
Google的「泛芯片」科技蓝图

新智元报道
新智元报道
来源:StarryHeavensAbove
编辑:直子
【新智元导读】Google自研芯片已经有几年时间,Jeff Dean也已经是芯片顶会邀请的常客。今年的Hotchips,Dan Belov(DeepMind)的keynote,阐述了Google对未来AI系统和芯片的看法,和来自Intel的keynote是完全不同的思路,这也代表了进入芯片领域的科技新贵和传统巨头站在不同的视角对于芯片设计未来的不同理解。
就在一天前,Raja M. Koduri在Hot Chips上介绍了Intel怎么实现到2025年把算力提升1000X,相信很多朋友都看过了,我就不多说了。

回到Dan Belov的keynote,同样在讲为了支持大规模AI研究,怎样实现1000X的算力提升。结合Google的背景,他很自然的强调系统而非单个芯片的优化,其中有一些观点值得我们思考。
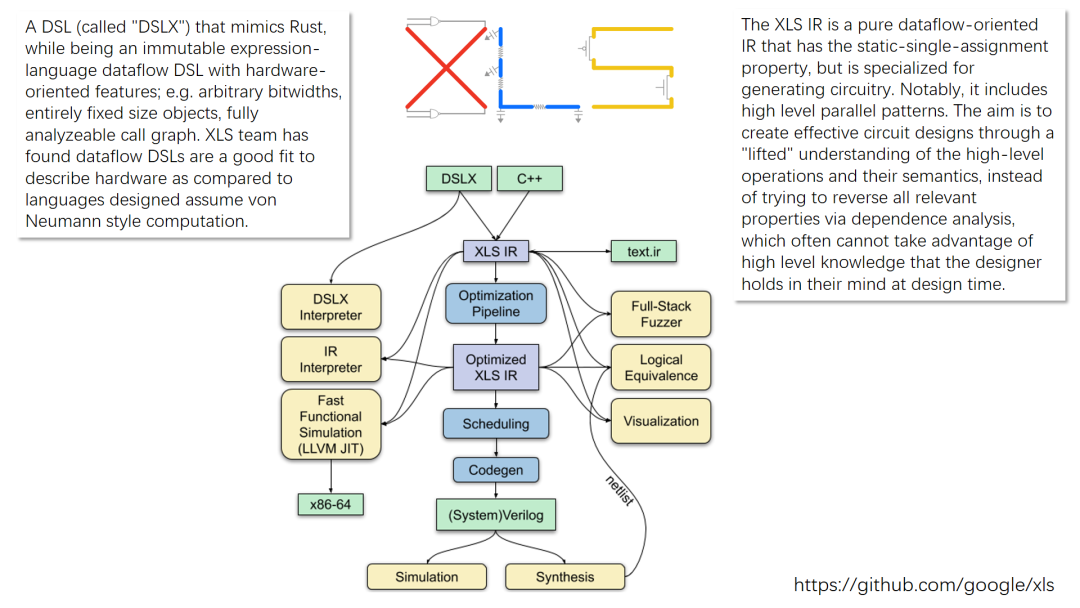
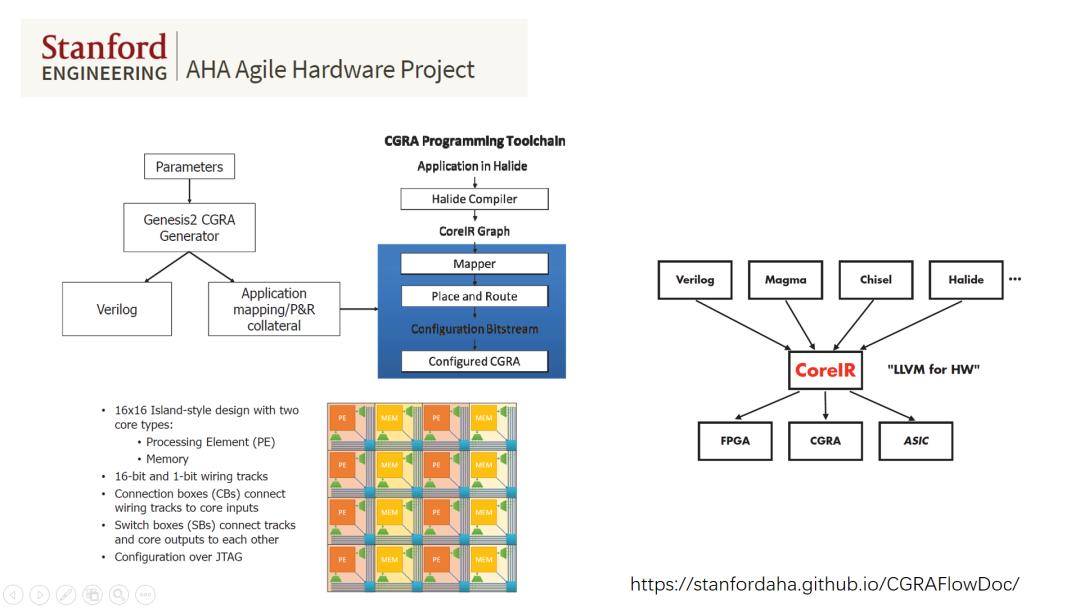


评论