
用“讲故事”的方式,带你认识 Python 编码问题的起源和发展!
阅读本文大概需要 3 分钟。
问题起源
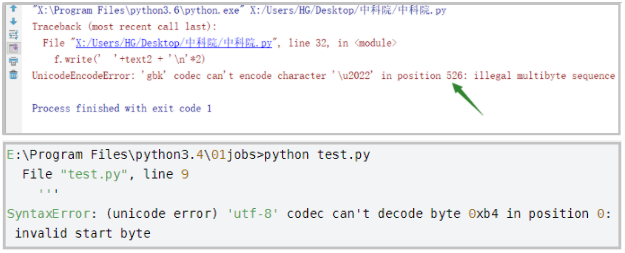
我们在学习Python的过程中,可能会经常遇到下方这样的编码问题。有时候我们需要选择gbk,有时候需要选择utf-8。你以为这样就完了吗?我们碰到的还有gb2312,gb18030等各种奇奇怪怪的编码。那么,编码的起源究竟是怎样的呢?我们今天就用“讲故事”的方式,带你认识一下它。
故事环节1)烽火士兵的故事
在正式讲故事之前,我们先来看一下下方这张图,我们暂且称其为《烽火士兵》的故事,那么这个故事究竟是怎么与编码问题扯上联系的呢?接着听我讲故事。

点燃第1根,代表有一个士兵,点燃第2根,代表有二个士兵。那么也就是说,点燃2个烽火,最多可以表示三个士兵。梳理一下逻辑,1个烽火都不点,表示有零个士兵;只点燃第1个烽火,就表示有一个士兵;在点燃第2个烽火的时候,熄灭第1个烽火,就表示有二个士兵;同时点燃2个烽火,就表示有三个士兵。
综上所述:2根烽火,可以表示:0、1、2、3个士兵,即1+2。3根烽火,可以表示:0、1、2、3、4、5、6、7个士兵,即1+2+4。依此类推下去…

通过上面的叙述,你可能已经发现了,这不就是类似计算机里面的二进制数字吗?只有0和1,0表示熄灭烽火,1表示点燃烽火。对应到计算机中就是,0表示关,1表示开。下面黄同学就带着大家说一下“计算机中的0和1”。
计算机的底层是电路,只认识0和1,就是你初中物理中所谓的“电路”,0表示关,1表示开,没有别的玩意儿。但是你想呀,一个电路只有0和1的话,怎么展示出这绚丽多彩的世界呢?因此,聪明的老外,把日常所用的文字和符号,编码成0101010…类型,这样电脑就能够表示文字了。所以,先记住一个关键语:“用什么编码,就用什么解码”。
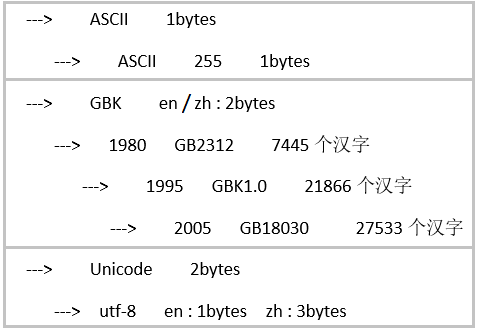
由于,计算机是由美国人发明的。因此,最早的计算机编码:ASCII码(也是服务于美国人的),里面只有美国人日常所用的26个英文字母、数字、标点等常用字符,所以,最早的计算机也只有英文、数字、标点等特殊字符。不要惊叹为啥只有美国人常用的英文字母和符号,因为老美当时就没有想过计算机会迅速在全世界普及开来,谁也不能提前预知未来。
接着我们来说说最早的计算机编码:ASCII码。ASCII码占8个比特位,也就是一个字节,其中最前面一个位是扩展位,都是0,为了日后扩展所用,其余位置不是0就是1。这是由于计算机对数字7不敏感,熟悉2、4、8、16、32...等数字,所以扩展了一位,成了8位。那么根据排列组合的知识,ASCII码可以表示2^7=128个码位,即可以表示128种不同的符号,其实这些符号已经够美国人使用了。这就是当时最早的计算机编码(ASCII码),这就是当时老美的打算。

2)计算机在中国的发展
随着计算机在世界各地的发展,我们发现原有的码位已经不够存放多国的文字和符号了,为了讲清楚这件事儿,我们以计算机在中国的发展为例,进行说明。
通过前面的叙述,我们已经知道最早的字符编码ASCII码中,并没有中文,但是随着计算机在中国的普及,我们必要要让计算机中能够表示中文呀,怎么办呢?基于此:中国北大方正团队,发明了gbk编码。但是这些字符肯定不能直接往ASCII码里面放,因为ASCII只有8位,最多才有2^8=256个空位,存放九万多汉字,显然不可能(就连中文中常用的3000汉字,也存放不了)。所以在gbk中,汉字用2个字节表示,变成了ASCII码中字节长度的2倍,即gbk占16位,共2^16=65536个空位,这个对于存放常用汉字,多得多,但是,仍然不能将所有汉字存放进去,谁让中华文化源远流长,博大精深呢。

说到gbk,就不得不说它的兄弟姐妹了(如图所示),其实它们是一个系列,都是由于当时的需要,逐步衍生出来的,这三种不同的编码都是向上兼容的。可以看出:GB18030表示的字符数最多,这也就是为什么有时候使用Python读取Excel表时,使用GB2312和GBK都不行,而必须使用GB18030的原因了。

3)计算机如何兼容多国语言
计算机不仅在中国发展开来,其实计算机是在全世界迅速发展开来。如果说中国有自己独有的GBK编码,那么韩国、日本肯定也有它们自己独有的编码。但是当今是“经济全球化”的时代,任何一个国家都不可能的单独发展,假如你有一个国际合作的业务,我们在中国写的代码,要是想拿到国外去用,出现乱码,这样多尴尬?那么这个问题最终是怎么解决的呢?

为此,美国人又发明了一个叫做“Unicode”的东西,又叫做“万国码”。其实完全可以见名知意,万国码万国码,肯定是为了包含全世界的字符编码!那么什么是万国码呢?接着听黄同学给你讲。

我们知道:计算机扩展一般是成倍增加的,要么是1个字节、2个字节、4个字节......。最开始的Unicode,又叫ucs-2,ASCII存储采用1个字节,因此ucs-2采用2个字节进行存储,最多有2^16=65536个空位,这样仍然无法兼容全世界的字符。于是ucs-4产生了,存储采用4个字节,共2^32=4亿多个空位。但是据统计,全世界文字、数字、符号信息加起来也就23万,对于4亿多空间来说,ucs-4简直太浪费空间了,这个对于文件传输来说,及其浪费流量。
考虑到节省空间,在Unicode基础上,我们又发明了utf-8,一种可变长的Unicode字符编码。Utf-8,对于英文来说,采用ASCII码占位方式,占8位,即1个字节;存放欧洲文字时,占16位,即2个字节;存放中文时,占24位,即3个字节。虽然对于中文来说很浪费空间,但是为了能把全世界文字都统一起来,又为了节省空间,采用这种方式,已经很好了(因为毕竟不可能做到面面俱到,谁让中国字符最多,会吃亏一点)。
编码知识总结
1)字符编码发展史
2)以小写字母a为例,说明字符编码

3)带着大家写写代码,认识一下字符编码
① 关于Python2和Python3的区别
在Python2中,默认字符编码是ASCII码,因此在Python2中写中文,首行一般都会加上-- coding:utf-8 --,看了这篇文章,我想你对这个东西已经有了一个清楚的认识。但是Python2现在已经停止更新了,我们了解即可,不用太关注。
对于Python3.x来说,默认字符编码是utf-8,而utf-8是Unicode的扩展集。即Python3.x中默认所有的字符都是Unicode。说白点,我们在Python3.x中随便写点啥,编码就是Unicode编码。
对比Python2和Python3:
# 在Python2中如果要表示Unicode编码,应该这样写。
my_name = u"黄伟"
# 在Python3中如果要表示Unicode编码,应该这样写。
my_name = "黄伟"说到这里,我们可以下一个结论:不同编码之间的转换,都要经过一个Unicode。
② encode编码和decode解码
>>> name1 = "我是你们的teacher老师"
>>> name2 = "你们是我的student学生"
>>> # 将name1编码为“utf-8”
>>> name1_encode = name1.encode("utf-8")
>>> name1_encode
b'\xe6\x88\x91\xe6\x98\xaf\xe4\xbd\xa0\xe4\xbb\xac\xe7\x9a\x84teacher\xe8\x80\x81\xe5\xb8\x88'
>>> # 将name1_encode解码还原
>>> name1_encode.decode("utf-8")
'我是你们的teacher老师'
---------------------------------------------------------
>>> # 将name2编码为“gbk”
>>> name2_encode = name2.encode("gbk")
>>> name2_encode
b'\xc4\xe3\xc3\xc7\xca\xc7\xce\xd2\xb5\xc4student\xd1\xa7\xc9\xfa'
>>> # 将name2_encode解码还原
>>> name2_encode.decode("gbk")
'你们是我的student学生'
-------------------------------------------------
>>> # name1_encode此时是“utf-8”编码,如果用“gbk”解码,会出现什么?
>>> name1_encode.decode("gbk")
'鎴戞槸浣犱滑鐨則eacher鑰佸笀'
# 上面就是我们常说的乱码、乱码、乱码!代码分析:从代码中可以看出,如果是utf-8编码,每个中文字符就是3个字节存储。如果是gbk编码,每个中文字符就是2个字节存储。
推荐阅读
1
2
3
4
崔庆才
静觅博客博主,《Python3网络爬虫开发实战》作者
隐形字
个人公众号:进击的Coder


长按识别二维码关注