
Delta Lake 版本 | Delta Lake 1.0.0 发布,多项新特性重磅发布
赶在 Data + AI Summit 2021 之前,Delta Lake 1.0.0 重磅发布,这个版本是基于 Spark 3.1 的,带来了许多新特性。本文将结合 Michael Armbrust 大牛在 Data + AI Summit 2021 的演讲《Announcing Delta Lake 1.0》来介绍 Delta Lake 1.0.0 版本的一些重要的新特性。
下面是 Announcing Delta Lake 1.0 对应的视频:

Delta Lake 0.1 自 2019年4月开源以来,到现在已经2年了。每个版本都给我们带来了一些比较重要的特性。

目前,数砖的产品每天有超过1EB的数据是从 Delta Lake 上扫描的,占据所有数据扫描的75%,有超过3k的客户在生成环境上使用 Delta Lake。
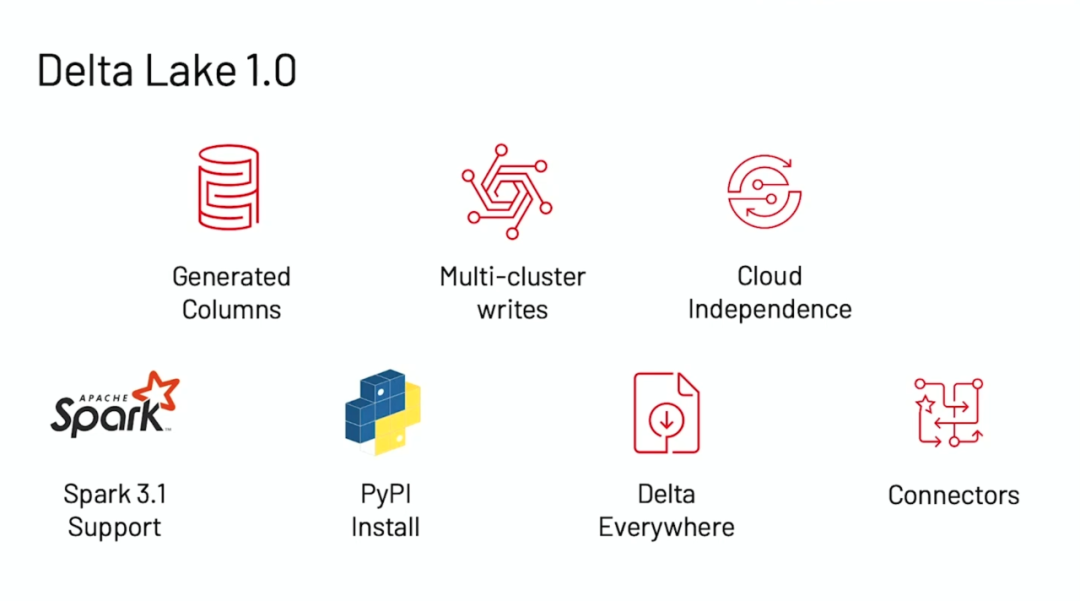
上面是 Delta Lake 1.0.0 版本比较重要的功能:
•列生成(Generated Columns)•支持多集群写(Multi cluster writes)•云存储独立(Cloud independence)•支持 Spark 3.1•支持 PyPi 安装
Generated Columns

在我们的业务中,我们业务可能只是生成时间戳的数据,比如上面的 eventTime,但是我们又想以分区的数据来组织数据,如果直接使用 eventTime 的话会导致分区过多的问题,一种办法是添加一个 eventDate 字段。这种办法可以解决问题,但是有以下几个问题:
•需要人工的添加字段;•需要在查询中指定这个过滤条件;•可能忘记加这个字段而出现错误或导致性能问题。
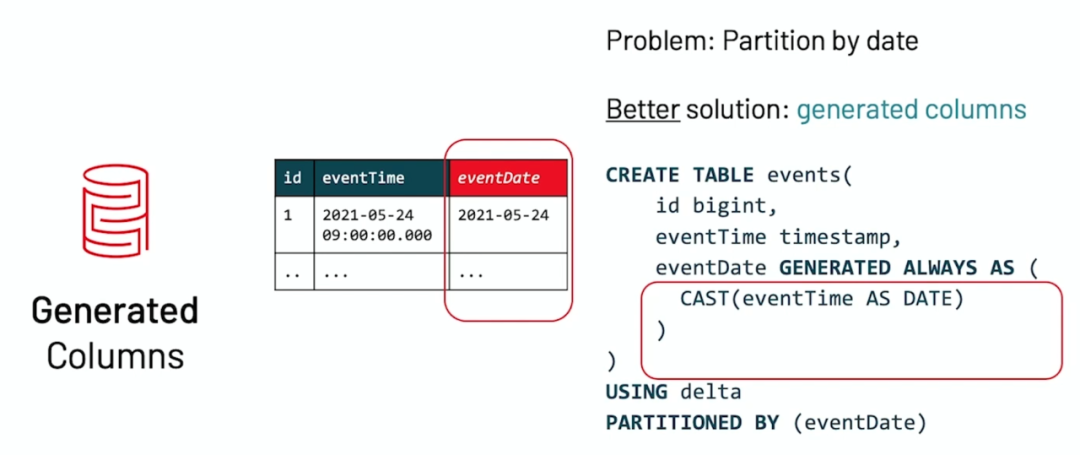
为了解决上面那个问题,Delta Lake 引入了 Generated Columns 的功能。这是一种特殊类型的列,它的值是根据用户指定的函数在 Delta 表中的其他列上自动生成的。我们可以使用 Apache Spark 中的大多数内置 SQL 函数来生成这些生成列的值。例如,可以从时间戳列自动生成日期列;对表的任何写入只需要为时间戳列指定数据。
值得注意的是,字节跳动的郭俊在2019年09月给 Spark 社区提了一个类似的功能,参见 SPARK-29031[1]。
简化存储配置
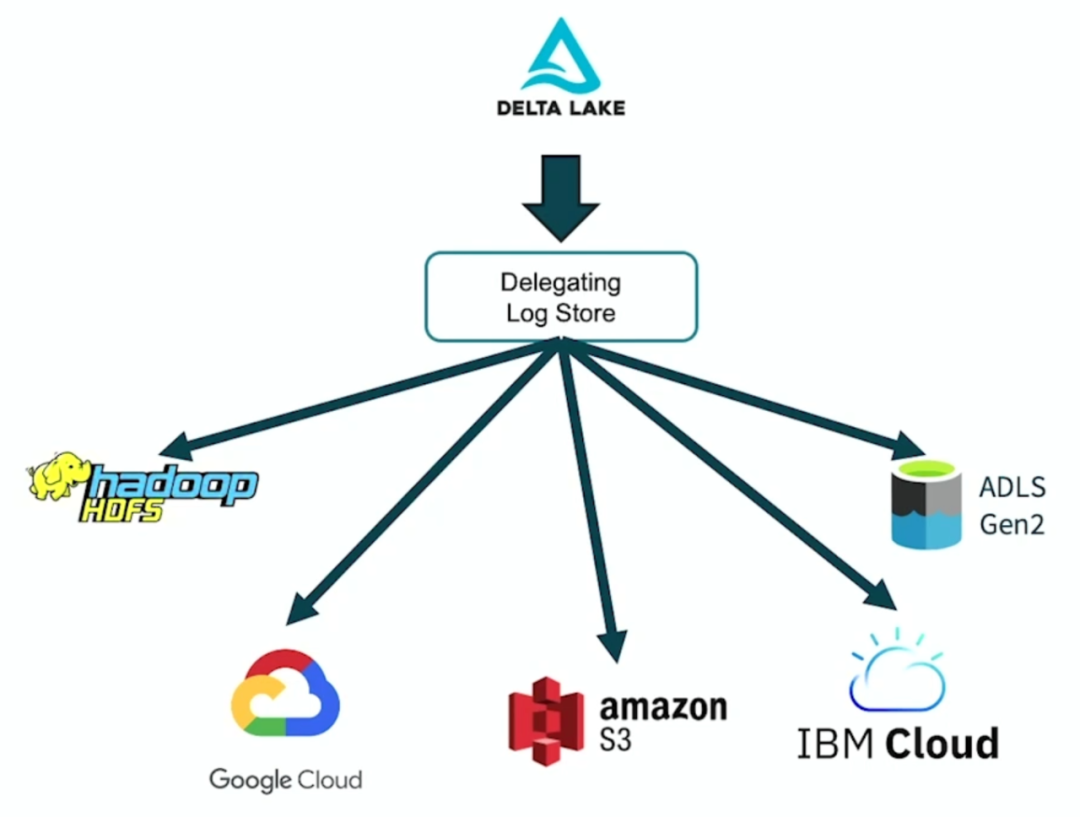
Delta Lake 现在可以自动加载正在被读写的 Delta 表的公共存储系统所需的正确 LogStore。如果用户在 AWS S3, Azure blob stores, 和 HDFS 上运行 Delta Lake,则不再需要显式配置 LogStore 实现。这还允许同一个应用程序同时读写不同云存储系统上的 Delta 表。Delta 表路径的 scheme 用于动态加载必要的LogStore 实现。注意,使用上面列出的存储系统之外的其他存储系统仍然需要显式配置。
支持多种引擎多种语言读写 Delta 表
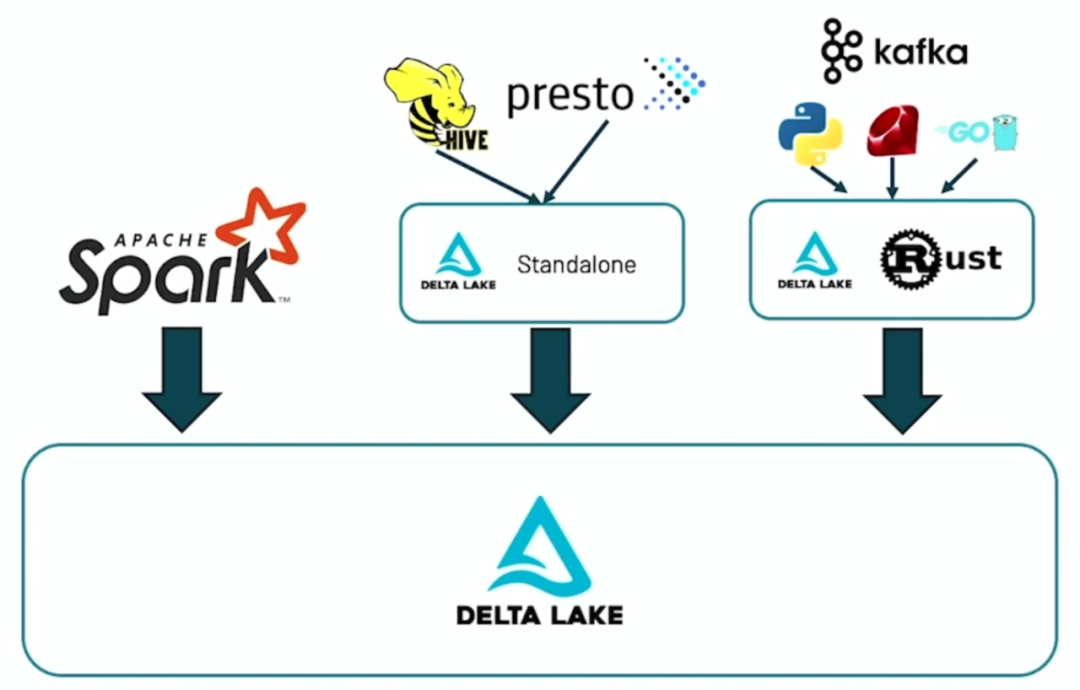
Delta Lake 现在允许我们以编程方式直接创建新的 Delta 表(Scala、Java 和 Python),而无需使用 DataFrame API。社区引入了新的 DeltaTableBuilder 和 DeltaColumnBuilder API 来实现所有可以通过 SQL 完成的操作。
支持 PyPI 方式来安装 Delta
我们现在可以通过 PyPI 来安装 Delta Lake,如下:
pip install delta-spark然后可以通过下面代码访问 Delta Lake 表信息:
from deltalake import DeltaTabledt = DeltaTable("$/iteblog/delta/data/")dt.version()dt.files()
更多关于 Delta Lake 1.0.0 的发布信息可以参见 Delta Lake 1.0.0 Released[2]
引用链接
[1] SPARK-29031: https://issues.apache.org/jira/browse/SPARK-29031[2] Delta Lake 1.0.0 Released: https://delta.io/news/delta-lake-1-0-0-released/