Abstract
尽管最近半监督学习的研究在利用标记和未标记数据方面有显著进步,但大多数假设模型的基本设置是随机初始化的。
因此本文将半监督学习和迁移学习相结合提出了一种半监督的转移学习框架,该方法不仅能利用目标域(目标任务数据集)中的标记/未标记数据,还能利用源域(具有不同语义的通用数据集,如:ImageNet)中的预训练模型。为了更好地利用预训练权重和未标记目标数据,我们引入了自适应一致性正则化,它由两个互补组件组成:源模型和目标模型之间的示例上的自适应知识一致性(AKC),以及自适应表示一致性(ARC) ),在目标模型上标记和未标记的示例之间,根据它们对目标任务的潜在贡献,自适应地选择一致性正则化中涉及的示例。
通过微调ImageNet预训练的ResNet-50模型,我们在几个流行的基准上进行了广泛的实验,包括CUB-200-2011,MIT Indoor-67,MURA。结果表明,我们提出的自适应一致性正则化性能优于最新的半监督学习技术,例如Pseudo Label,Mean Teacher和MixMatch。此外,我们的算法能与现有方法共同使用,因此能够在MixMatch和FixMatch之上获得其他改进。
本文的主要贡献包含以下三点:
1、第一个提出用于深度神经网络的半监督转移学习框架2、利用半监督学习和转移学习的特性引入自适应一致性正则化来改善半监督转移学习3、实验结果表明所提出的自适应一致性正则化性能优于最新的半监督学习技术
02
The Proposed Framework
在本节中,我们将详细提出的半监督转移学习框架。该框架的流程图如图1所示:
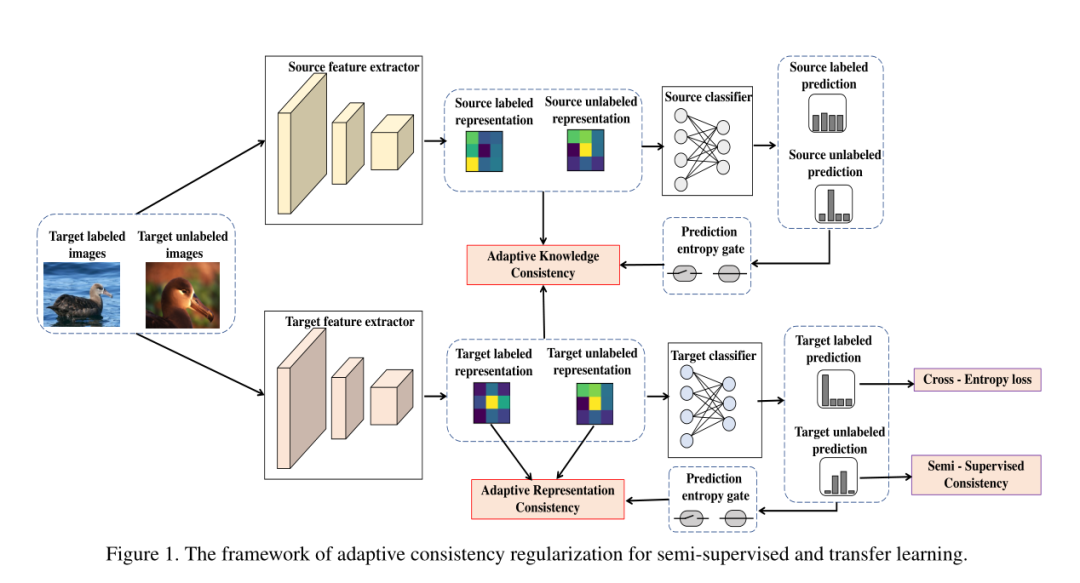
Problem definition:
在知识转移学习中,我们有对应于不同任务的源数据集 和目标数据集 。深度学习模型一般分为两个部分:representation function 和task-specific function ,如果在具有不同语义的数据集上进行训练,则 能够包含基本知识,因此可以传递。而 具有关于任务属性(例如类数)的特定体系结构。源域数据集定义为 ,我们将 的参数(在任务中称为feature extractor)和 (在任务中称为classifier)的参数分别预先设置为 和 。对于目标数据集, 我们定义 为目标域有标记数据, 为目标域无标记数据, 目标域数据集 大小为n+m。为了解决目标任务,我们确定了优化的一般形式: 其中 表示cross-entropy loss,R 指与预训练参数 , 和目标数据集相关的正则项。
2.1 Pre-training and Imprinting
我们采用一种常用的策略来实现迁移学习,即依次从源和目标数据集中学习。第一步是预培训。用 初始化目标模型的表示参数(注意不要 的参数与 混淆)。我们从源模型的特征提取器 获得的知识为目标模型提供了更好的起点,并立即具有良好的分类性能。
2.2 Adaptive Knowledge Consistency我们通过 输出的特征表示提取源模型的知识,而不是特定于任务 输出的预测,因为 不适合处理不同的任务。我们将标记和未标记的数据作为桥梁知识转移并施加自适应样本的重要性权重,以防止在两个数据集之间由于差异引起负转移。具体来说,我们在整个目标数据集上限制了预训练特征提取器 和目标特征提取器 之间的加权KL散度(或均方误差)。在我们的设置中,我们将 表示为min-Batch的有标签数据 ,而 表示为min-Batch的无标签数据 。 因此,min-Batch的正则化项可以写成: 其中样本的重要性 计算方法如下,将目标示例 前馈至预训练模型,然后获得通过softmax运算后的最终输出,标记为 。 是一维向量,其长度等于源数据集类别Cs的数量。我们得到样本xi的权重 为: 其中 是二进制阈值函数(低于阈值为0,高于为1), 为阈值。我们认为较高的输出置信度意味着输入样本更有可能落入源模型的信任区域,因此,有关该样本的知识对于目标模型是可靠的。2.3 Adaptive Representation Consistency
在这一部分中,我们引入了另一个的正则化器,称为自适应表示一致性(Adaptive Representation Consistency),通过该正则化器,可以解决过拟合有标签目标样本的问题。由于未标记的样本包含有关数据结构的潜在信息,因此我们利用未标记的目标样本来帮助标记的样本学习具有更强泛化能力的表示。我们使用经典指标最大平均差异(MMD)来衡量标记数据的特征表示 和未标记数据特征表示 之间的距离 。MMD计算方式, 和 分别定义为标记数据集 和 无标记数据集 的分布,因此 和 之间的MMD最大平均差异计算如下: 其中 是指 kenel,在公式中 采用Gaussian radialbasis function (RBF)。 的计算,为了克服目标模型在训练过程的早期阶段对样本特征表示是不准确的,因此不能直接使用标记数据的特征表示 和未标记数据特征表示 的MMD来计算,我们采用了一种与自适应知识一致性相似的自适应样本选择方法。具体来说,我们以样本为输入来计算softmax输出的entropy,并将entropy作为目标模型对该样本的置信度。仅使用可信样本来规范标记数据的表示形式。具体操作如下,将带标签的示例 (和无标签的示例 )前馈至目标模型,并获得最终输出 (和 ),然后考虑预定义的阈值 ,通过将预测熵计算为 (和 )来获得样本的门状态(无论是否选择)。将选择的有标签数据特征表示的集合表示为 并将选择的无标签数据特征表示的集合表示为 : 注意,随着目标模型逐渐适合更多的训练示例,样本选择的结果会自适应地变化。考虑到mini-batch中所选样本的数量可能不足以计算确定的分布,因此我们设置了一个重播缓冲区以保存最近选择的置信样本。重播缓冲区使我们能够使用更多数据来计算MMD,这有助于通过最近的一些迷你批处理表示分布来近似表示完整的表示分布。重放缓冲区的伪代码如下所示:
定义 和 表示是根据 和 生成的特征表示分布,因此我们可以得到自适应表示一致性(Adaptive Representation Consistency):
2.4 Summarization of the Framework
我们最终提出了完整的自适应一致性由AKC和ARC组成的正则化为 如果我们将交叉熵损失LCE用于标记数据,将半监督一致性损失LS用于未标记数据(就像MixMatch,FixMatch,Pseudo-labeling),则最终损失函数将变为: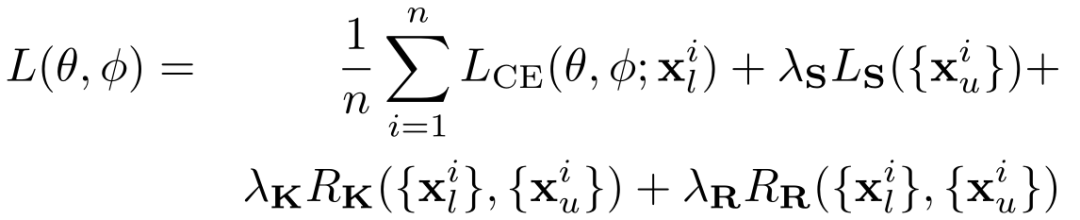
03
实验结果
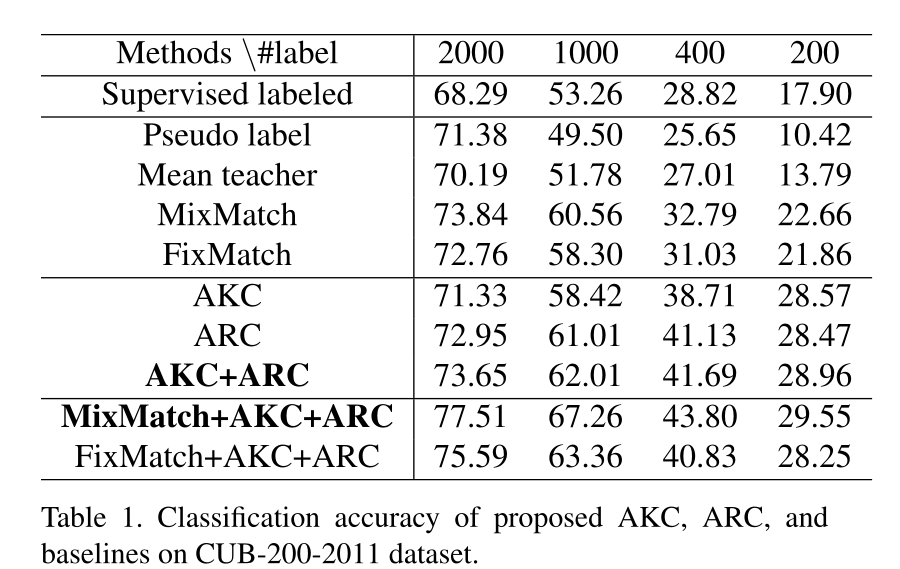
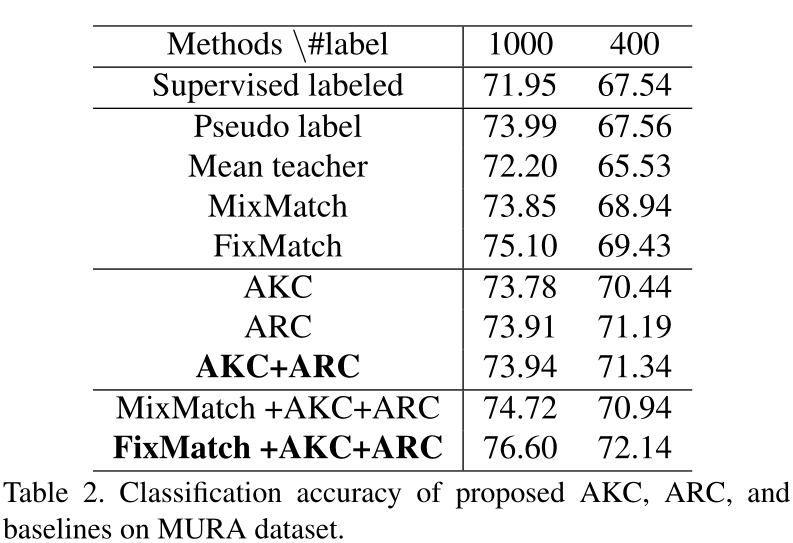
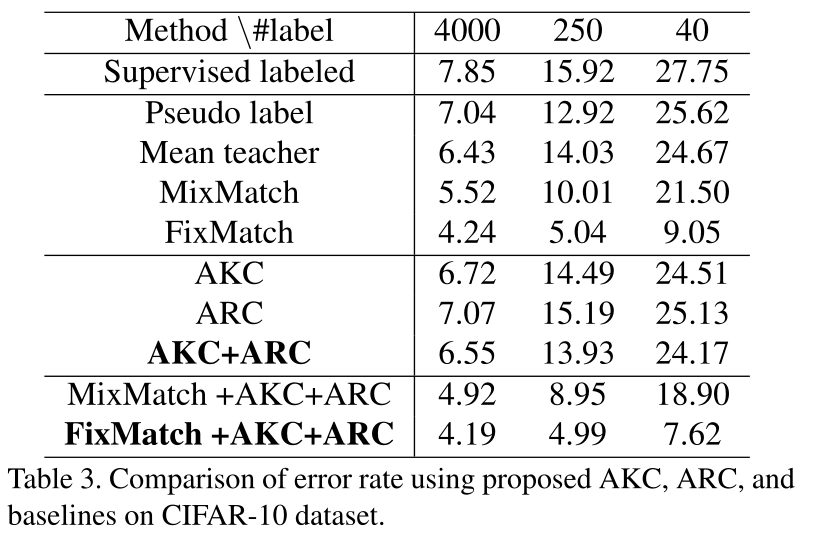
通过微调ImageNet预训练的ResNet-50模型,我们将提出的自适应一致性正则化方法与以下最新的半监督学习方法在多个数据集(CUB-200-2011,MIT Indoor-67,MURA)上进行了比较:
04
总结
在这篇文章中提出了两种正则化方法:源模型和目标模型之间的自适应知识一致性(AKC)以及带标签的示例和未带标签的示例之间的自适应表示一致性(ARC)。实验证明AKC和ARC在最新的SSL方法之间具有竞争力。此外,通过将AKC和ARC与其他SSL方法结合使用,我们可以在各种迁移学习基准上的几种基准方法中获得最佳性能。✄------------------------------------------------
欢迎微信搜索并关注「目标检测与深度学习」,不被垃圾信息干扰,只分享有价值知识!
目前10000+人已加入目标检测与深度学习
敬最努力的我们! 
