
用户路径分析之利器“桑基图”
大家好,我是宝器!
本文约4千字,读完需要20分钟,后半部分有实操,可以拿出小本本练习。
引言
作为一名产品经理,我们经常会听到这样的描述:
“用户进入xx页面后,点击这里,跳转到xx页面,然后再点击xxx 跳转到xx页面。”
产品是这样设计的,但是用户是否真如你设计的那样走?
未必。
那么用户到底是怎么使用产品的,真实世界中的用户的旅程是什么样子,你需要一张桑基图。名字听起来有些陌生? 没关系,本文就带你走一遭,讲讲桑基图的前世今生,桑基图在互联网产品分析领域的应用, 以及如何用python将一个常见埋点数据CSV文件做出漂亮的桑基图。
桑基图的前世
提起桑基图,要感谢以下这两个人,可以说是桑基图的爷爷和爸爸。左图是:查尔斯.约瑟夫.米纳德,法国工程师,数据可视化大师;右图是: 马修·亨利·菲尼亚斯·里亚尔·桑基,爱尔兰人,蒸汽机引擎设计工程师。

(图片来源于网络)
1869年,查尔斯·米纳德(Charles Minard)绘制了《1812年拿破仑东征图》。这张图形象的描绘了拿破仑在1812到1813年进攻俄国时所遭受的灾难性损失。

图中黄色为进军路线,黑色为撤退路线,线条的宽度代表拿破仑的军队人数变化,从图中可以清楚的看到,在深入寒冷的俄国腹地时,拿破仑军队的人数在逐渐的减少,到黑色线条撤退返回时,线条细的都快看不见了(活着返回法国的只有1万余人)。这张图也被认为是“数据可视化”的经典之作。
然而,让桑基图广泛应用于科学工程领域的,还是要感谢马修·亨利·菲尼亚斯·里亚尔·桑基(Matthew Henry Phineas Riall Sankey)。桑基图(Sankey chart)也是以此人命名。1898年,桑基在一篇描述能量效率的文章中画了这样一张图。
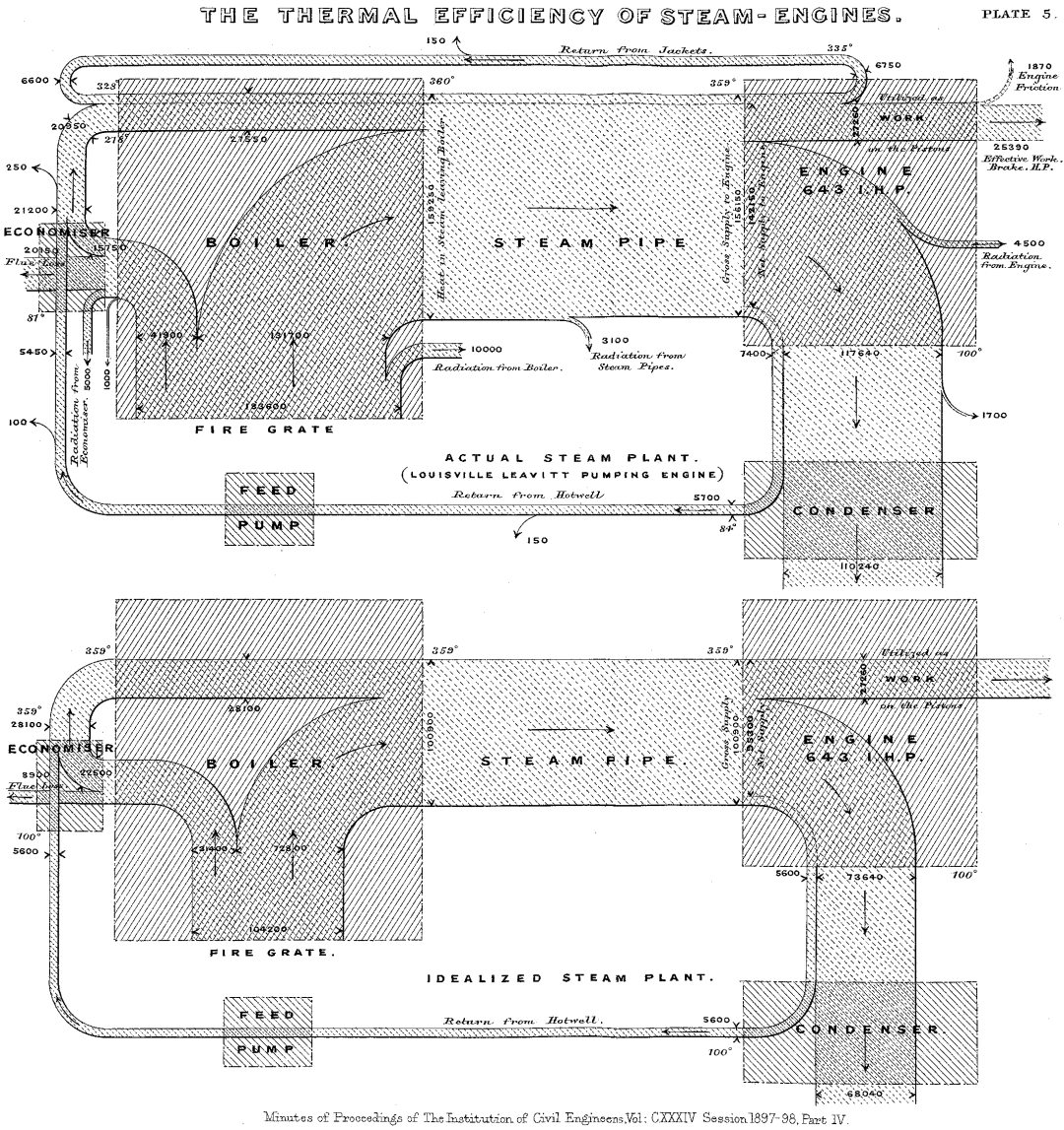
在文中,他对这张图是这样解释的:当能量在蒸汽机的各个部件中传输时,都会有能量损失,要提高能量传递效率,需要知道哪些步骤中流失比较严重。热量传递如下图箭头所示,其中箭头的宽度代表能量的大小,可以从图中看到每个步骤中能量损失。
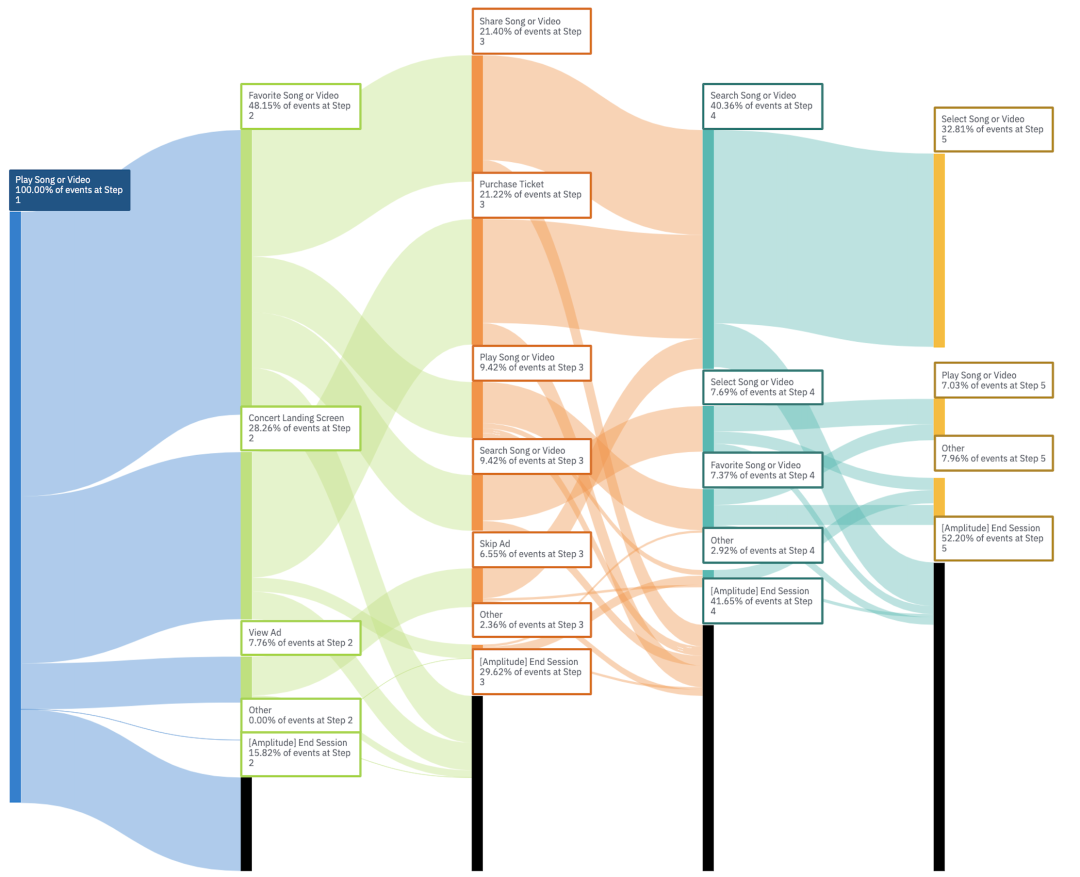
从此以后桑基图被应用于各个领域,比如农业领域中追溯农产品的走向,社会学领域研究人口的流向,医学领域研究病例发展的流向。 而在互联网产品中,桑基图也被广泛采纳,主要用于用户路径分析。比如,用户在首页开始,分别流向了哪些页面,之后又流向了哪里。以下图为例,非常直观的表现了用户从Play song or video开始向其他页面的流转以及过程中的跳失量(跳失量由黑色表示)。
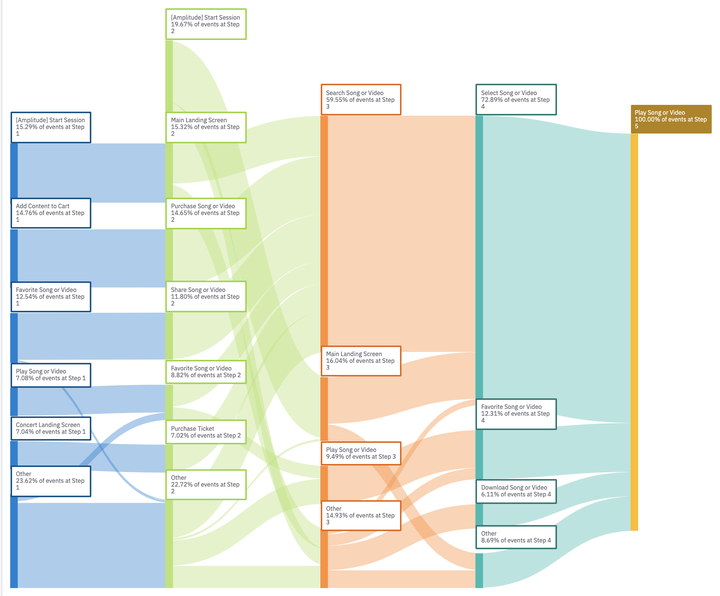
自然而然,我们不由的要提一个问题,有时候我们也想知道,达到某页面或者执行某行为的用户都从哪里来,于是就有了桑基图的变种,可以理解为“逆向桑基图”。 即设定一个终点,看看用户从哪里来,如下图所示。
可以看到,桑基图能非常直观的展现用户旅程,尤其是用户旅程纷繁复杂的时候,桑基图能很直观的表现出用户的使用习惯,帮助我们了解用户行为,从而进一步提高产品体验。根据个人经验,桑基图可以在以下几个方面提高产品和用户的契合度:
1. 找到主流流程,帮助确定转化漏斗中的关键步骤。
2. 看用户主要流向了哪里,发现用户的兴趣点,寻找新的机会。
3. 发现被用户忽略的产品价值点,修正价值点曝光方式。
4. 发现用户的流失点。
5. 找到有价值的用户群体。
2.1. 找到主流流程,帮助确定转化漏斗中的关键步骤。
比如下图(仔细看图)中,我们将每一步占比最高的流程摘出来,得到最最主流的步骤,即Play Song or Video -> Favorite Song or Video -> Share Song or Video -> Search Song or Video -> Select Song or Video。
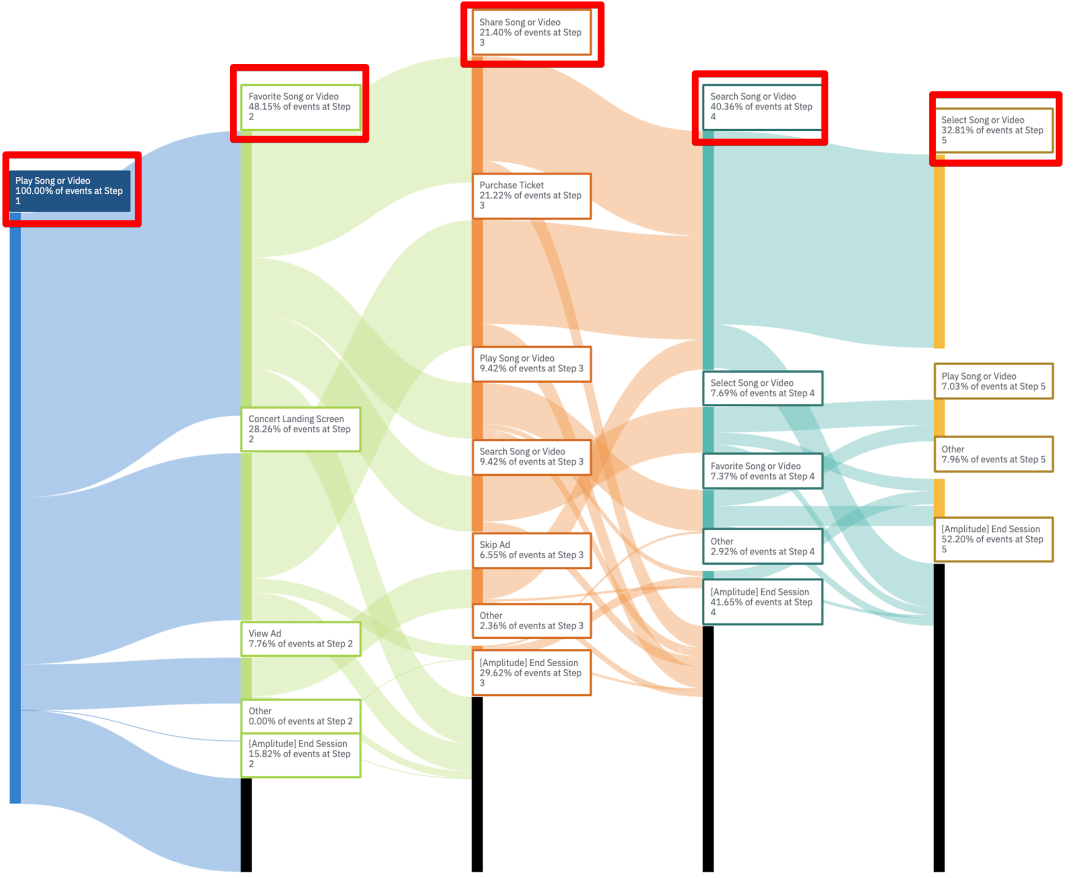
2.2.发现被用户忽略的产品价值点,修正价值点曝光方式。
在上图中,我们发现执行了Seach song 的用户持续走到下一步的可能性会更大,然而在第二步并没有search song 操作,在第三步,也只有9.48%的用户选择了search song,是不是可以考虑加强Search song功能的曝光。
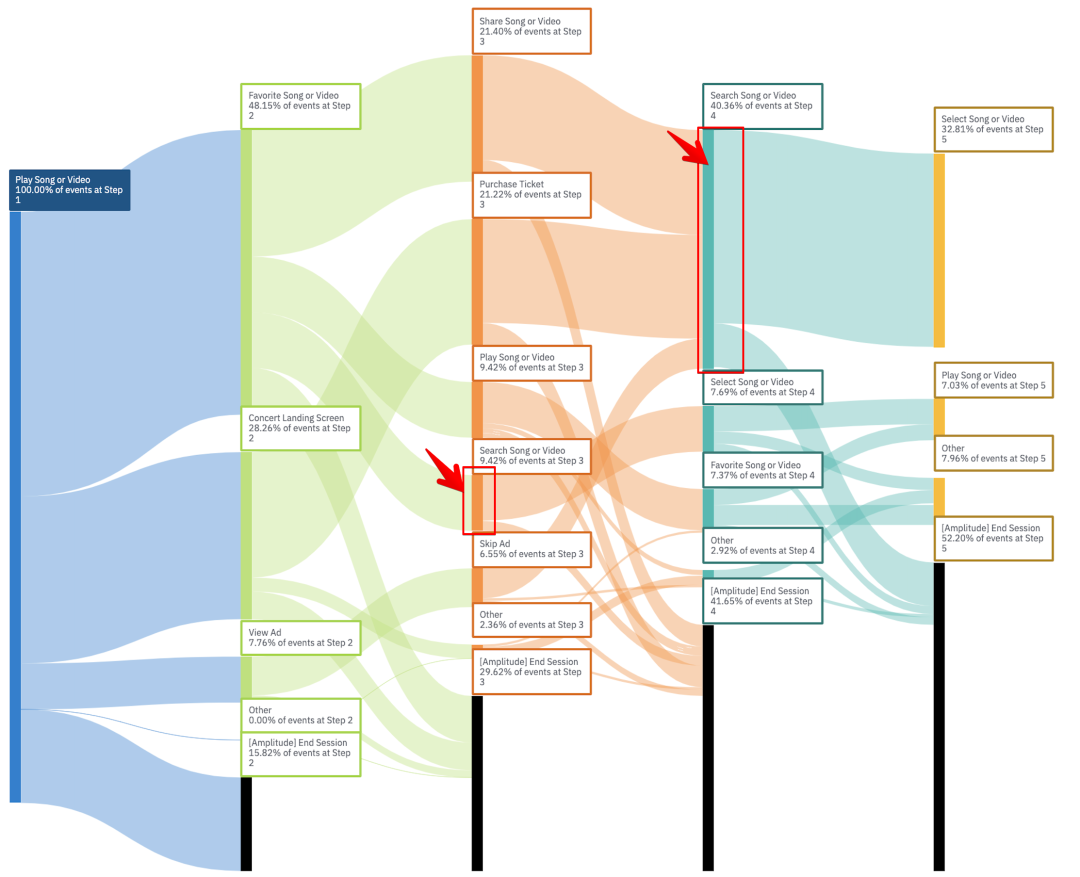
2.3. 看用户主要流向了哪里,发现用户的兴趣点,寻找新的机会。
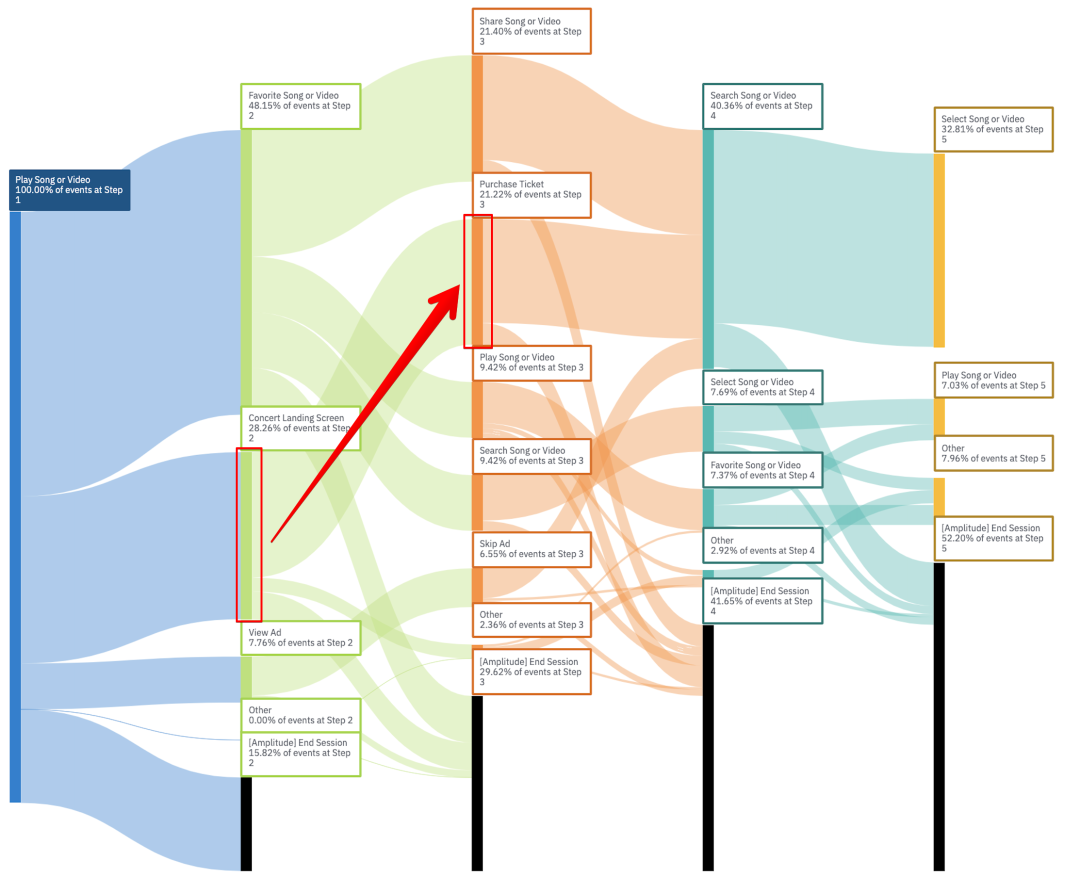
比如上图中,我们发现Concert landing Screen中执行Purchase ticket动作的比例高达75.13%, 可以看出用户是对Concert landing Screen到Purchase ticket的转化率是极高的,可以发现用户对Purchase Concert ticket的兴趣是很高的,后续产品可以考虑增强这一块的投入。
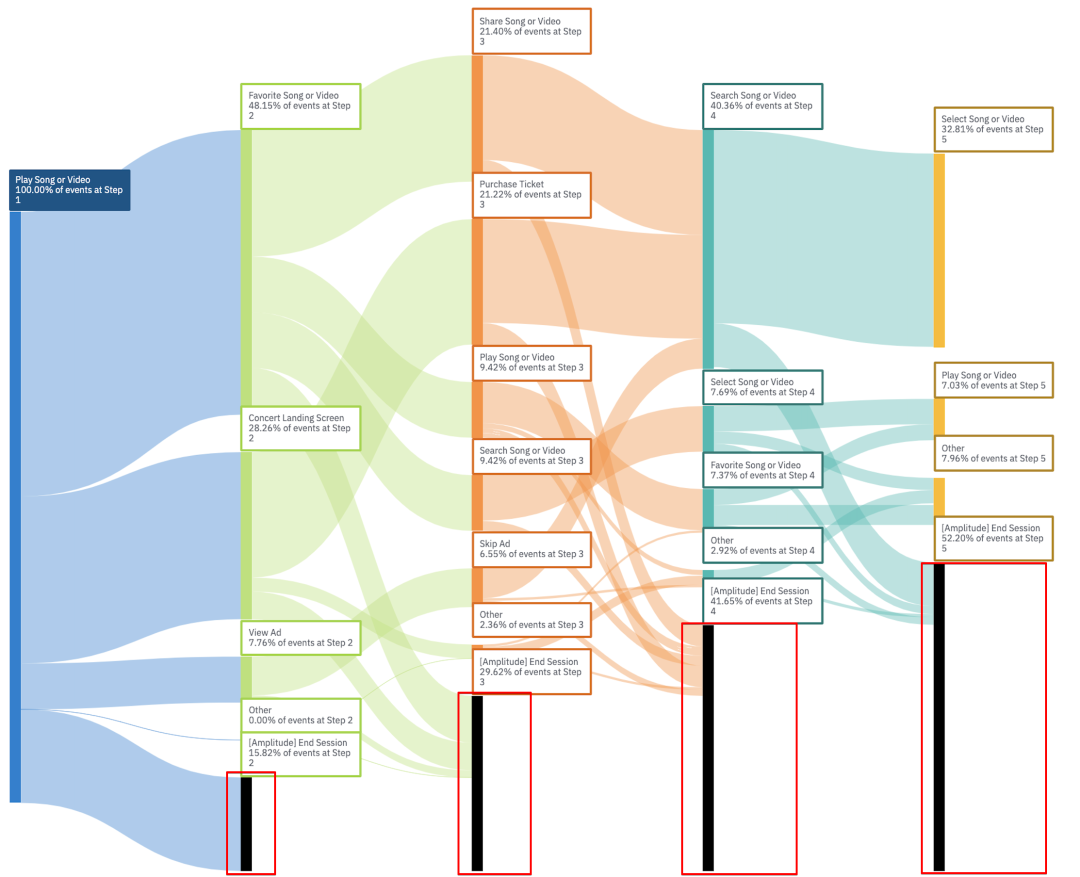
2.4. 发现用户的流失点
上图可以看出,每一步用户的累计跳失率是:15.82%, 29.61%, 41.64%, 52.19%, 每一步的净跳失率就是:
15.82%,13.79%(29.61%-15.82%),12.03%(41.64%-29.61%),10.55%(52.19%-41.64%)
第一步的的跳失率是最高的,结合之前的分析,产品侧可以考虑通过search song来降低跳失率。
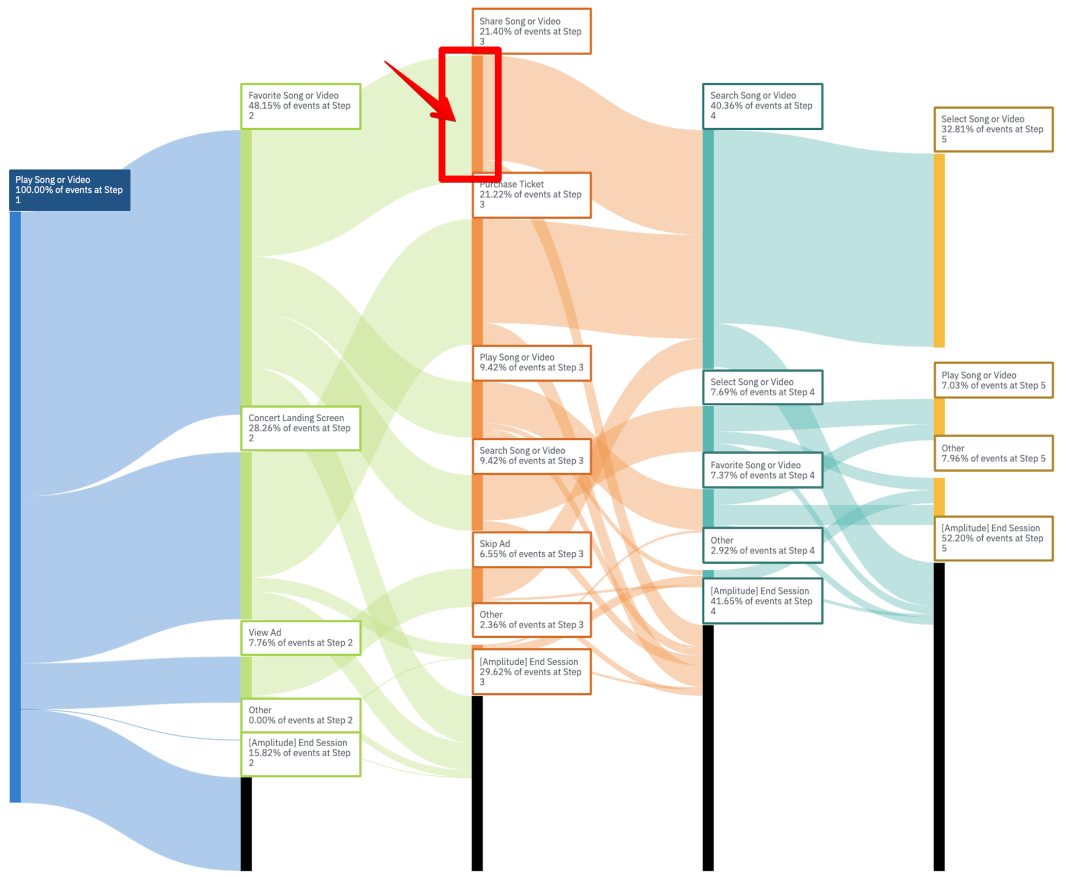
2.5. 寻找新的价值潜力点
share song是app实现裂变拉新的一个渠道。我们可以看到share song之后的群体一大部分去了Search song,但是search song之后,却没有share song,到底是因为search song 没有快捷分享通道,还是因为用户不愿意分享,就要结合具体情况分析了。是不是可以在search song后鼓励用户分享,达到拉新的目的。
当然,桑基图主要适用于用户路径相对复杂的应用,如果只是简单路径的分析,则有点大炮打苍蝇的感觉了。
桑基图这么好,那么桑基图怎么做呢?首先来剖析一下桑基图的组成,桑基图想要表达的是流向问题,那么就需要知道从哪里(起点)到哪里(终点)---流了多少(流量),这句话中有三个要素,我个人称之为点、线、面:
1. 点:即流向的起点和终点。
2. 线:即哪些起点和终点间有流量。
3. 面:这些的量有多大(用面宽表示)。
以我的知乎文章页面为例,我想知道进入到文章页面的人都流向了哪里, 这里我把知乎页面做了简化,假设该页面只有以下三个链接。
那么这里
点就是:
起点:知乎个人主页文章
终点:是A文章, B 文章, C文章。
线就是:
主页 --->A文章
主页 --->A文章
主页 --->A文章
假设到A、B、C文章的人数分别是100、200、300,那么面(宽)就是100、200、300。所以要做出桑基图,就是寻找点、线、面的问题。
目前市面上有很成熟的工具做出桑基图,比如神策数据的用户路径分析就可以完成。但如果没有成熟的工具支持,我们只能自己动手、丰衣足食了,不过前提是需要有完备的埋点数据,如果连埋点都没有,只能是巧妇难为无米之炊,快快把自己项目的埋点体系建立起来[参考文章:数据人该知道的埋点体系]。接下来我们就看一下如何从最原始的埋点数据中自己动手造出桑基图。
以下内容比较枯燥,需要大家仔细看图,也可以准备好小本本写一写、画一画。
如下图,我们的PV(Page visits)埋点原始数据(已做脱敏处理)有三列(其他不相关的列已隐藏):
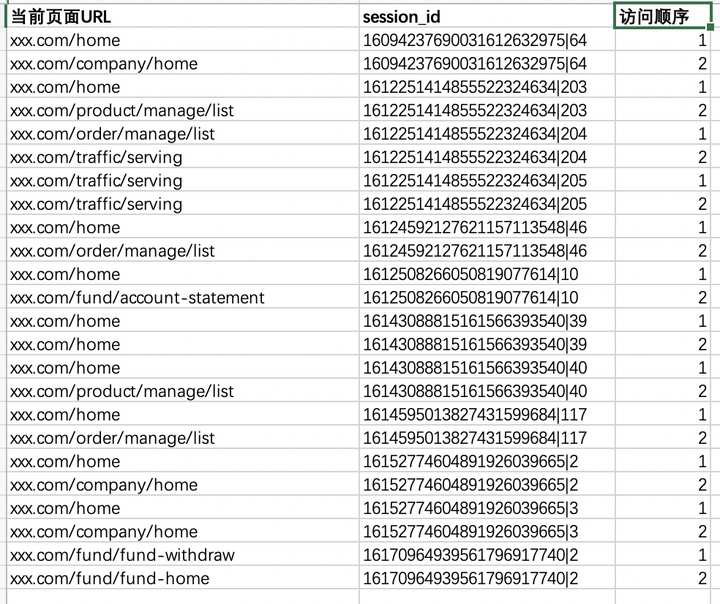
表格中的几列分别是:
当前页面的URL: 即有哪些起点或者终点。
session_id: 用于确认属于同一会话的PV页面访问。关于session(会话)的定义自行百度
访问顺序:即同一会话中页面访问的顺序。
举个例子,表格前两行的意思是某次会话中(16094237690031612632975|64)用户第一次访问的页面是xxx.com/home,第二次访问的页面是:xxx.com/company/home。

我们来从这个表中找到点、线、面
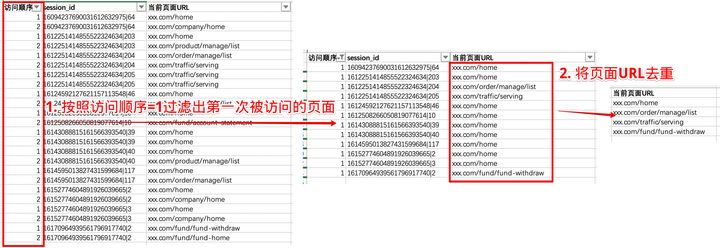
点:
以起点为例,我们需要找到用户第一次访问的页面都有哪些?,那么用excel过滤出访问顺序==1的页面,去重,就得到第一次被访问的页面的集合。
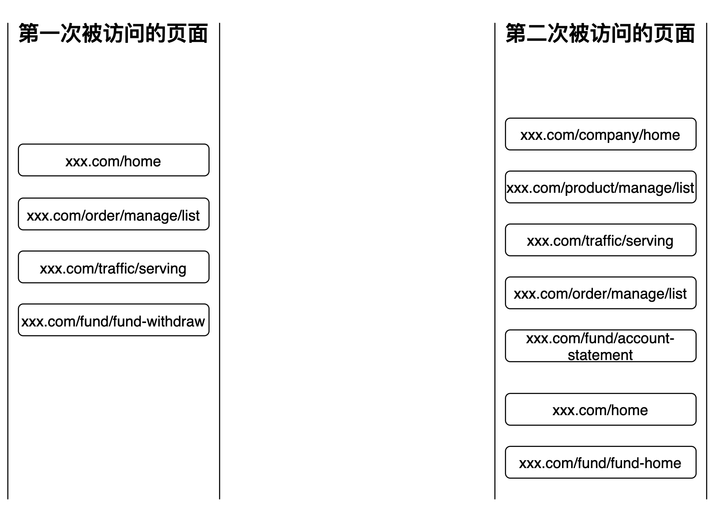
同理得出第二次被访问的页面的集合。这样就得到了头两次被访问的页面节点:
线&面:
接下来我们需要知道两个步骤节点之间是否有联系。以第一个页面xxx.com/home为例,需要知道第一次访问页面xxx.com/home,并且第二次访问xxx.com/company/home有几个session。这其实就是一个数学集合问题, 先找到以xxx.com/home为第一次访问页面的sessionID集合A, 再找到以xxx.com/company/home为第二次访问页面的sessionID集合B, 取集合A和集合B的交集中元素的个数,就得到这个“面”的宽度,即流量。照此,我们可以得出第一次访问页面xxx.com/home,并且第二次访问xxx.com/company/home有3个session, 如下图:
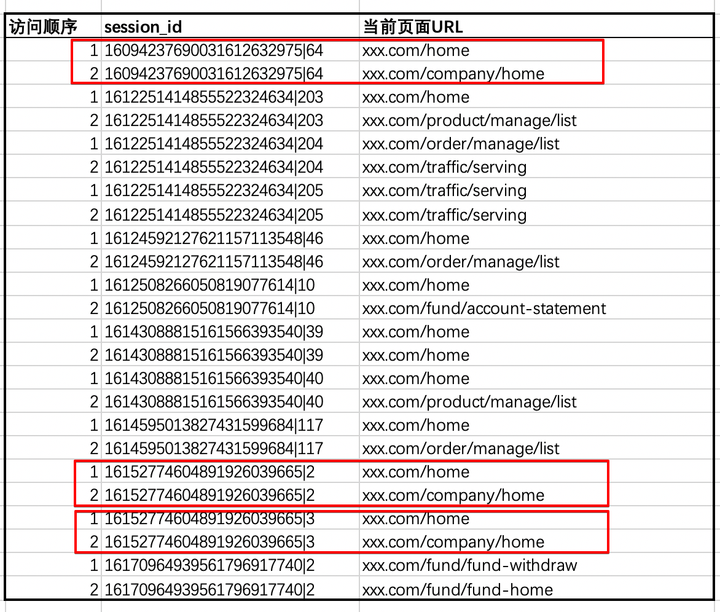
那么这两个页面之间的连接就是3。
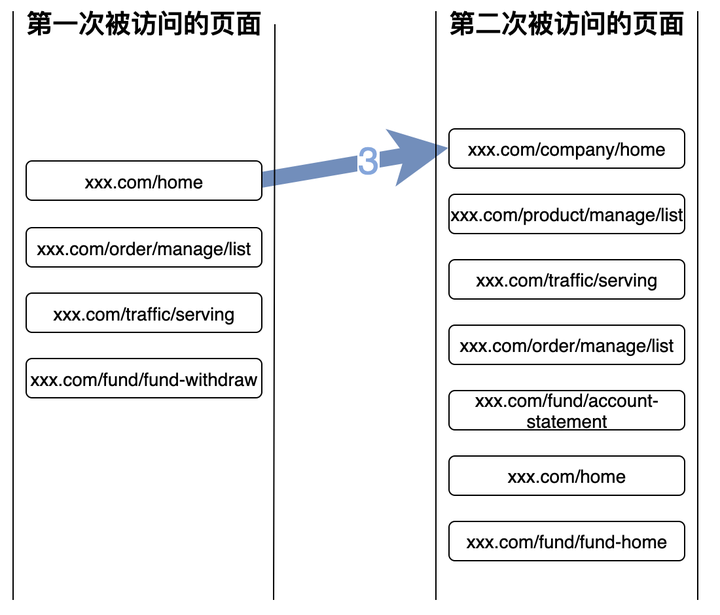
以此类推,得到以xxx.com/home为起点的session,对这些session中,第二次被访问的页面进行计数,就可以得到对应的访问流量分布,如下图:
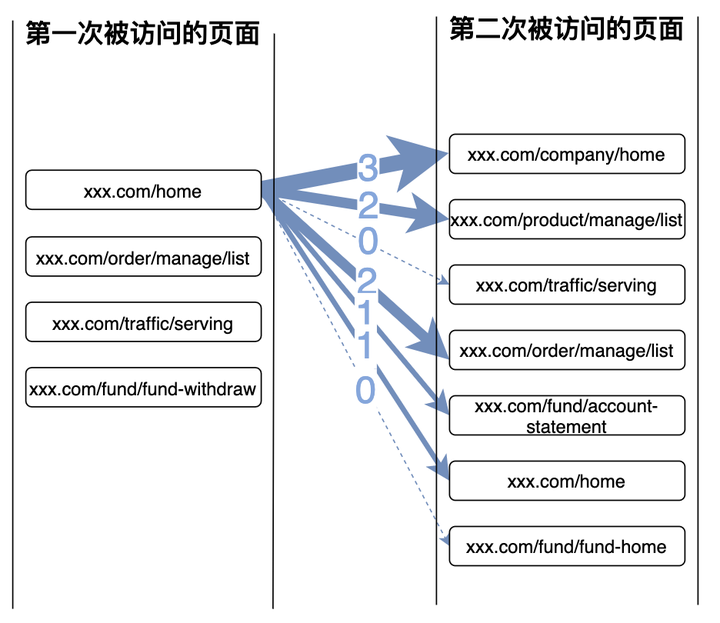
同理,再分别计算出以xxx.com/order/manage/list, xxx.com/traffic/serving, xxx.com/fund/fund-withdraw 为起点的流量分布,从而得出一张不怎么好看的桑基图:
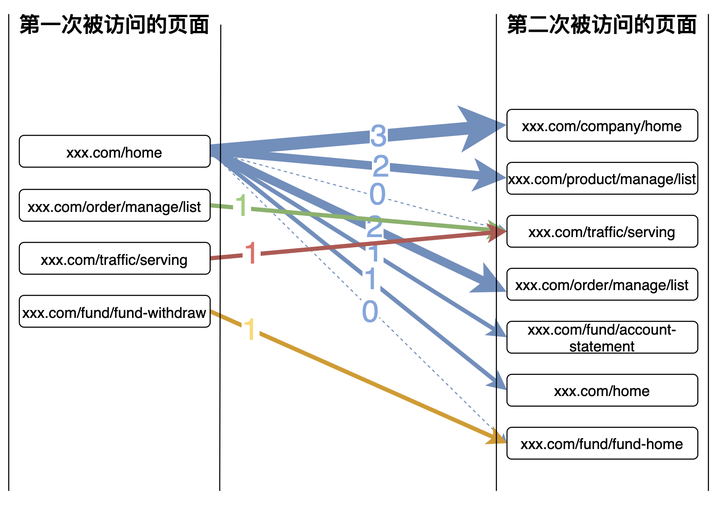
而这张图的背后就是如下的数据:其中traffic就是对应的流量大小,也就是桑基图中线的宽度。
这样,意味着我们要实现源数据到桑基图数据的转化:

接下来我们就用python 代码实现这一转变。
用Python实现桑基图
1. 点:
#读取PV数据filepath = '/Users/jigege/Desktop/sankey/PV_data.csv'pvData = pd.read_csv(filepath)#获取前两步桑基图的节点,首先定义一个数组,数组元素是每一步对应的节点数组SankeyNodes = []#作为示意,我们仅考虑访问顺序==1和2的数据for i in range(2):#过滤出访问顺序为i的页面,用drop_duplicates()去重得到节点SankeyNodes.append(pvData[pvData['Sequence'] == i+1]['CurrentPage'].drop_duplicates().values)SankeyNodes
得到桑基图点的数组如下:
[array(['xxx.com/home', 'xxx.com/order/manage/list','xxx.com/traffic/serving', 'xxx.com/fund/fund-withdraw'],dtype=object),array(['xxx.com/company/home', 'xxx.com/product/manage/list','xxx.com/traffic/serving', 'xxx.com/order/manage/list','xxx.com/fund/account-statement', 'xxx.com/home','xxx.com/fund/fund-home'], dtype=object)]
2. 获取线&面
#获取桑基图的线&面#初始化桑基图数据,列名分别为'source':流量起点,'target':流量终点,'traffic':流量大小sankeyTraffic =pd.DataFrame(columns = ['source','target','traffic'])#遍历第一步的节点for i in range(len(SankeyNodes[0])):#得出第一步中各个节点对应的session_id列表sourceSessionList = pvData[(pvData['CurrentPage']==SankeyNodes[0][i])&(pvData['Sequence']==1)]['session_id']#遍历第二步的节点for j in range(len(SankeyNodes[1])):#得出第二步中各个节点对应的session_id列表targetSessionList = pvData[(pvData['CurrentPage']==SankeyNodes[1][j])&(pvData['Sequence']==2)]['session_id']#算出同时访问过第一个页面和第二个页面的session个数,即为流量;用isin函数判断第二个页面的session列表是否在第一个页面的session列表中Traffic = targetSessionList.isin(sourceSessionList)[lambda x: x==True].count()#用append函数将算出的'source':流量起点,'target':流量终点,'traffic':流量大小添加到桑基图数据中sankeyTraffic=sankeyTraffic.append({'source':SankeyNodes[0][i],'target':SankeyNodes[1][j],'traffic':Traffic}, ignore_index=True)
3. 绘制桑基图
#绘制桑基图有两个包,一个是pyecharts.charts, 另外一个是holoviews,我们选择了holoviews。#但holoviews不允许source 和target当中有重复项,所以将source和target分别加上后缀,避免两列中的重复项sankeyTraffic['source'] = sankeyTraffic['source'].apply(lambda x: x+'_source')sankeyTraffic['target'] = sankeyTraffic['target'].apply(lambda x: x+'_target')#引入相关的python 包,需要预先安装holoviews,plotly等packageimport holoviews as hvimport plotly.graph_objects as goimport plotly.express as pex#导入对应的扩展组件hv.extension('bokeh')#绘制桑基图,一步完成!hv.Sankey(sankeyTraffic,kdims=["source", "target"], vdims=["traffic"] )
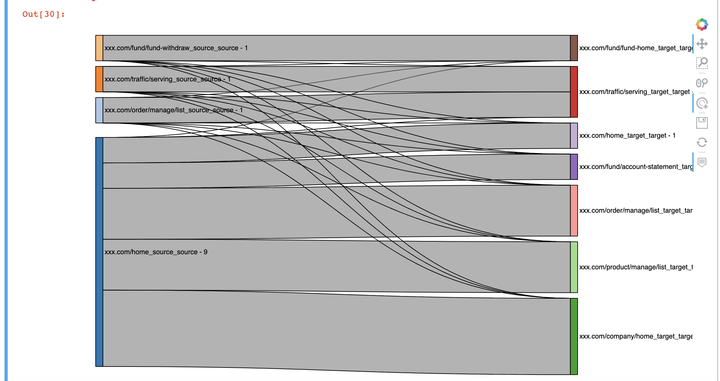
当然,如果你有兴趣,在一个最简单的只描述的一步的桑基图完成之后,可以探寻更加完整复杂的多步桑基图。其实原理都是一样的,本文就不再赘述,大家也可以参考文章:How to Plot Sankey Diagram in Python Jupyter Notebook [holoviews & plotly]? by Sunny Solanki(https://coderzcolumn.com/tutorials/data-science/how-to-plot-sankey-diagram-in-python-jupyter-notebook-holoviews-and-plotly)
总结
今天我们从桑基图的前世今生讲起,聊了聊桑基图在互联网中研究用户路径的应用,以及业务价值,最后讲了桑基图的绘制原理和python实操。在桑基图的绘制原理和python实操部分,是有点枯燥的,甚至需要大家拿出小本本在纸上画一画,写一写,仔细看看所附的图片,然后上手练习一下。如果你们的工作中有现成的桑基图工具,本文可以帮你知道桑基图是怎么来的,如果没有,试试今天的方法,做出一个酷酷的桑基图来扩大你的影响力吧!
参考文章
1. 维基百科:http://en.wikipedia.org/wiki/Sankey_diagram
2.google charts: https://developers.google.com/chart/interactive/docs/gallery/sankey
3. How to Plot Sankey Diagram in Python Jupyter Notebook [holoviews & plotly]
4. 利用Python绘制诱人的桑基图_数据森麟-CSDN博客
5. Amplitude help center:Get the most out of Amplitude's Funnel Analysis chart
6. the art of consequences

推荐阅读
欢迎长按扫码关注「数据管道」