
腾讯阿里头条翻牌子 | ClickHouse中SQL执行过程
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源

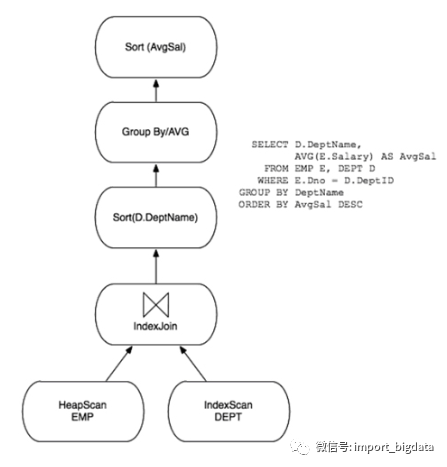
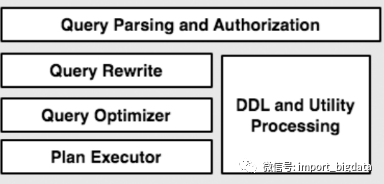
用户提交一条查询SQL背后发生了什么?
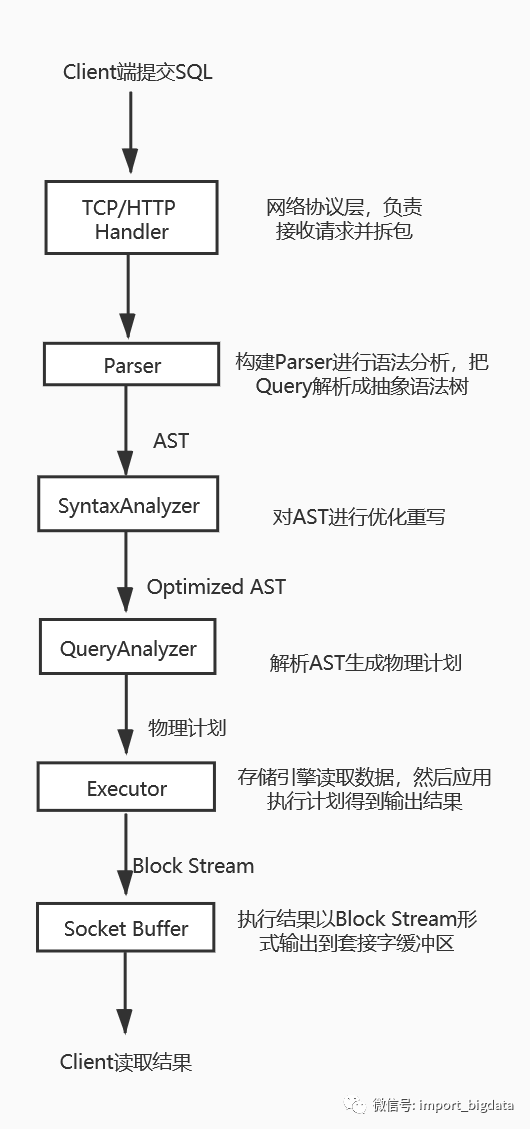
接收客户端请求
初始化上下文
初始化Zookeeper(ClickHouse的副本复制机制需要依赖ZooKeeper)
常规配置初始化
绑定服务端的端口,根据网络协议初始化Handler,对客户端提供服务
int Server::main()
{
// 初始化上下文
global_context = std::make_unique<Context>(Context::createGlobal());
global_context->setApplicationType(Context::ApplicationType::SERVER);
// zk初始化
zkutil::ZooKeeperNodeCache main_config_zk_node_cache([&] { return global_context->getZooKeeper(); });
//其他config的初始化
//...
//绑定端口,对外提供服务
auto address = make_socket_address(host, port);
socket.bind(address, /* reuseAddress = */ true);
//根据网络协议建立不同的server类型
//现在支持的server类型有:HTTP,HTTPS,TCP,Interserver,mysql
//以TCP版本为例:
create_server("tcp_port", [&](UInt16 port)
{
Poco::Net::ServerSocket socket;
auto address = socket_bind_listen(socket, listen_host, port);
servers.emplace_back(std::make_unique<Poco::Net::TCPServer>(
new TCPHandlerFactory(*this),
server_pool,
socket,
new Poco::Net::TCPServerParams));
});
//启动server
for (auto & server : servers)
server->start();
}
初始化输入和输出流的缓冲区
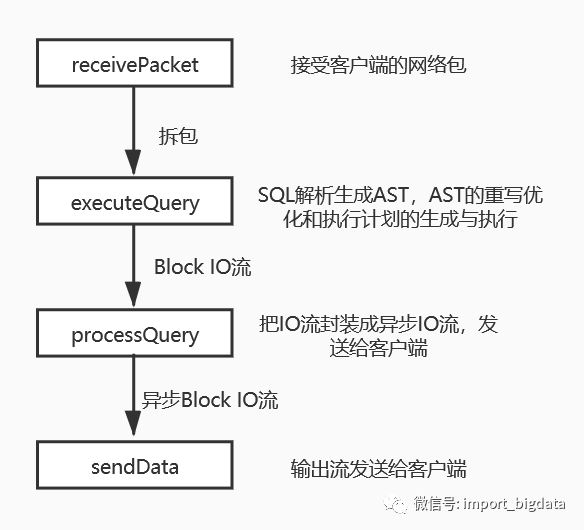
接受请求报文,拆包
执行Query(包括整个词法语法分析,Query重写,物理计划生成和生成结果)
把Query结果保存到输出流,然后发送到Socket的缓冲区,等待发送回客户端
void TCPHandler::runImpl()
{
//实例化套接字对应的输入和输出流缓冲区
in = std::make_shared<ReadBufferFromPocoSocket>(socket());
out = std::make_shared<WriteBufferFromPocoSocket>(socket());
while (1){
// 接收请求报文
receivePacket();
// 执行Query
state.io = executeQuery(state.query, *query_context, false, state.stage, may_have_embedded_data);
//根据Query种类来处理不同的Query
//处理insert Query
processInsertQuery();
//并发处理普通Query
processOrdinaryQueryWithProcessors();
//单线程处理普通Query
processOrdinaryQuery();
}
}
static std::tuple<ASTPtr, BlockIO> executeQueryImpl()
{
//构造Parser
ParserQuery parser(end, settings.enable_debug_queries);
ASTPtr ast;
//把Query转化为抽象语法树
ast = parseQuery(parser, begin, end, "", max_query_size);
//生成interpreter实例
auto interpreter = InterpreterFactory::get(ast, context, stage);
// interpreter解析AST,结果是BlockIO
res = interpreter->execute();
//返回结果是抽象语法树和解析后的结果组成的二元组
return std::make_tuple(ast, res);
}
构建Parser,把Query解析成AST(抽象语法树)
InterpreterFactory根据AST生成对应的Interpreter实例
AST是由Interpreter来解析的,执行结果是一个BlockIO,BlockIO是对 BlockInputStream 和 BlockOutputStream 的一个封装。
服务端调用 executeQuery 来处理client发送的Query,执行后的结果保存在state这个结构体的io成员中。
每一条Query都会对应一个state结构体,记录了这条Query的id,处理状态,压缩算法,Query的文本和Query所处理数据对应的IO流等元信息。
然后服务端调用 processOrdinaryQuery 等方法把输出流结果封装成异步的IO流,发送到回client。
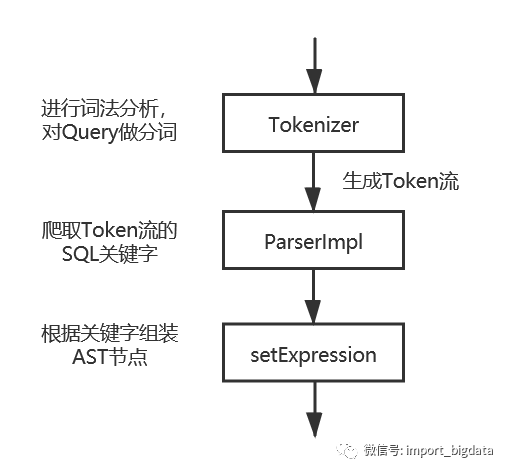
解析请求(Parser)
词法分析和语法分析的核心逻辑可以在parseQuery.cpp的 tryParseQuery 中一览无余。
该函数利用lexer将扫描Query字符流,将其分割为一个个的Token, token_iterator 即一个Token流迭代器,然后parser再对Token流进行解析生成AST抽象语法树。
ASTPtr tryParseQuery()
{
//Token为lexer词法分析后的基本单位,词法分析后生成的是Token流
Tokens tokens(pos, end, max_query_size);
IParser::Pos token_iterator(tokens);
ASTPtr res;
//Token流经过语法分析生成AST抽象语法树
bool parse_res = parser.parse(token_iterator, res, expected);
return res;
}
bool ParserQuery::parseImpl(Pos & pos, ASTPtr & node, Expected & expected)
{
ParserQueryWithOutput query_with_output_p(enable_explain);
ParserInsertQuery insert_p(end);
ParserUseQuery use_p;
ParserSetQuery set_p;
ParserSystemQuery system_p;
bool res = query_with_output_p.parse(pos, node, expected)
|| insert_p.parse(pos, node, expected)
|| use_p.parse(pos, node, expected)
|| set_p.parse(pos, node, expected)
|| system_p.parse(pos, node, expected);
return res;
}
bool ParserSelectQuery::parseImpl(Pos & pos, ASTPtr & node, Expected & expected)
{
//创建AST树节点
auto select_query = std::make_shared<ASTSelectQuery>();
node = select_query;
//select语句中会出现的关键词
ParserKeyword s_select("SELECT");
ParserKeyword s_distinct("DISTINCT");
ParserKeyword s_from("FROM");
ParserKeyword s_prewhere("PREWHERE");
ParserKeyword s_where("WHERE");
ParserKeyword s_group_by("GROUP BY");
ParserKeyword s_with("WITH");
ParserKeyword s_totals("TOTALS");
ParserKeyword s_having("HAVING");
ParserKeyword s_order_by("ORDER BY");
ParserKeyword s_limit("LIMIT");
ParserKeyword s_settings("SETTINGS");
ParserKeyword s_by("BY");
ParserKeyword s_rollup("ROLLUP");
ParserKeyword s_cube("CUBE");
ParserKeyword s_top("TOP");
ParserKeyword s_with_ties("WITH TIES");
ParserKeyword s_offset("OFFSET");
//...
//依次对Token流爬取上述关键字
ParserTablesInSelectQuery().parse(pos, tables, expected)
//根据语法分析结果设置AST的Expression属性,可以理解为如果SQL存在该关键字,这个关键字都会转化为AST上的一个节点
select_query->setExpression(ASTSelectQuery::Expression::WITH, std::move(with_expression_list));
select_query->setExpression(ASTSelectQuery::Expression::SELECT, std::move(select_expression_list));
select_query->setExpression(ASTSelectQuery::Expression::TABLES, std::move(tables));
select_query->setExpression(ASTSelectQuery::Expression::PREWHERE, std::move(prewhere_expression));
select_query->setExpression(ASTSelectQuery::Expression::WHERE, std::move(where_expression));
select_query->setExpression(ASTSelectQuery::Expression::GROUP_BY, std::move(group_expression_list));
select_query->setExpression(ASTSelectQuery::Expression::HAVING, std::move(having_expression));
select_query->setExpression(ASTSelectQuery::Expression::ORDER_BY, std::move(order_expression_list));
select_query->setExpression(ASTSelectQuery::Expression::LIMIT_BY_OFFSET, std::move(limit_by_offset));
select_query->setExpression(ASTSelectQuery::Expression::LIMIT_BY_LENGTH, std::move(limit_by_length));
select_query->setExpression(ASTSelectQuery::Expression::LIMIT_BY, std::move(limit_by_expression_list));
select_query->setExpression(ASTSelectQuery::Expression::LIMIT_OFFSET, std::move(limit_offset));
select_query->setExpression(ASTSelectQuery::Expression::LIMIT_LENGTH, std::move(limit_length));
select_query->setExpression(ASTSelectQuery::Expression::SETTINGS, std::move(settings));
}
执行请求(Interpreter)
std::unique_ptr<IInterpreter> InterpreterFactory::get(ASTPtr & query, Context & context, QueryProcessingStage::Enum stage)
{
//举个例子,如果该AST是由select语句转化过来,
if (query->as<ASTSelectQuery>())
{
/// This is internal part of ASTSelectWithUnionQuery.
/// Even if there is SELECT without union, it is represented by ASTSelectWithUnionQuery with single ASTSelectQuery as a child.
return std::make_unique<InterpreterSelectQuery>(query, context, SelectQueryOptions(stage));
}
}
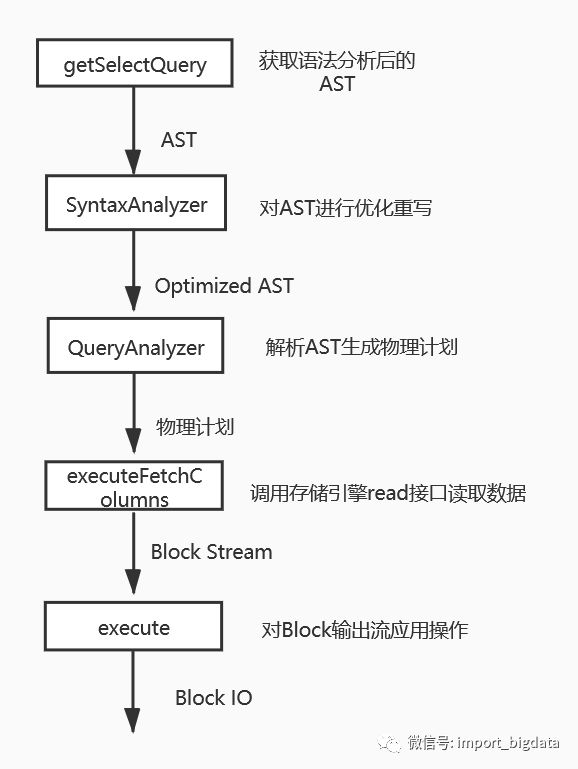
InterpreterSelectQuery::InterpreterSelectQuery()
{
//获取AST
auto & query = getSelectQuery();
//对AST做进一步语法分析,对语法树做优化重写
syntax_analyzer_result = SyntaxAnalyzer(context, options).analyze(
query_ptr, source_header.getNamesAndTypesList(), required_result_column_names, storage, NamesAndTypesList());
//每一种Query都会对应一个特有的表达式分析器,用于爬取AST生成执行计划(操作链)
query_analyzer = std::make_unique<SelectQueryExpressionAnalyzer>(
query_ptr, syntax_analyzer_result, context,
NameSet(required_result_column_names.begin(), required_result_column_names.end()),
options.subquery_depth, !options.only_analyze);
}
SyntaxAnalyzerResultPtr SyntaxAnalyzer::analyze()
{
// 剔除冗余列
removeDuplicateColumns(result.source_columns);
// 根据settings中enable_optimize_predicate_expression配置判断是否进行谓词下移
replaceJoinedTable(node);
// 根据settings中distributed_product_mode配置重写IN 与 JOIN 表达式
InJoinSubqueriesPreprocessor(context).visit(query);
// 优化Query内部的布尔表达式
LogicalExpressionsOptimizer().perform();
// 创建一个从别名到AST节点的映射字典
QueryAliasesVisitor(query_aliases_data, log.stream()).visit(query);
// 公共子表达式的消除
QueryNormalizer(normalizer_data).visit(query);
// 消除select从句后的冗余列
removeUnneededColumnsFromSelectClause(select_query, required_result_columns, remove_duplicates);
// 执行标量子查询,并且用常量替代标量子查询结果
executeScalarSubqueries(query, context, subquery_depth);
// 如果是select语句还会做下列优化:
// 谓词下移优化
PredicateExpressionsOptimizer(select_query, settings, context).optimize();
/// GROUP BY 从句的优化
optimizeGroupBy(select_query, source_columns_set, context);
/// ORDER BY 从句的冗余项剔除
optimizeOrderBy(select_query);
/// LIMIT BY 从句的冗余列剔除
optimizeLimitBy(select_query);
/// USING语句的冗余列剔除
optimizeUsing(select_query);
}
ExpressionActionsChain chain;
analyzer.appendWhere(chain);
chain.addStep();
analyzer.appendSelect(chain);
analyzer.appendOrderBy(chain);
chain.finalize();
void InterpreterSelectQuery::executeImpl(TPipeline & pipeline, const BlockInputStreamPtr & prepared_input)
{
// 对应Query的AST
auto & query = getSelectQuery();
AnalysisResult expressions;
// 物理计划,判断表达式是否有where,aggregate,having,order_by,litmit_by等字段
expressions = analyzeExpressions(
getSelectQuery(),
*query_analyzer,
QueryProcessingStage::FetchColumns,
options.to_stage,
context,
storage,
true,
filter_info);
// 从Storage读取数据
executeFetchColumns(from_stage, pipeline, sorting_info, expressions.prewhere_info, expressions.columns_to_remove_after_prewhere);
// eg:根据SQL的关键字在BlockStream流水线中执行相应的操作, 如where,aggregate,distinct都分别由一个函数负责执行
executeWhere(pipeline, expressions.before_where, expressions.remove_where_filter);
executeAggregation(pipeline, expressions.before_aggregation, aggregate_overflow_row, aggregate_final);
executeDistinct(pipeline, true, expressions.selected_columns);
}
void InterpreterSelectQuery::executeFetchColumns(
QueryProcessingStage::Enum processing_stage, TPipeline & pipeline,
const SortingInfoPtr & sorting_info, const PrewhereInfoPtr & prewhere_info, const Names & columns_to_remove_after_prewhere)
{
// 实例化Block Stream
auto streams = storage->read(required_columns, query_info, context, processing_stage, max_block_size, max_streams)
// 读取列对应的Block,并且组织成Block Stream
streams = {std::make_shared<NullBlockInputStream>(storage->getSampleBlockForColumns(required_columns))};
streams.back() = std::make_shared<ExpressionBlockInputStream>(streams.back(), query_info.prewhere_info->remove_columns_actions);
}
BlockIO InterpreterInsertQuery::execute()
{
// table为存储引擎接口
StoragePtr table = getTable(query);
BlockOutputStreamPtr out;
// 从存储引擎读取Block Stream
auto query_sample_block = getSampleBlock(query, table);
out = std::make_shared<AddingDefaultBlockOutputStream>(
out, query_sample_block, out->getHeader(), table->getColumns().getDefaults(), context);
//执行结果封装成BlockIO
BlockIO res;
res.out = std::move(out);
}
using StoragePtr = std::shared_ptr< IStorage>;
while(true){
Block block;
//从IO流读取block数据
block = async_in.read();
//发送block数据
sendData(block);
}
void TCPHandler::sendData(const Block & block)
{
//初始化OutputStream的参数
initBlockOutput(block);
// 调用BlockOutputStream的write函数,把Block写到输出流
state.block_out->write(block);
state.maybe_compressed_out->next();
out->next();
}
结语

评论