
扩展图神经网络:暴力堆叠模型深度并不可取
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


图神经网络(GNN)是一类近年来逐渐兴起的机器学习模型,它被用于学习图结构的数据。GNN 已经被成功地应用于对各种不同领域(包括社会科学、计算机视觉和图形学、粒子物理学、化学、医学等)的关系和交互的系统进行建模。
直到最近,该领域内大多数的研究仍重点关注于研发新型 GNN 模型,并且在小型图(例如,仅仅包含大约 5K 节点的引用网络 Cora 仍然被广泛使用)上测试这些模型;相对来说,处理大规模应用的研究工作鲜有人涉足。
另一方面,工业界的实际问题往往需要处理超大规模的图(例如,包含数百万节点、数十亿条边的 Twitter 或 Facebook 的社交网络)。
 大多数现有的文献中描述的方法在这样的大规模应用场景下并不适用。
大多数现有的文献中描述的方法在这样的大规模应用场景下并不适用。
简而言之,GNN 通过聚合局部邻居节点的特征来进行操作。当下流行的图卷积网络(GCN)模型通过将 d 维节点特征组织在一个 n×d 的矩阵 X 中(其中,n 代表节点的个数),在图上实现了一种最简单的类似于卷积的操作,它将节点层面上的变换与相邻节点之间的特征传递融合了起来。
Y = ReLU(AXW).
在这里,W 是各节点之间共享的可学习的矩阵,A 是一个线性传播算子,相当于邻居节点特征的加权平均。正如在传统的卷积神经网络(CNN)中一样,我们可以将多层堆叠的这种形式应用在序列中。
GNN 可以被设计用于在节点层面上(例如,检测社交网络中的恶意用户)、边的层面上(例如,推荐系统中典型的场景——链接预测)、或整个图的层面上(例如,预测分子图的化学性质)进行预测。例如,我们可以使用如下所示的双层 GCN 执行节点级别的分类任务:
Y = softmax(A ReLU(AXW)W’).
为什么扩展图神经网络十分具有挑战性呢?
在上述节点级别的预测问题中,GNN 会在样本节点上进行训练。
在传统的机器学习环境下,通常假设样本是以统计上相独立的方式从某个分布中采样得到的。反过来,这样就可以将损失函数分解为独立样本的贡献,并采用随机优化技术。
然而,图中的节点是通过边相互关联的,这使得训练集中的样本在统计意义上相互依赖。此外,由于节点之间的统计依赖性,采样过程可能会引入偏置。
例如,这可能使得一些节点或边在训练集中比其它节点或边出现得更频繁,而我们需要恰当地应对这种「副作用」。
最后,同样重要的是,我们需要保证采样得到的子图能够保留 GNN 可以利用的有意义的结构。
在许多早期的图神经网络工作中,并未考虑上述问题:诸如 GCN(图卷积网络)、ChebNet、MoNet 和 GAT 等网络架构都是使用全批量梯度下降(full-batch gradient descent)算法训练的。
这使我们必须在内存中维持全部图的邻接矩阵以及节点特征。因此,一个 L 层的 GCN 模型就具有了 O(Lnd²) 的时间复杂度和 O(Lnd +Ld²) 的空间复杂度,即使对于大小适度的图来说,这也是无法接受的。
GraphSAGE 是研究图神经网路的可扩展性问题的第一项工作,它是 Will Hamilton 等人撰写的奠基性论文。GraphSAGE 将邻居节点采样与 mini-batch 训练结合了起来,从而在大规模图上训练 GNN(「SAGE」指的是「采样与聚合」)。
该论文的核心思想是,为了用一个 L 层的 GCN 计算某个节点上的训练损失,只需要聚合该节点 L 跳之内邻居节点的信息,而在计算中不考虑图中更远一些的节点。
但问题在于,对于这种符合「小世界」模型的图(例如社交网络),由某些节点 2 跳内的邻居组成的子图可能就已经包含数百万的节点了,这使得我们很难将其存储在内存中。
GraphSAGE 通过至多对 L 跳的邻居进行采样来解决该问题:从正在训练的节点开始,该算法多次有放回地均匀采样 k 个 1 跳邻居;接着,对于每一个该节点的邻居节点,算法以相同的方式再采样 k 个邻居节点,以此迭代式地采样 L 次。通过这种方式,我们保证对于每个节点而言,可以聚合有界的 L 跳规模为 O(kᴸ) 的采样邻居节点。
如果我们使用 b 个训练节点构建一个 batch,且每个节点的 L 跳邻居节点相互独立,那么我们就会得到与图的规模 n 无关的空间复杂度 O(bkᴸ)。使用 GraphSAGE 算法时,一个 batch 的计算复杂度为 O(bLd²kᴸ)。
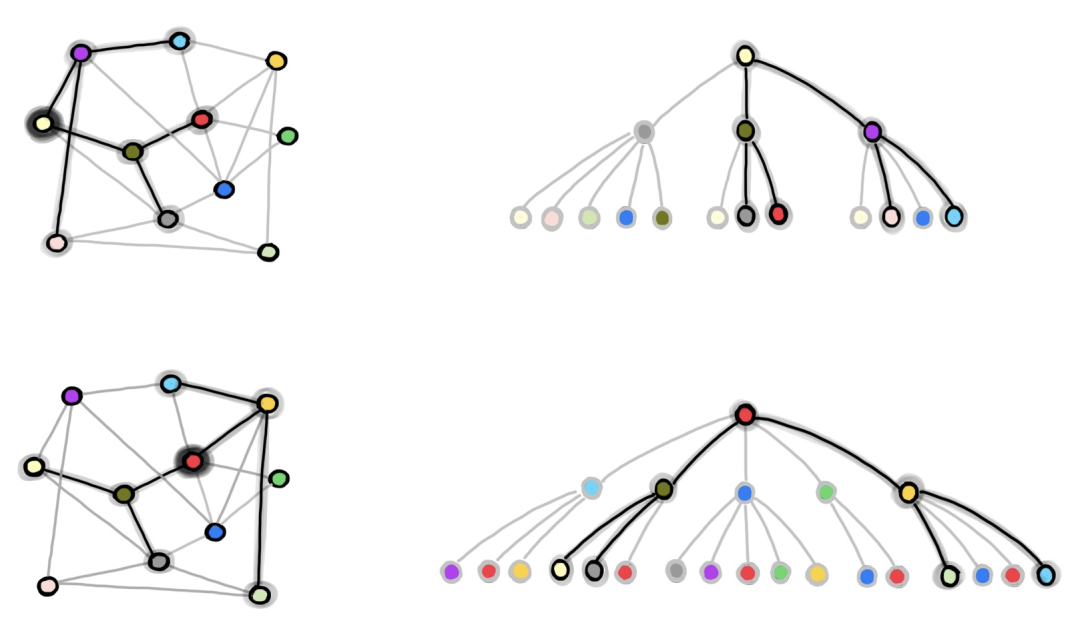
图 1:GraphSAGE 的邻居节点采样过程。我们从完整的图中下采样得到包含 b 个节点的 batch (在本例中,b=2,我们将红色和淡黄色的节点用于训练)。在右侧的图中,我们采样得到 2 跳邻居节点图,将其用于独立地计算红色和淡黄色节点的图嵌入和损失。
GraphSAGE 有一个显著的缺点,即采样得到的节点可能会出现很多次(由于有放回的抽样),因此可能会引入大量冗余的计算。例如,在上图中,深绿色的节点在两个训练节点的 L 跳邻居中都出现了。因此,在一个 batch 中,该深绿色节点的嵌入会被计算两次。
随着 batch 大小 b 和采样节点个数 k 的增长,冗余计算的规模也会增大。此外,对于每个 batch 而言,尽管拥有 O(bkᴸ) 的空间复杂度,但只会利用 b 个节点计算损失函数。因此,从某种程度上说,对于其它节点的计算也是一种浪费。
在 GraphSAGE 之后,许多后续的工作重点关注改进 mini-batch 的采样过程,从而减少 GraphSAGE 中的冗余计算,并使得每个 batch 更加高效。
ClusterGCN 和 GraphSAINT 是该研究方向最新的工作,它们采用了「图采样」(与 GraphSAGE 的邻居节点采样相对应)技术。

在图采样方法中,我们在每一个 batch 中采样得到原始图的一个子图,然后在整个子图上运行类似于 GCN 的模型。在这里,我们面临的挑战是,需要保证这些子图保留了大多数原始的边,并且能展现出有意义的拓扑结构。
为了实现上述目标,ClusterGCN 首先对图进行了聚类;然后,在每一个 batch 中,该模型会在一个聚类上进行训练。这使得每个 batch 中的节点会联系得尽可能的紧密。
GraphSAINT 则提出了一种通用的概率化的图采样器,它通过在原始的图中采样子图来构建用于训练的 batch。
我们可以根据不同的方案设计图采样器:例如,该采样器可以执行均匀节点采样、均匀边采样,或者通过使用随机游走计算节点的重要性、将其用于采样的概率分布从而进行「重要性采样」。
请注意,进行采样的好处之一是:在训练时,采样可以作为一种边级别上的「dropout」技术,它可以对模型进行正则化,从而提升模型的性能。然而,在推理时,边 dropout 仍然需要看到所有的边,而在上述方法中,我们这些无法获得这些边的信息。
图采样技术的另一个影响是,它可以减少在邻居节点指数级增长的情况下,存在的「信息瓶颈」及其造成的「过度挤压」现象。
在我们与 Ben Chamberlian、Davide Eynard 以及 Federico Monti 等人联合发表的论文 “SIGN: Scalable Inception Graph Neural Networks” 中,我们研究了为节点级分类问题设计简单、与采样无关的架构的可能性。
考虑到上文介绍的采样技术的间接好处,读者可能会问:为什么我们要摒弃采样策略呢?
原因如下:节点分类问题的实例之间可能存在显著的差异,据我们所知,至今还没有工作系统地研究了「何时采样」能真正起到积极的作用,而不是仅仅减轻了计算复杂度。
对采样方案的实现引入了额外的复杂性,而我们相信,我们需要的是一种简单、强大、与采样无关、可扩展的基线架构
方法探究
我们的方法受到了一些近期发布的实验结果的启发。首先,在很多情况下,简单的固定的信息聚合器(例如 GCN)比一些更加复杂的信息聚合器(例如,GAT 和 MPNN)性能更好。
此外,尽管深度学习的成功是建立在拥有多层的模型之上的,但是在图深度学习领域中,「模型是否需要很深」仍然是一个有待解决的开放性问题。
具体而言,Wu 等人在论文「Simplifying Graph Convolutional Networks」中指出,只拥有一个多跳信息传播层的 GCN 模型可以拥有与具有多个信息传播层的模型相当的性能。
通过在单个卷积层中组合不同的、固定的邻居节点聚合器,我们可以在不使用图采样技术的前提下,得到具有非常大的可扩展性的模型。换句话说,我们在该架构的第一层进行所有与图相关的(固定的)操作,因此这些操作可以被预计算。
接下来,这些预先聚合的信息可以作为模型其它部分的输入,而由于缺少邻居节点的信息聚合,这些部分可以被归纳为一个多层感知机(MLP)。
需要指出的是,即使我们使用了这么浅的卷积方案,通过采用一些(可能专用的、更复杂的)信息传播算子,我们仍然能保留图卷积操作的表达能力。例如,我们可以设计一些算子来考虑「局部子图计数」或图中的模体(motif)。
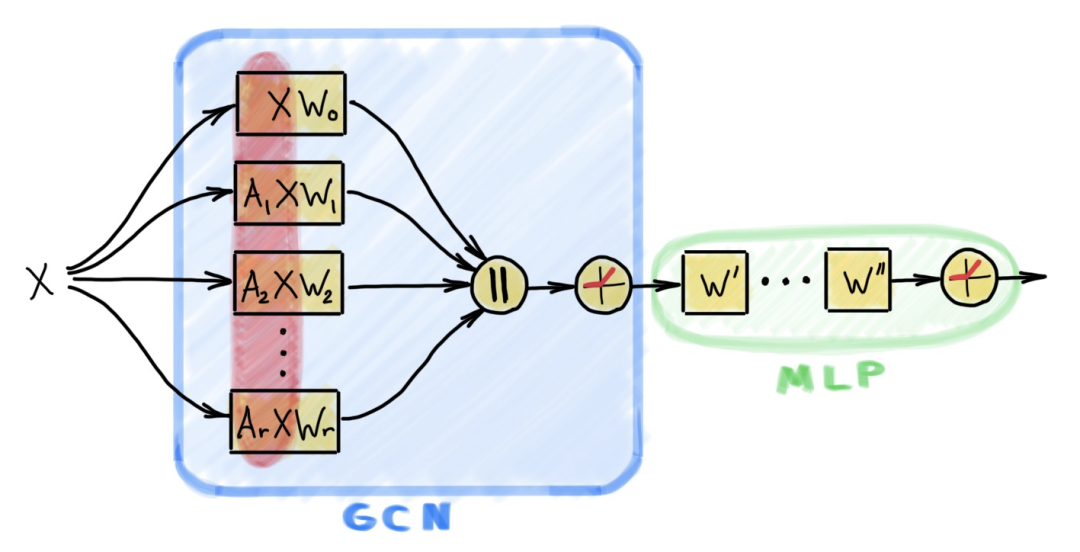
图 2:SIGN 架构包含一个类似于 GCN 的层,它带有多个线性传播算子,这些算子可能作用于多跳邻居节点。在这个层后面,会连接着一个面向节点级别应用的多层感知机。该架构之所以具有较高的计算效率,是由于对被传播的特征的预计算(如图中红色部分所示)。
我们提出的可扩展架构被称为 SIGN,它面向的是如下所示的节点级分类任务:
Y = softmax(ReLU(XW₀ | A₁XW₁ | A₂XW₂ | … | AᵣXWᵣ) W’)
其中,Aᵣ 是线性传播矩阵(例如一个正则化的邻接矩阵,它的幂,或者一个模体矩阵)。Wᵣ 和 W’ 是可学习的参数。如图 2 所示,该网络可以通过加入面向节点的层变得更深:
Y = softmax(ReLU(…ReLU(XW₀ | A₁XW₁ | … | AᵣXWᵣ) W’)… W’’)
最后,当我们对相同的传播算子应用不同的幂(例如,A₁=B¹, A₂=B²,等等)时,图操作有效地在越来越远的跳中聚合了来自邻居节点的信息,这类似于在相同的网络层中感受野不同的卷积核。
在这里,与经典的卷积神经网络中「Inception」模块的类比,解释了我们提出的论文的名字 SIGN 的由来。
如前文所述,上述等式中矩阵的积 A₁X,…, AᵣX 并不依赖可学习的模型参数,因此可以被预计算。具体而言,对于规模超大的图来说,我们可以使用 Apache Spark 等分布式计算架构高效地扩展这种预计算过程。
这种做法有效地将整体模型的计算复杂度降低到了与多层感知机相同的水平上。此外,通过将信息传播过程转移到预计算步骤中,我们可以聚合来自所有邻居节点的信息,从而避免采样过程及其可能带来的信息损失与偏置。
SIGN 主要的优点在于其可扩展性与效率,我们可以使用标准的 mini-batch 梯度下降方法训练它。
我们发现,在保持与目前最先进的 GraphSAINT 模型准确率非常接近的条件下,在推理阶段,SIGN 的运算速度比 ClusterGCN 和 GraphSAINT 要快两个数量级;而在训练阶段,SIGN 也要比它们快得多。
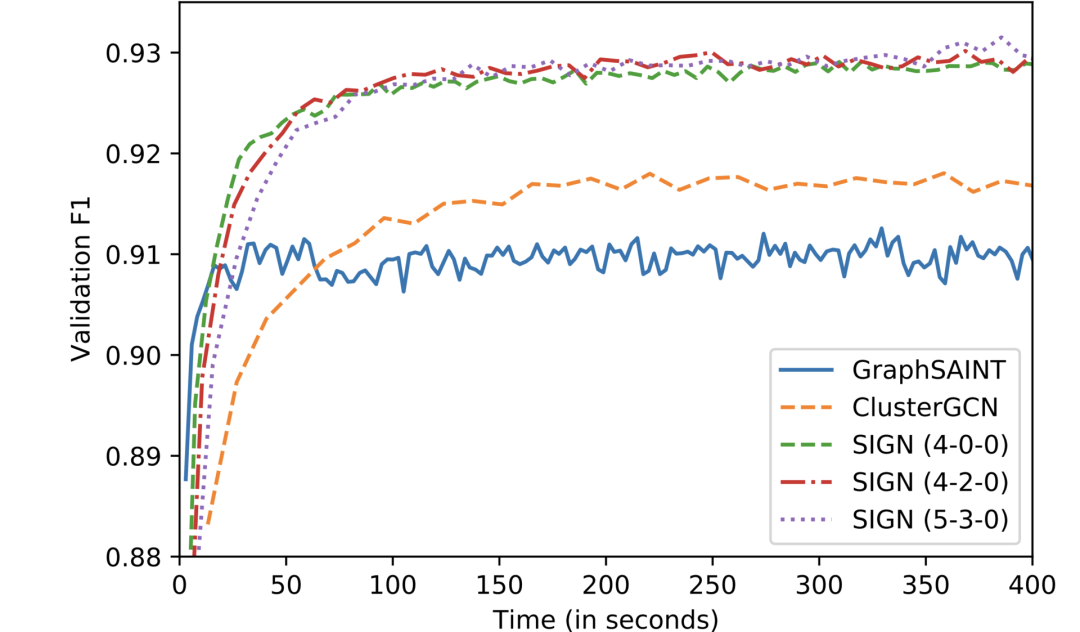
图 3:在 OGBN-Product 数据集上,不同方法的收敛情况。SIGN 的各种变体都要比GraphSAINT 和 ClusterGCN 收敛地更快,并且能够在验证中得到更高的 F1 分数。 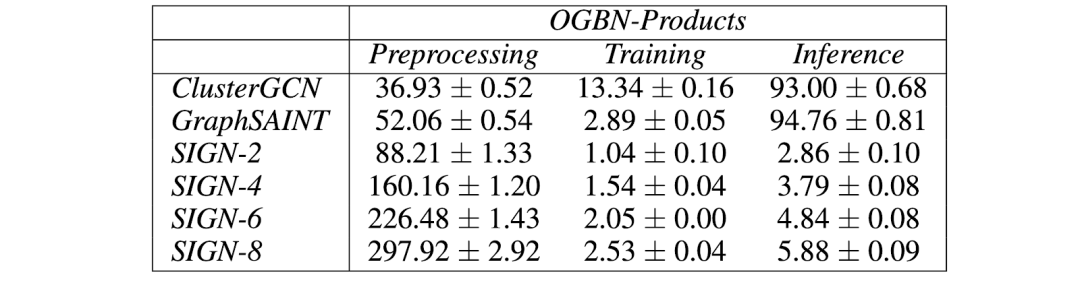
图 4:在 OGBN-Product 数据集上,不同方法的预处理、训练、推理时间(单位:秒)。尽管 SIGN 的预处理过程较为缓慢,但是 SIGN 在训练阶段要比对比基线快得多,并且在推理阶段要比其它方法快上近两个数量级。
此外,我们的模型也支持任意的传播算子。对于不同类型的图而言,也许我们必须处理不同的传播算子。
我们发现,有一些任务可以获益于基于模体的算子(如三角形计数)。

图 5:在一些流行的数据集上,SIGN 模型以及其它可扩展方法在节点分类任务中的性能。基于三角模体的传播算子在 Flickr 数据集上取得了较大的性能提升,在 PPI 和 Yelp 数据集上也有一定的性能提升。
尽管受限于只拥有单个图卷积层,以及只使用了线性传播算子,SIGN 实际上可以良好运行,取得了与更加复杂的模型相当、甚至更好的性能。由于 SIGN 具有很快的运算速度并且易于实现,我们期待 SIGN 成为一种大规模应用的图学习方法的简单对比基线。
也许,更重要的是,由于这种简单的模型取得了成功,我们不禁要提出一个更本质的问题:「我们真的需要深度的图神经网络吗」?
我们推测,在许多面向社交网络以及「小世界」图的学习问题中,我们需要使用更为丰富的局部结构信息,而不是使用暴力的深度架构。
有趣的是,由于算力的进步以及将较为简单的特征组合为复杂特征的能力,传统的卷积神经网络架构朝着相反的方向发展(使用更小卷积核的更深的网络)。
我们尚不明确同样的方法是否适用于图学习问题,因为图的组合性要复杂得多(例如,无论网络有多深,某些结构都不能通过消息传递来计算)。
当然,我们还需要通过更多详细的实验来验证这一猜想。
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~