
PyTorch+TensorRT!20倍推理加速!
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!转自:新智元

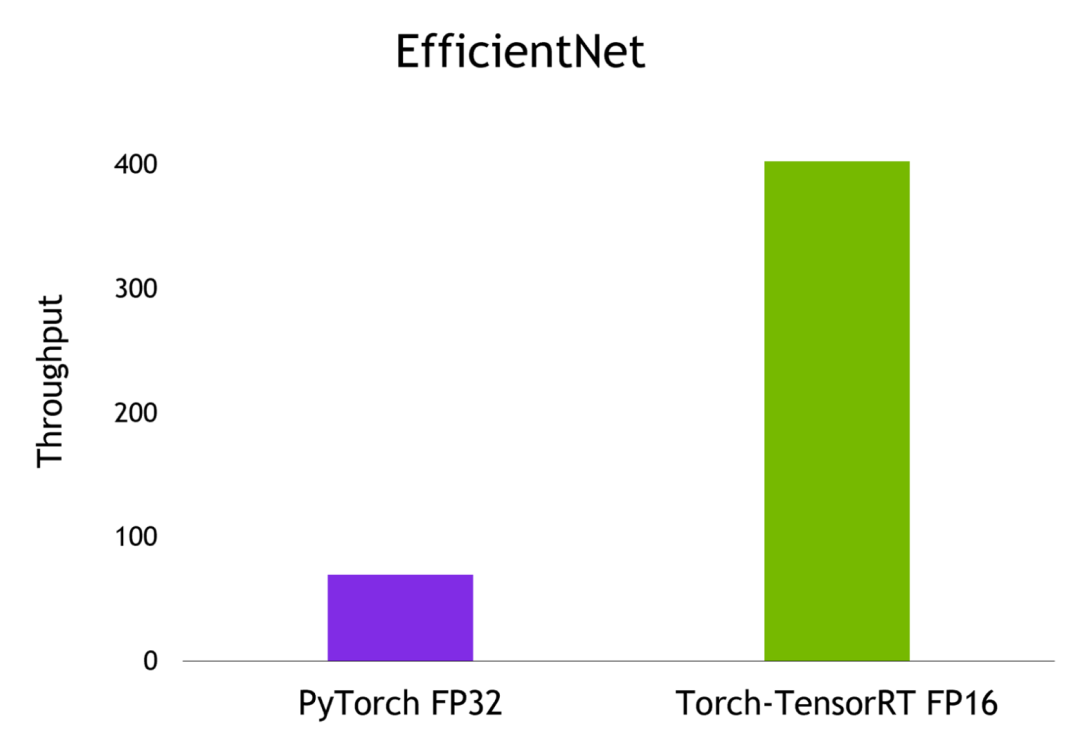
Torch-TensorRT:6倍加速

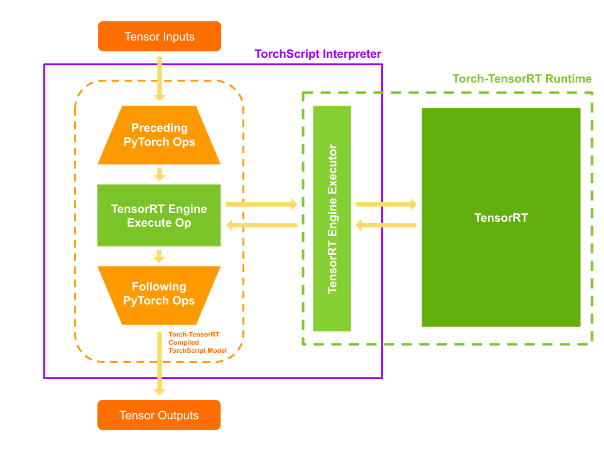
Torch-TensorRT:工作原理
简化TorchScript模块
转换
执行
简化TorchScript模块

转换
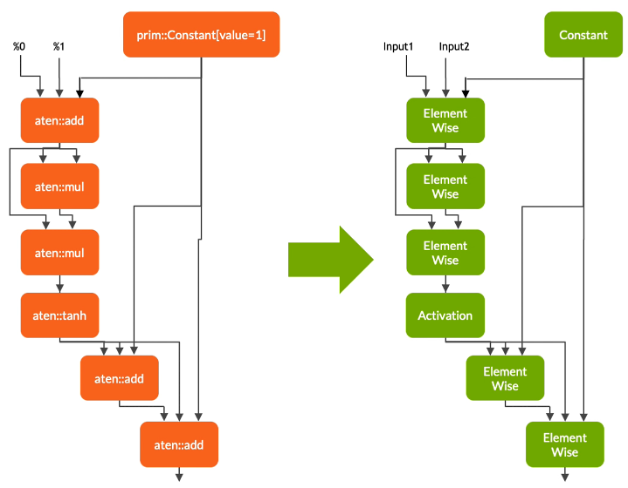
具有静态值的节点被评估并映射到常数。
描述张量计算的节点被转换为一个或多个TensorRT层。
剩下的节点留在TorchScript中,形成一个混合图,并作为标准的TorchScript模块返回。
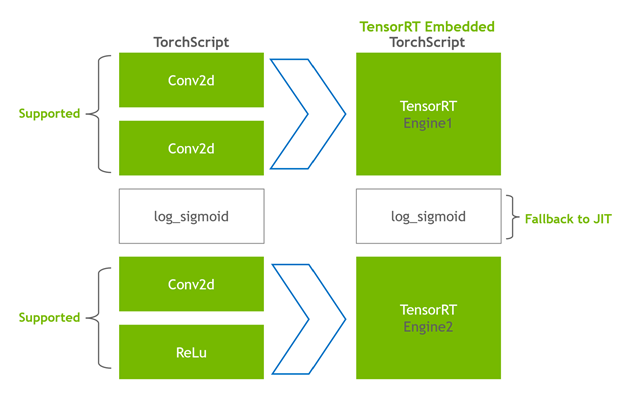
执行
Torch-TensorRT:特点
Torch-TensorRT:特点
对INT8的支持
训练后量化(PTQ)
量化感知训练(QAT)
稀疏性
举个例子
用TensorRT实现T5和GPT-2实时推理
用TensorRT实现T5和GPT-2实时推理

T5和GPT-2简介
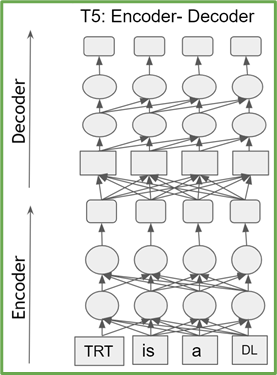

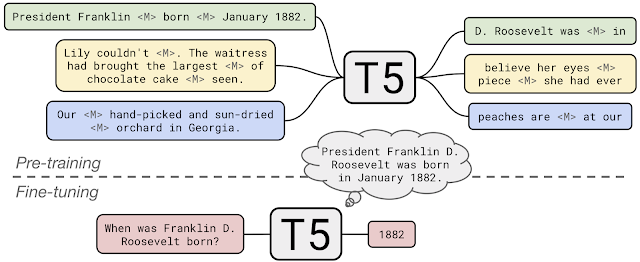
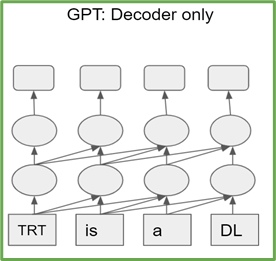
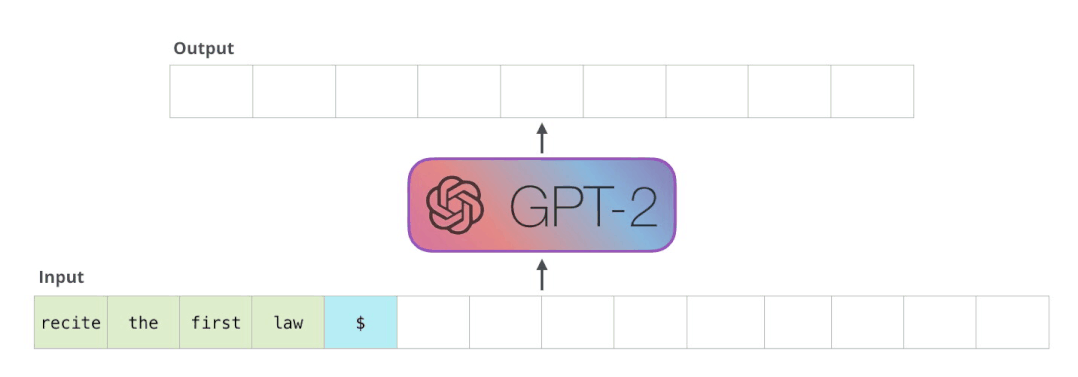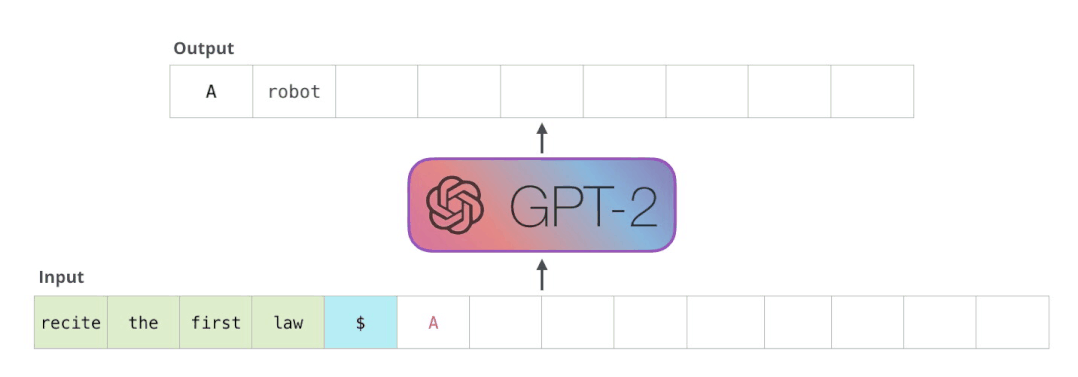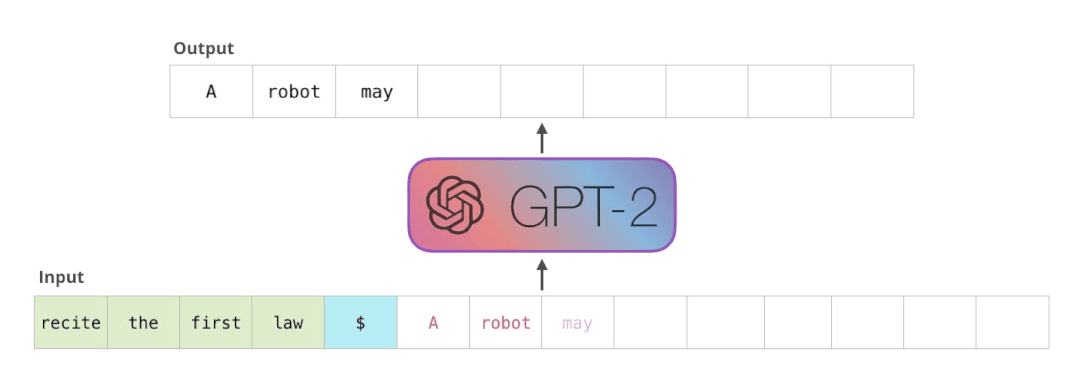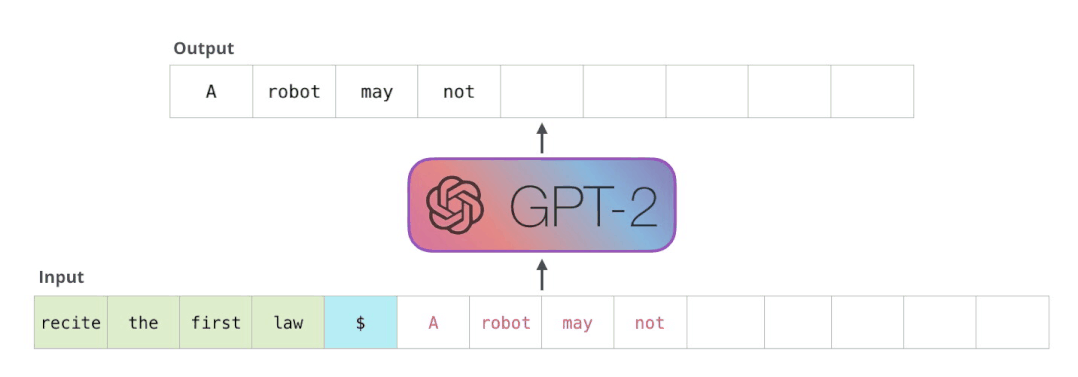
用TensorRT部署T5和GPT-2
T5_VARIANT = 't5-small't5_model = T5ForConditionalGeneration.from_pretrained(T5_VARIANT)tokenizer = T5Tokenizer.from_pretrained(T5_VARIANT)config = T5Config(T5_VARIANT)
encoder_onnx_model_fpath = T5_VARIANT + "-encoder.onnx"decoder_onnx_model_fpath = T5_VARIANT + "-decoder-with-lm-head.onnx"t5_encoder = T5EncoderTorchFile(t5_model.to('cpu'), metadata)t5_decoder = T5DecoderTorchFile(t5_model.to('cpu'), metadata)onnx_t5_encoder = t5_encoder.as_onnx_model(os.path.join(onnx_model_path, encoder_onnx_model_fpath), force_overwrite=False)onnx_t5_decoder = t5_decoder.as_onnx_model(os.path.join(onnx_model_path, decoder_onnx_model_fpath), force_overwrite=False)
t5_trt_encoder_engine = T5EncoderONNXt5_trt_encoder_engine = T5EncoderONNXFile(os.path.join(onnx_model_path, encoder_onnx_model_fpath), metadata).as_trt_engine(os.path.join(tensorrt_model_path, encoder_onnx_model_fpath) + ".engine")t5_trt_decoder_engine = T5DecoderONNXFile(os.path.join(onnx_model_path, decoder_onnx_model_fpath), metadata).as_trt_engine(os.path.join(tensorrt_model_path, decoder_onnx_model_fpath) + ".engine")
t5_trt_encoder = T5TRTEncoder(t5_trt_encoder_engine, metadata, tfm_config)t5_trt_decoder = T5TRTDecoder(t5_trt_decoder_engine, metadata, tfm_config)#generate outputencoder_last_hidden_state = t5_trt_encoder(input_ids=input_ids)outputs = t5_trt_decoder.greedy_search(input_ids=decoder_input_ids,encoder_hidden_states=encoder_last_hidden_state,stopping_criteria = StoppingCriteriaList([MaxLengthCriteria(max_length)]))print(tokenizer.decode(outputs[0], skip_special_tokens=True))
TensorRT vs PyTorch CPU、PyTorch GPU
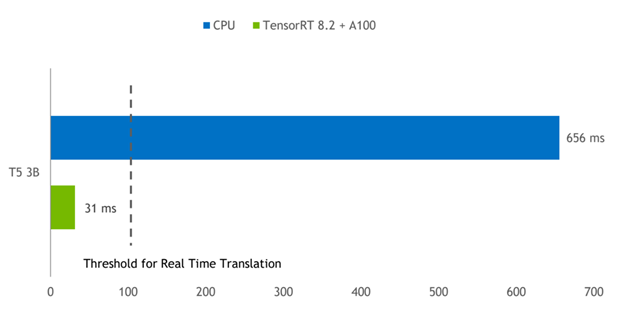
参考资料:
https://developer.nvidia.com/blog/nvidia-announces-tensorrt-8-2-and-integrations-with-pytorch-and-tensorflow/?ncid=so-twit-314589#cid=dl13_so-twit_en-us
https://developer.nvidia.com/blog/accelerating-inference-up-to-6x-faster-in-pytorch-with-torch-tensorrt/
https://developer.nvidia.com/blog/optimizing-t5-and-gpt-2-for-real-time-inference-with-tensorrt/
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
评论