
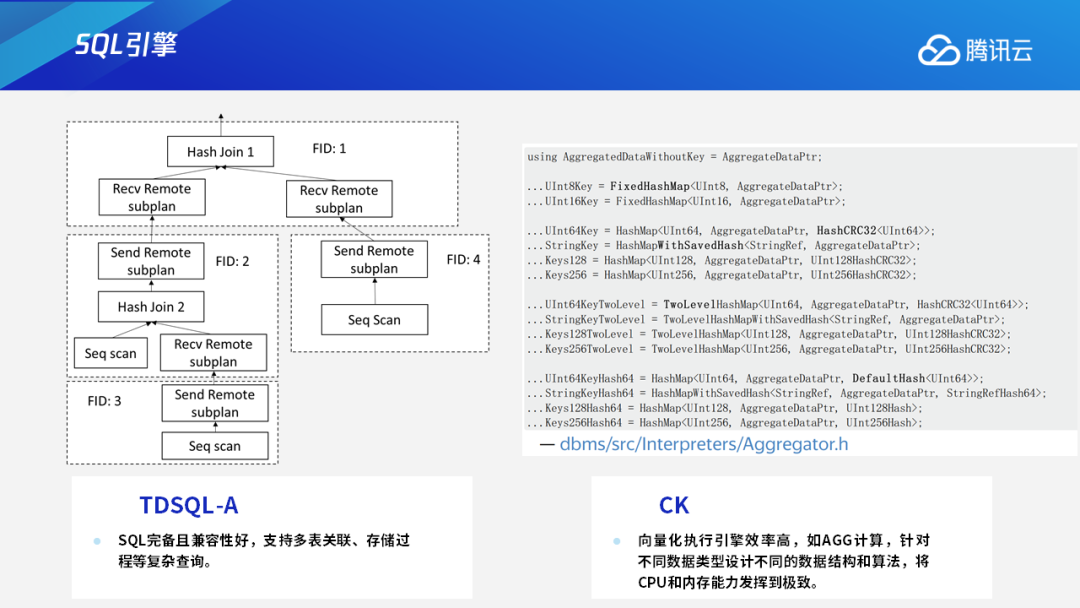
这就是TDSQL的向量化执行引擎?有效降低函数调用开销,提升CPU利用率
在“国产数据库硬核技术沙龙-TDSQL-A技术揭秘”系列分享中,5位腾讯云技术大咖分别从整体技术架构、列式存储及相关执行优化、集群数据交互总线、Fragment执行框架/查询分片策略/子查询框架以及向量化执行引擎等多方面对TDSQL-A进行了深入解读。没有观看直播的小伙伴,可要认真做笔记啦!今天带来本系列分享中最后一篇腾讯云数据库高级工程师胡翔老师主题为“TDSQL-A向量化执行引擎技术揭秘”的分享的文字版。
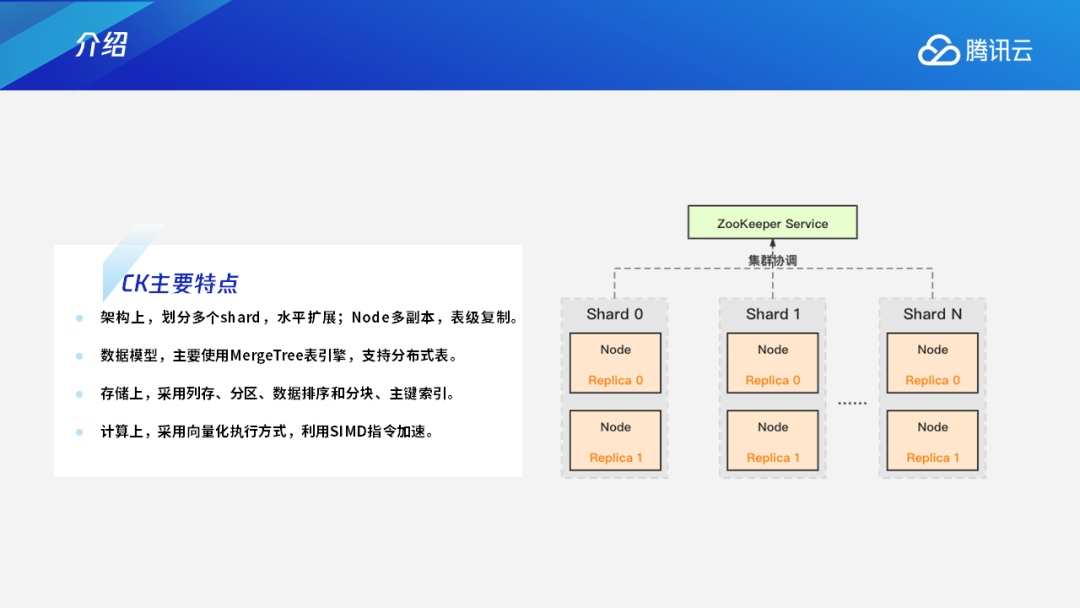
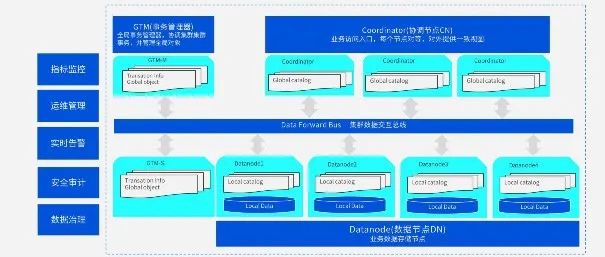
作为领先的分析型数据库,TDSQL-A是腾讯首款分布式分析型数据库,采用全并行无共享架构,具有自研列式存储引擎,支持行列混合存储,适应于海量OLAP关联分析查询场景。它能够支持2000台物理服务器以上的集群规模,存储容量能达到单数据库实例百P级。
一、TDSQL-A向量化执行引擎


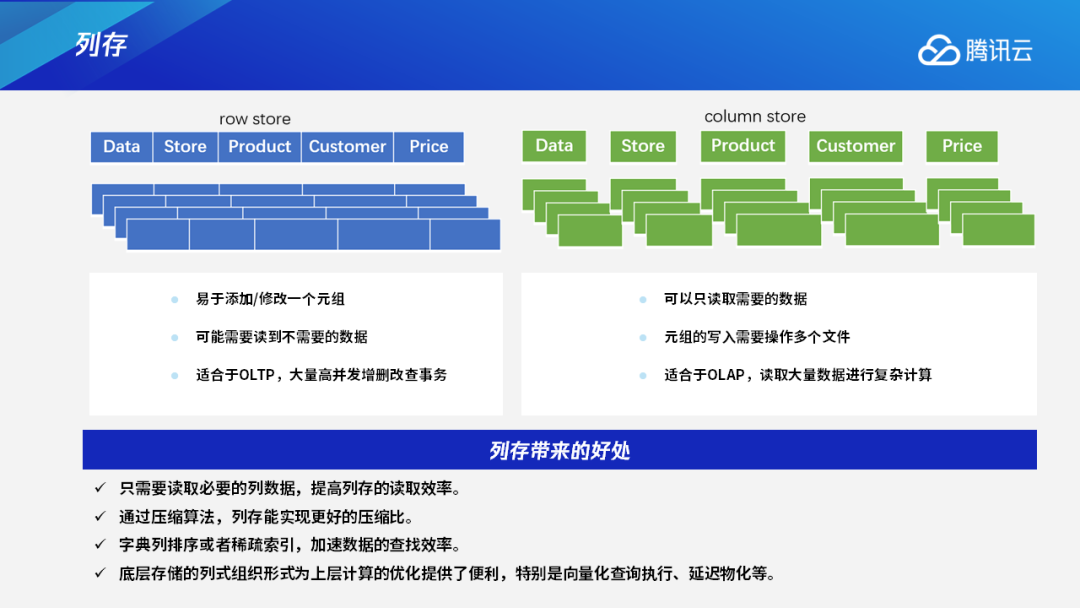
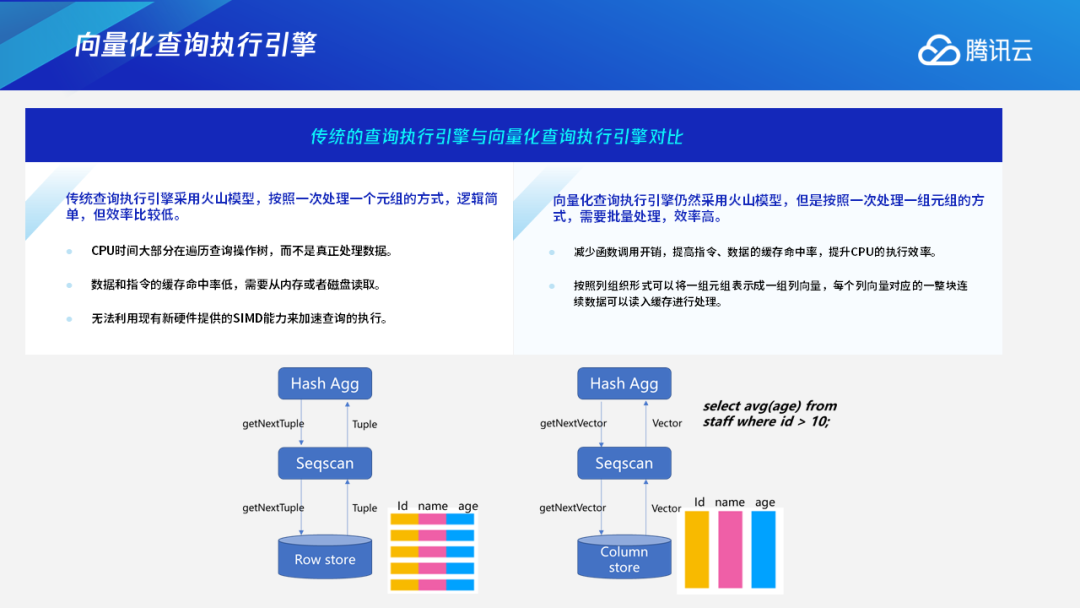
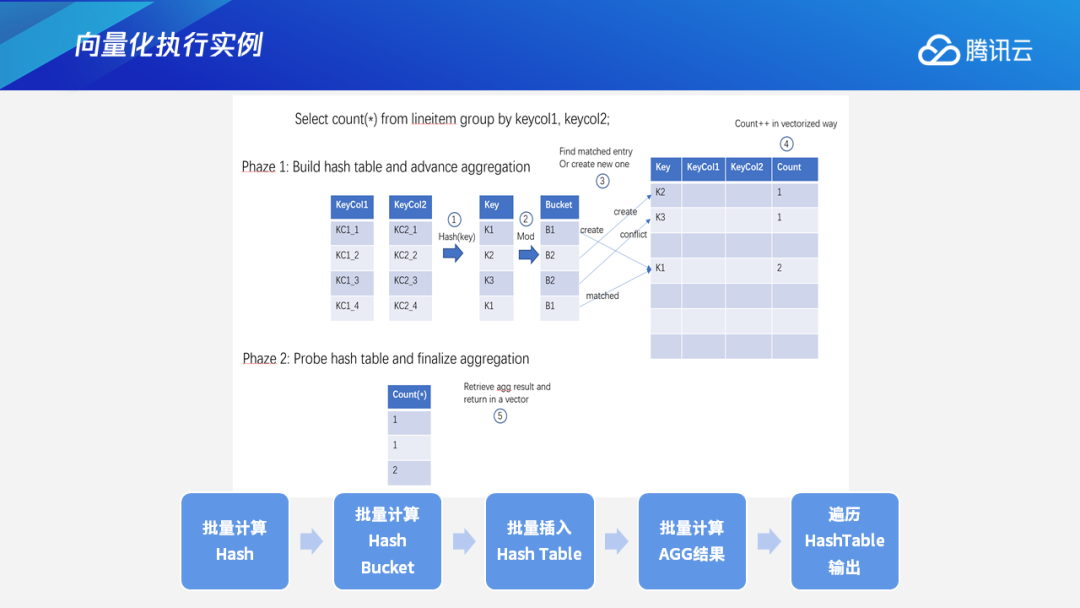

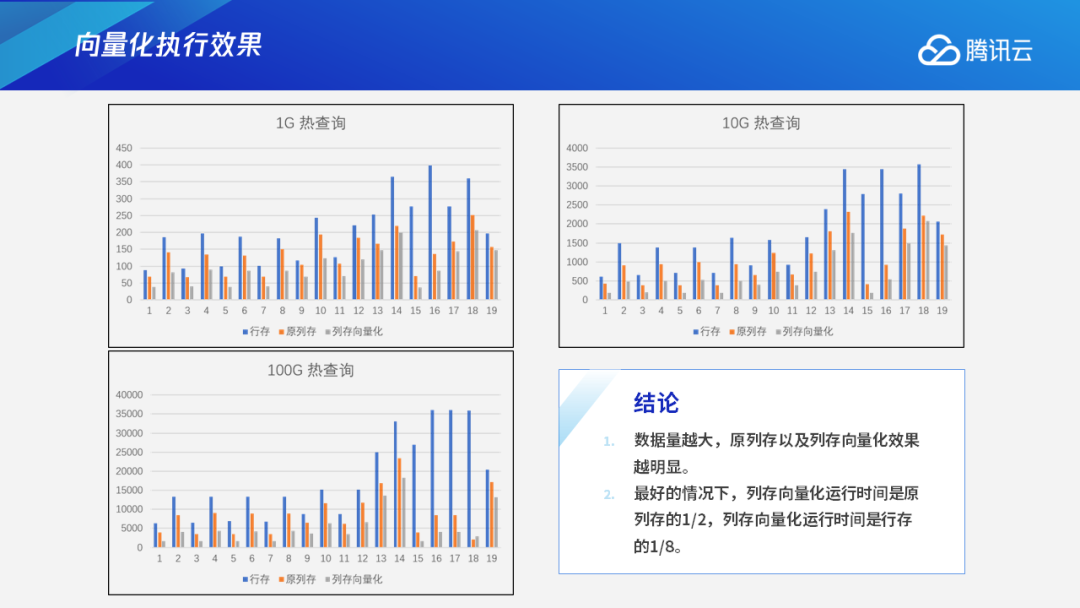

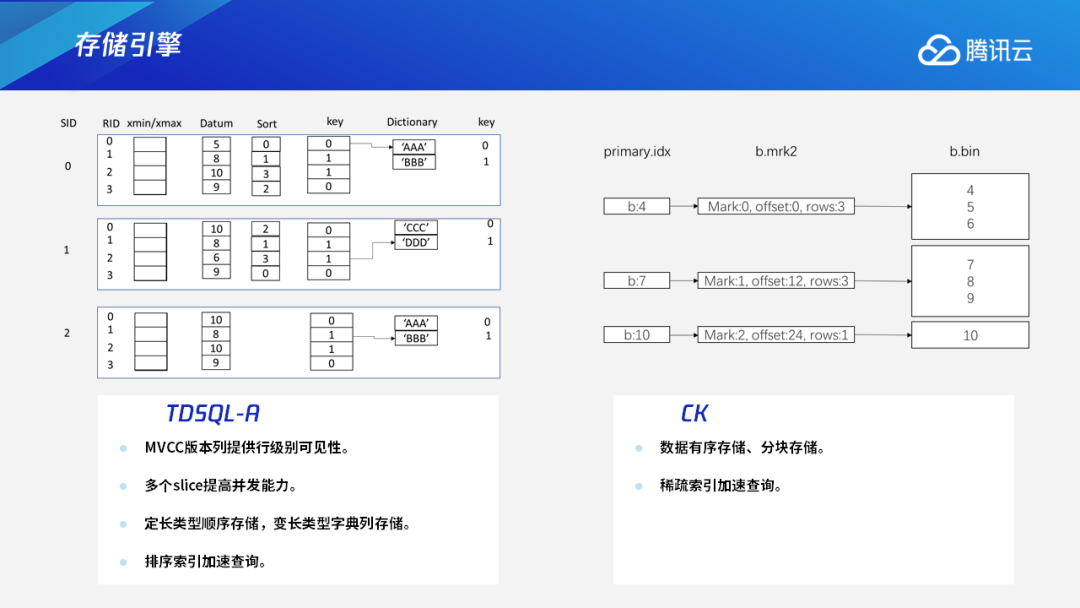
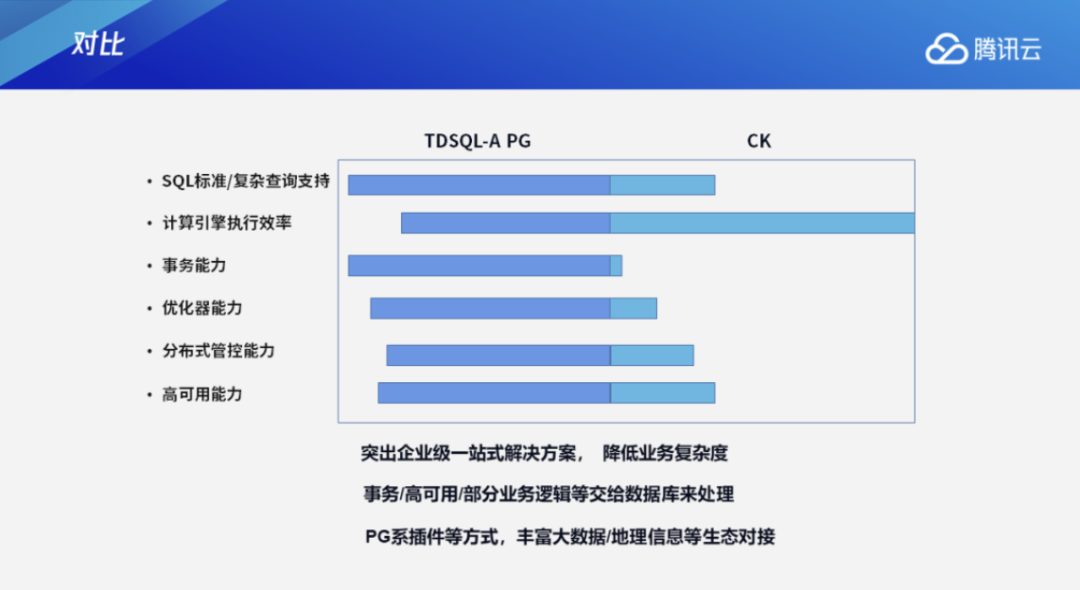
二、TDSQL-A与CK的对比
﹀
﹀
﹀
-- 更多精彩 --

揭秘TDSQL-A分布式执行框架:解放OLAP关联分析查询性能瓶颈

揭秘TDSQL-A:兼容Oracle的同时支持海量数据交互
TDSQL-A自研列存储及优化原理大揭秘

海量数据,极速体验——TDSQL-A核心架构详解来了
评论