibaba Dubbo:Apache Dubbo™ 是一款高性能 Java RPC 框架,用于实现服务通信。
Spring Cloud Alibaba Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
采用前后端分离的模式,微服务版本前端
后端采用Spring Boot、Spring Cloud & Alibaba。
注册中心、配置中心选型Nacos,权限认证使用Redis。
流量控制框架选型Sentinel,分布式事务选型Seata。
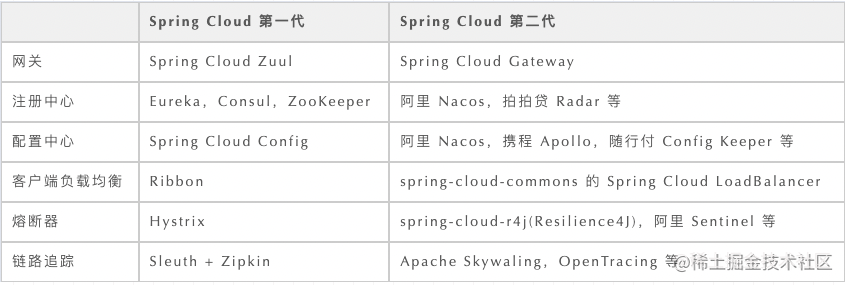
image.png
Nacos Server下载地址:
https://github.com/alibaba/nacos/releases
提供了zip 包,nacos-server-1.1.3.zip
上传到linux,并解压缩
1、上传到 /work,然后解压缩
cd /work
unzip nacos-server-1.1.3.zip
2、或者,从虚拟机的共享目录,复制到 /work目录,然后解压缩:
cp /vagrant/nacos-server-1.1.3.zip /work/
cd /work
unzip nacos-server-1.1.3.zip
如果unzip命令不存在,则安装unzip命令
yum install -y unzip zip
启动服务器
单机模式运行启动方法:
/work/nacos/bin/startup.sh -m standalone
如果在windows服务器,也就启动的命令不同而已
startup.cmd -m standalone
设置Nacos开机启动
编辑启动配置文件 /etc/rc.local,加入开机启动项,里面添加内容:
# 开机启动 Nacos
/usr/bin/su - root -c "/work/nacos/bin/startup.sh -m standalone"
访问后台
Nacos Server的后台访问地址:
http://192.168.233.128:8848/nacos
默认账号和密码为:nacos nacos
会用到的命令
停止 : /work/nacos/bin/shutdown.sh
启动 : /work/nacos/bin/startup.sh -m standalone
加群联系作者vx:xiaoda0423
仓库地址:https://github.com/webVueBlog/JavaGuideInterview