【机器学习与统计学】参数与非参数方法
来源:DeepHub IMBA 作者:Giorgos Myrianthous
介绍
Y = f(X) + ε
参数化方法
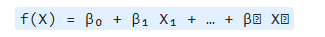
非参数方法
总结
本文内容转载来源以上网址及公众号。以上内容仅供学习使用,不作其它用途,如有侵权,请留言联系,作删除处理!
有任何疑问及建议,扫描以下公众号二维码添加交流:
评论
 下载APP
下载APP来源:DeepHub IMBA 作者:Giorgos Myrianthous
Y = f(X) + ε
本文内容转载来源以上网址及公众号。以上内容仅供学习使用,不作其它用途,如有侵权,请留言联系,作删除处理!
有任何疑问及建议,扫描以下公众号二维码添加交流: