
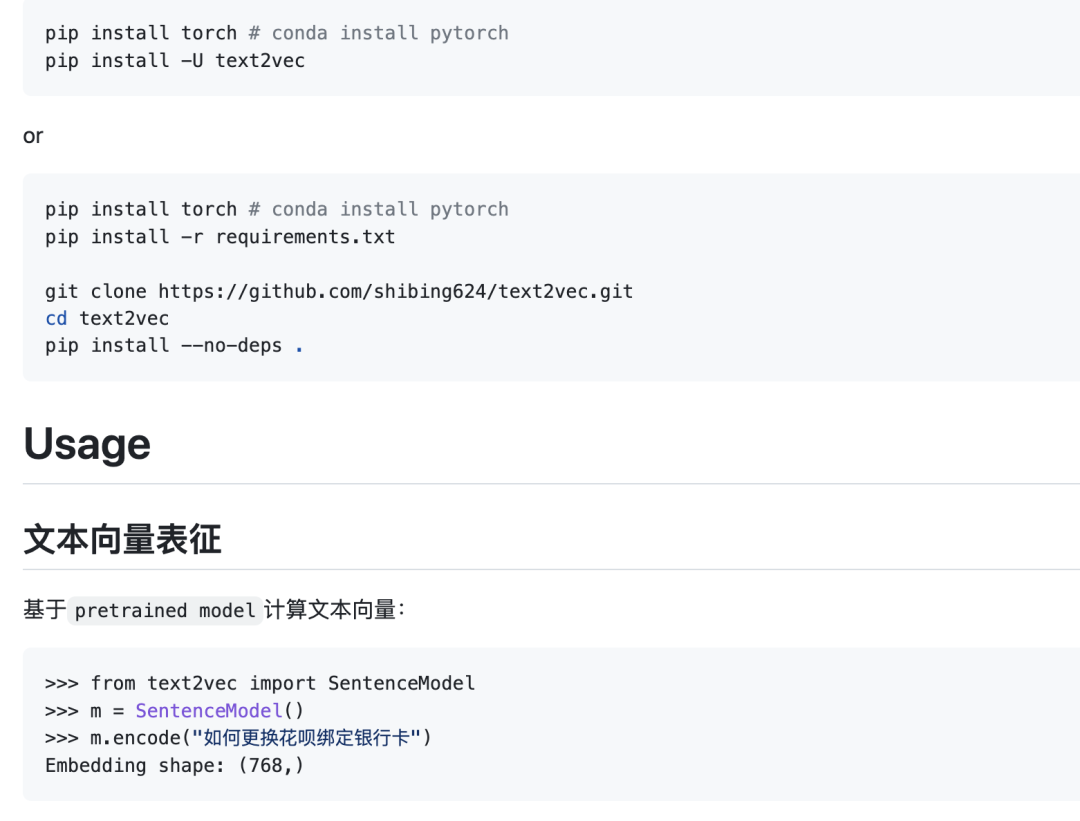
文本向量表征工具,实现了Word2Vec、RankBM25、Sentence-BERT...

向AI转型的程序员都关注了这个号👇👇👇
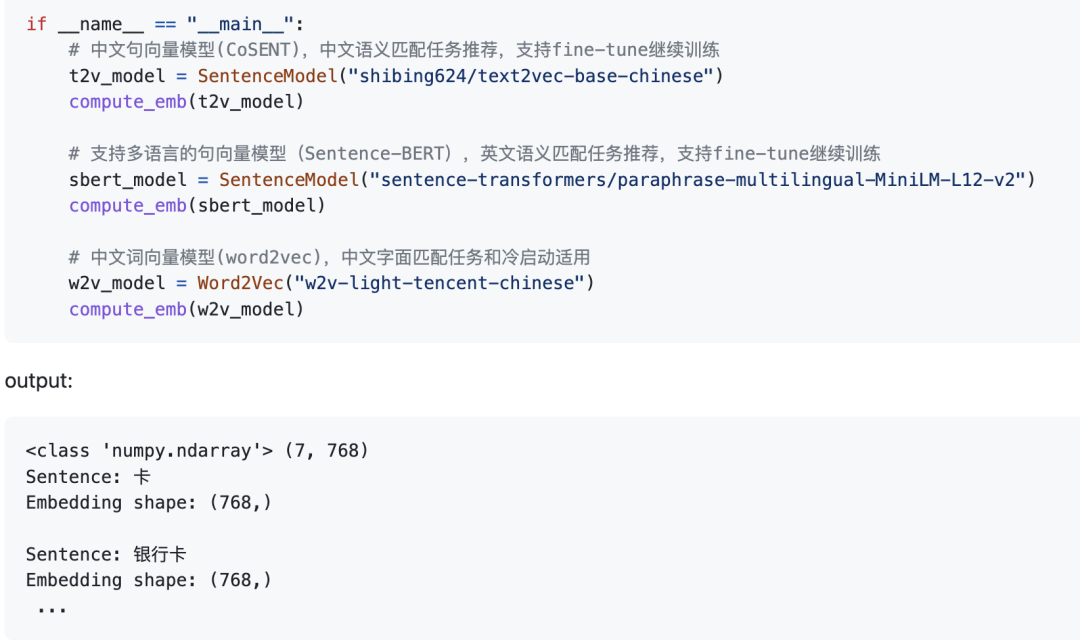
文本向量表示模型
Word2Vec:通过腾讯AI Lab开源的大规模高质量中文词向量数据(800万中文词轻量版) (文件名:light_Tencent_AILab_ChineseEmbedding.bin 密码: tawe)实现词向量检索,本项目实现了句子(词向量求平均)的word2vec向量表示
SBERT(Sentence-BERT):权衡性能和效率的句向量表示模型,训练时通过有监督训练上层分类函数,文本匹配预测时直接句子向量做余弦,本项目基于PyTorch复现了Sentence-BERT模型的训练和预测
CoSENT(Cosine Sentence):CoSENT模型提出了一种排序的损失函数,使训练过程更贴近预测,模型收敛速度和效果比Sentence-BERT更好,本项目基于PyTorch实现了CoSENT模型的训练和预测
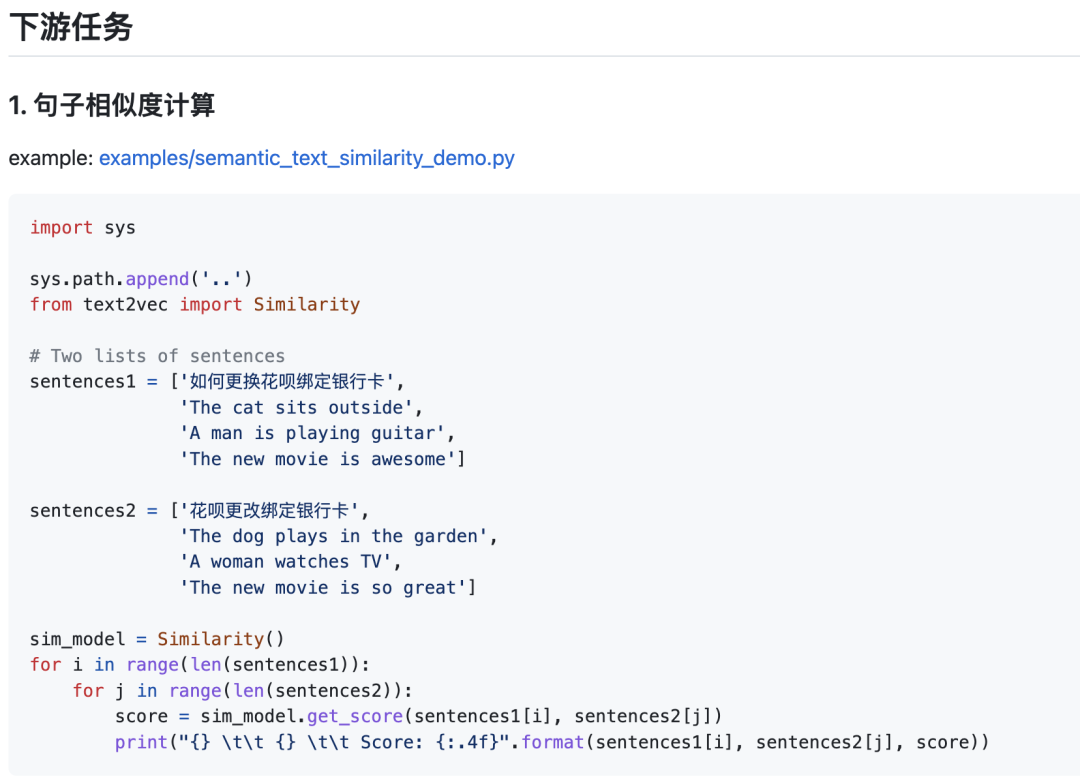
文本匹配
英文匹配数据集的评测结果:

中文匹配数据集的评测结果:
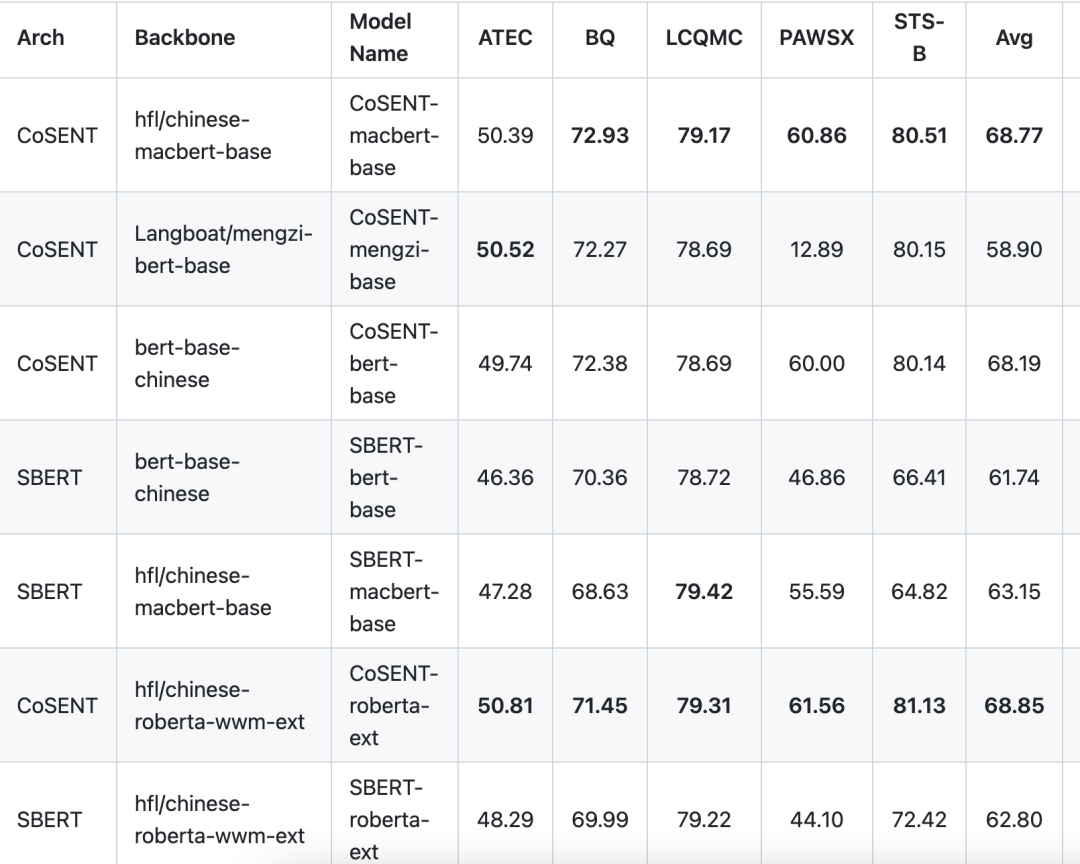
说明:
结果值均使用spearman系数
结果均只用该数据集的train训练,在test上评估得到的表现,没用外部数据
shibing624/text2vec-base-chinese模型,是用CoSENT方法训练,基于MacBERT在中文STS-B数据训练得到,并在中文STS-B测试集评估达到SOTA,运行examples/training_sup_text_matching_model.py代码可复现结果,模型文件已经上传到huggingface的模型库shibing624/text2vec-base-chinese,中文语义匹配任务推荐使用
SBERT-macbert-base模型,是用SBERT方法训练,运行examples/training_sup_text_matching_model.py代码复现结果
paraphrase-multilingual-MiniLM-L12-v2模型名称是sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2,是用SBERT训练,是paraphrase-MiniLM-L12-v2模型的多语言版本,支持中文、英文等
w2v-light-tencent-chinese是腾讯词向量的Word2Vec模型,CPU加载使用,适用于中文字面匹配任务和缺少数据的冷启动情况
各预训练模型均可以通过transformers调用,如MacBERT模型:
--model_name hfl/chinese-macbert-base或者roberta模型:--model_name uer/roberta-medium-wwm-chinese-cluecorpussmall
中文匹配数据集下载链接见下方
中文匹配任务实验表明,pooling最优是
first_last_avg,即 SentenceModel 的EncoderType.FIRST_LAST_AVG,其与EncoderType.MEAN的方法在预测效果上差异很小
QPS的GPU测试环境是Tesla V100,显存32GB
代码地址:
关注微信公众号 datayx 然后回复
向量
即可获取。
Demo


Word2Vec词向量
提供两种Word2Vec词向量,任选一个:
轻量版腾讯词向量 百度云盘-密码:tawe 或 谷歌云盘,二进制文件,111M,是简化后的高频143613个词,每个词向量还是200维(跟原版一样),运行程序,自动下载到
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin
腾讯词向量-官方全量, 6.78G放到:
~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt,腾讯词向量主页:https://ai.tencent.com/ailab/nlp/zh/index.html 词向量下载地址:https://ai.tencent.com/ailab/nlp/en/download.html 更多查看腾讯词向量介绍-wiki



下游任务支持库
similarities库[推荐]
文本相似度计算和文本匹配搜索任务,推荐使用 similarities库 ,兼容本项目release的 Word2vec、SBERT、Cosent类语义匹配模型,还支持字面维度相似度计算、匹配搜索算法,支持文本、图像。
安装: pip install -U similarities
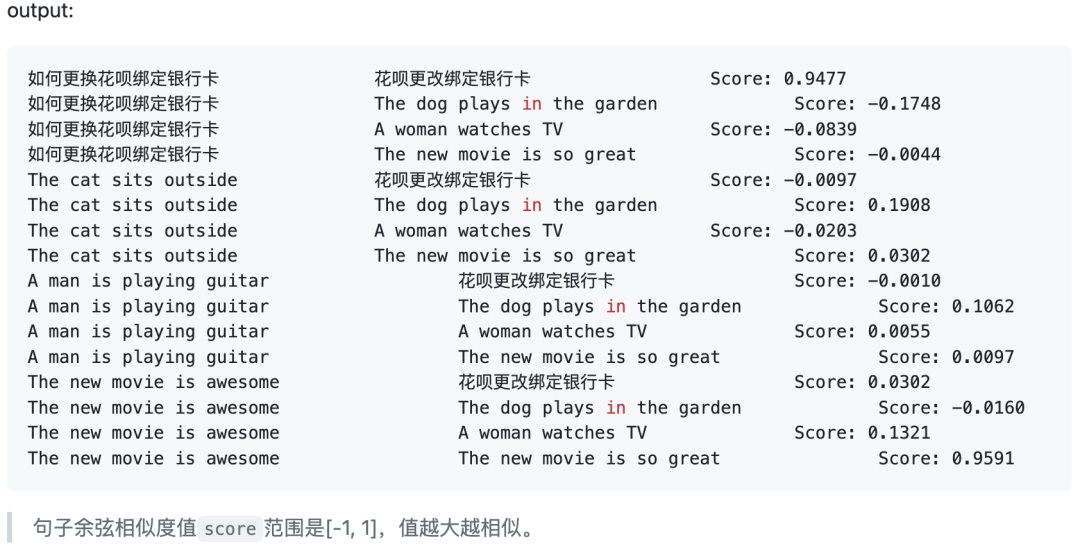
句子相似度计算:

模型蒸馏(Model Distillation)
由于text2vec训练的模型可以使用sentence-transformers库加载,此处复用其模型蒸馏方法distillation。
模型降维,参考dimensionality_reduction.py使用PCA对模型输出embedding降维,可减少milvus等向量检索数据库的存储压力,还能轻微提升模型效果。
模型蒸馏,参考model_distillation.py使用蒸馏方法,将Teacher大模型蒸馏到更少layers层数的student模型中,在权衡效果的情况下,可大幅提升模型预测速度。
模型部署
提供两种部署模型,搭建服务的方法:1)基于Jina搭建gRPC服务【推荐】;2)基于FastAPI搭建原生Http服务。
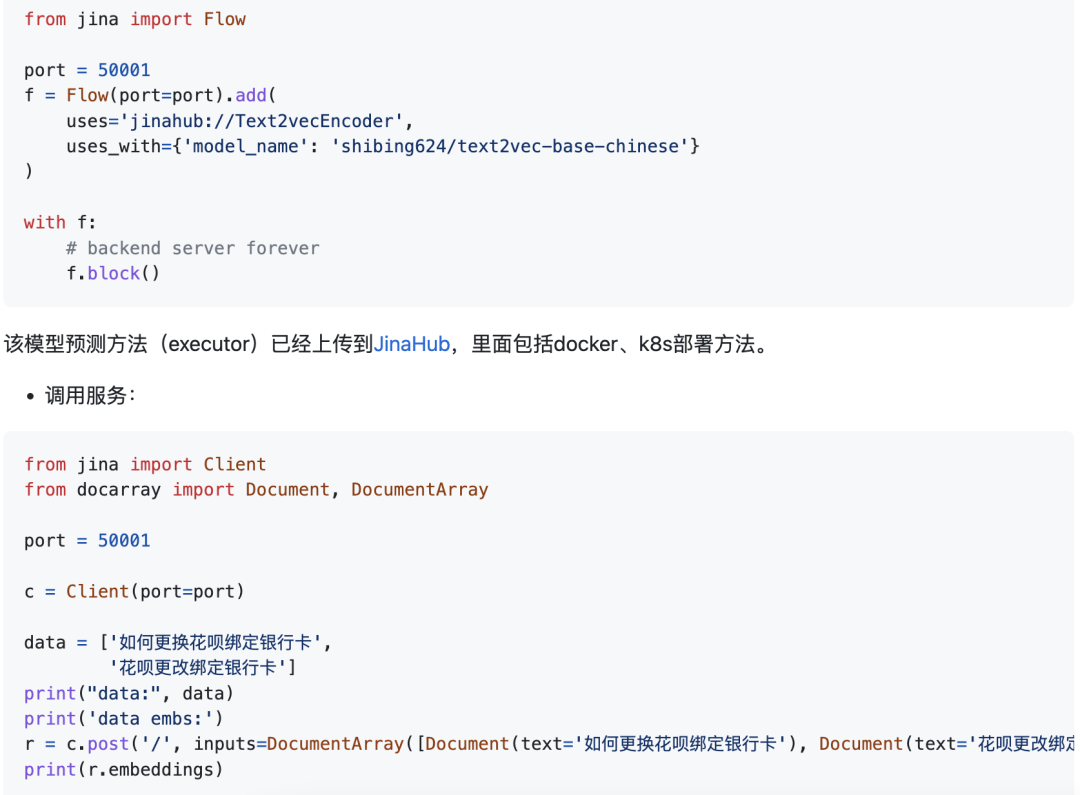
Jina服务
采用C/S模式搭建高性能服务,支持docker云原生,gRPC/HTTP/WebSocket,支持多个模型同时预测,GPU多卡处理。
安装:
pip install jina
启动服务:
example: examples/jina_server_demo.py
机器学习算法AI大数据技术
搜索公众号添加:
datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加:
datayx