
真实的产品案例:实现文档边缘检测

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
什么是边缘检测?
边缘检测是计算机视觉中一个非常古老的问题,它涉及到检测图像中的边缘来确定目标的边界,从而分离感兴趣的目标。最流行的边缘检测技术之一是Canny边缘检测,它已经成为大多数计算机视觉研究人员和实践者的首选方法。让我们快速看一下Canny边缘检测。
Canny边缘检测算法
1983年,John Canny在麻省理工学院发明了Canny边缘检测。它将边缘检测视为一个信号处理问题。其核心思想是,如果你观察图像中每个像素的强度变化,它在边缘的时候非常高。
在下面这张简单的图片中,强度变化只发生在边界上。所以,你可以很容易地通过观察像素强度的变化来识别边缘。

现在,看下这张图片。强度不是恒定的,但强度的变化率在边缘处最高。(微积分复习:变化率可以用一阶导数(梯度)来计算。)

Canny边缘检测器通过4步来识别边缘:
去噪:因为这种方法依赖于强度的突然变化,如果图像有很多随机噪声,那么会将噪声作为边缘。所以,使用5×5的高斯滤波器平滑你的图像是一个非常好的主意。 梯度计算:下一步,我们计算图像中每个像素的强度的梯度(强度变化率)。我们也计算梯度的方向。

非极大值抑制:现在,我们想删除不是边缘的像素(设置它们的值为0)。你可能会说,我们可以简单地选取梯度值最高的像素,这些就是我们的边。然而,在真实的图像中,梯度不是简单地在只一个像素处达到峰值,而是在临近边缘的像素处都非常高。因此我们在梯度方向上取3×3附近的局部最大值。

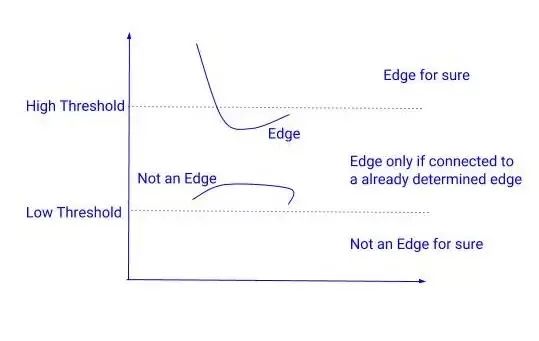
迟滞阈值化:在下一步中,我们需要决定一个梯度的阈值,低于这个阈值所有的像素都将被抑制(设置为0)。而Canny边缘检测器则采用迟滞阈值法。迟滞阈值法是一种非常简单而有效的方法。我们使用两个阈值来代替只用一个阈值:
高阈值 = 选择一个非常高的值,这样任何梯度值高于这个值的像素都肯定是一个边缘。
低阈值 = 选择一个非常低的值,任何梯度值低于该值的像素绝对不是边缘。
在这两个阈值之间有梯度的像素会被检查,如果它们和边缘相连,就会留下,否则就会去掉。
Canny 边缘检测的问题:
由于Canny边缘检测器只关注局部变化,没有语义(理解图像的内容)理解,精度有限(很多时候是这样)。
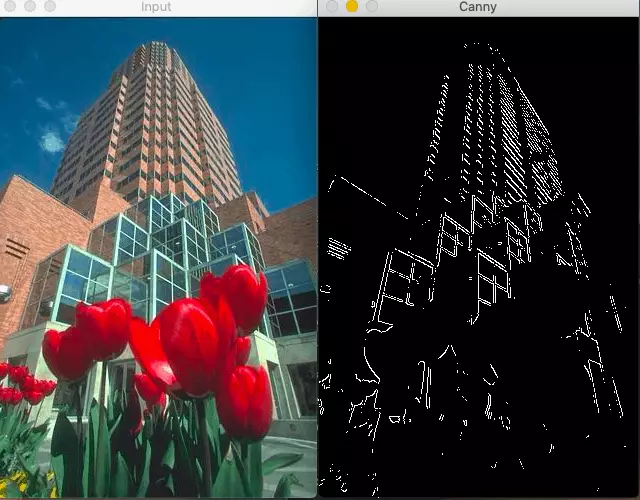
语义理解对于边缘检测是至关重要的,这就是为什么使用机器学习或深度学习的基于学习的检测器比canny边缘检测器产生更好的结果。
OpenCV中基于深度学习的边缘检测
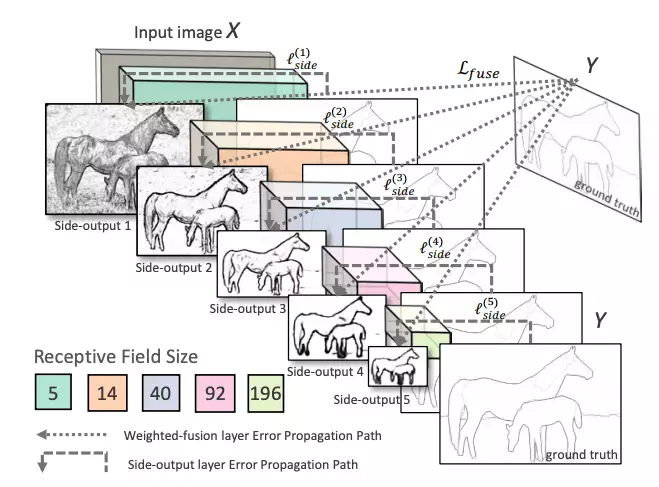
OpenCV在其全新的DNN模块中集成了基于深度学习的边缘检测技术。你需要OpenCV 3.4.3或更高版本。这种技术被称为整体嵌套边缘检测或HED,是一种基于学习的端到端边缘检测系统,使用修剪过的类似vgg的卷积神经网络进行图像到图像的预测任务。
HED利用了中间层的输出。之前的层的输出称为side output,将所有5个卷积层的输出进行融合,生成最终的预测。由于在每一层生成的特征图大小不同,它可以有效地以不同的尺度查看图像。
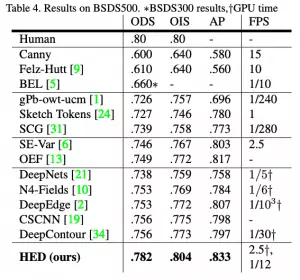
HED方法不仅比其他基于深度学习的方法更准确,而且速度也比其他方法快得多。这就是为什么OpenCV决定将其集成到新的DNN模块中。以下是这篇论文的结果:
在OpenCV中训练深度学习边缘检测的代码
OpenCV使用的预训练模型已经在Caffe框架中训练过了,可以这样加载:
sh download_pretrained.sh
网络中有一个crop层,默认是没有实现的,所以我们需要自己实现一下。
class CropLayer(object):
def __init__(self, params, blobs):
self.xstart = 0
self.xend = 0
self.ystart = 0
self.yend = 0
# Our layer receives two inputs. We need to crop the first input blob
# to match a shape of the second one (keeping batch size and number of channels)
def getMemoryShapes(self, inputs):
inputShape, targetShape = inputs[0], inputs[1]
batchSize, numChannels = inputShape[0], inputShape[1]
height, width = targetShape[2], targetShape[3]
self.ystart = (inputShape[2] - targetShape[2]) // 2
self.xstart = (inputShape[3] - targetShape[3]) // 2
self.yend = self.ystart + height
self.xend = self.xstart + width
return [[batchSize, numChannels, height, width]]
def forward(self, inputs):
return [inputs[0][:,:,self.ystart:self.yend,self.xstart:self.xend]]
现在,我们可以重载这个类,只需用一行代码注册该层。
cv.dnn_registerLayer('Crop', CropLayer)
现在,我们准备构建网络图并加载权重,这可以通过OpenCV的dnn.readNe函数。
net = cv.dnn.readNet(args.prototxt, args.caffemodel)
现在,下一步是批量加载图像,并通过网络运行它们。为此,我们使用cv2.dnn.blobFromImage方法。该方法从输入图像中创建四维blob。
blob = cv.dnn.blobFromImage(image, scalefactor, size, mean, swapRB, crop)
其中:
image:是我们想要发送给神经网络进行推理的输入图像。
scalefactor:图像缩放常数,很多时候我们需要把uint8的图像除以255,这样所有的像素都在0到1之间。默认值是1.0,不缩放。
size:输出图像的空间大小。它将等于后续神经网络作为blobFromImage输出所需的输入大小。
swapRB:布尔值,表示我们是否想在3通道图像中交换第一个和最后一个通道。OpenCV默认图像为BGR格式,但如果我们想将此顺序转换为RGB,我们可以将此标志设置为True,这也是默认值。
mean:为了进行归一化,有时我们计算训练数据集上的平均像素值,并在训练过程中从每幅图像中减去它。如果我们在训练中做均值减法,那么我们必须在推理中应用它。这个平均值是一个对应于R, G, B通道的元组。例如Imagenet数据集的均值是R=103.93, G=116.77, B=123.68。如果我们使用swapRB=False,那么这个顺序将是(B, G, R)。
crop:布尔标志,表示我们是否想居中裁剪图像。如果设置为True,则从中心裁剪输入图像时,较小的尺寸等于相应的尺寸,而其他尺寸等于或大于该尺寸。然而,如果我们将其设置为False,它将保留长宽比,只是将其调整为固定尺寸大小。
在我们这个场景下:
inp = cv.dnn.blobFromImage(frame, scalefactor=1.0, size=(args.width, args.height),
mean=(104.00698793, 116.66876762, 122.67891434), swapRB=False,
crop=False)
现在,我们只需要调用一下前向方法。
net.setInput(inp)
out = net.forward()
out = out[0, 0]
out = cv.resize(out, (frame.shape[1], frame.shape[0]))
out = 255 * out
out = out.astype(np.uint8)
out=cv.cvtColor(out,cv.COLOR_GRAY2BGR)
con=np.concatenate((frame,out),axis=1)
cv.imshow(kWinName,con)
结果:
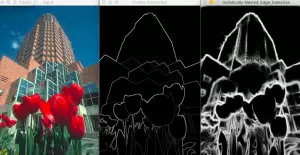

文中的代码:https://github.com/sankit1/cv-tricks.com/tree/master/OpenCV/Edge_detection
本文不是神经网络或机器学习的入门教学,而是通过一个真实的产品案例,展示了在手机客户端上运行一个神经网络的关键技术点
在卷积神经网络适用的领域里,已经出现了一些很经典的图像分类网络,比如 VGG16/VGG19,Inception v1-v4 Net,ResNet 等,这些分类网络通常又都可以作为其他算法中的基础网络结构,尤其是 VGG 网络,被很多其他的算法借鉴,本文也会使用 VGG16 的基础网络结构,但是不会对 VGG 网络做详细的入门教学
虽然本文不是神经网络技术的入门教程,但是仍然会给出一系列的相关入门教程和技术文档的链接,有助于进一步理解本文的内容
具体使用到的神经网络算法,只是本文的一个组成部分,除此之外,本文还介绍了如何裁剪 TensorFlow 静态库以便于在手机端运行,如何准备训练样本图片,以及训练神经网络时的各种技巧等等
需求是什么
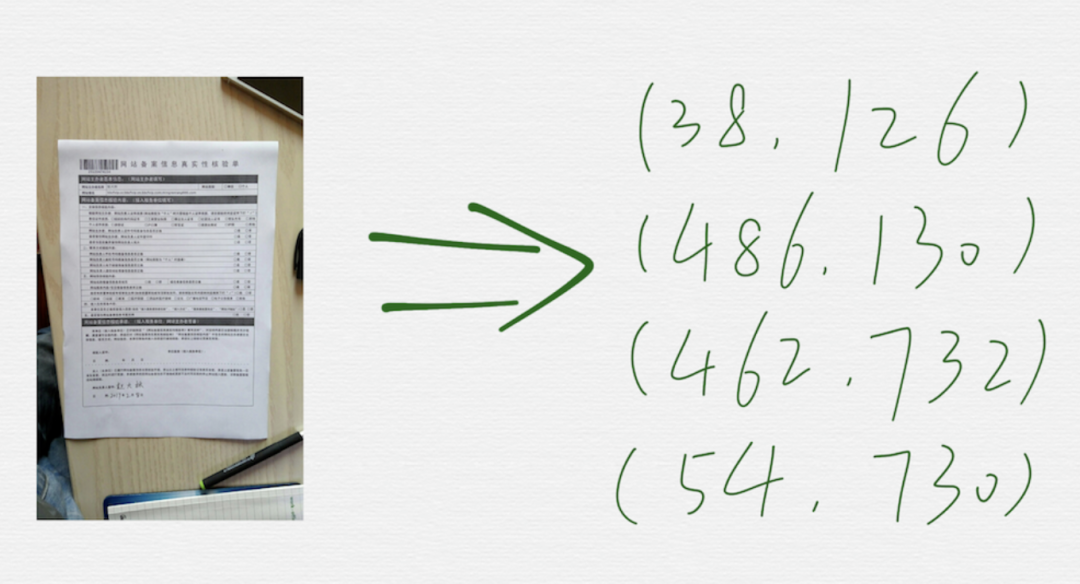
需求很容易描述清楚,如上图,就是在一张图里,把矩形形状的文档的四个顶点的坐标找出来。
传统技术方案的难度和局限性
canny 算法的检测效果,依赖于几个阈值参数,这些阈值参数的选择,通常都是人为设置的经验值,在改进的过程中,引入额外的步骤后,通常又会引入一些新的阈值参数,同样,也是依赖于调试结果设置的经验值。整体来看,这些阈值参数的个数,不能特别的多,因为一旦太多了,就很难依赖经验值进行设置,另外,虽然有这些阈值参数,但是最终的参数只是一组或少数几组固定的组合,所以算法的鲁棒性又会打折扣,很容易遇到边缘检测效果不理想的场景
在边缘图上建立的数学模型很复杂,代码实现难度大,而且也会遇到算法无能为力的场景
下面这张图表,能够很好的说明上面列出的这两个问题:

这张图表的第一列是输入的 image,最后的三列(先不用看这张图表的第二列),是用三组不同阈值参数调用 canny 函数和额外的函数后得到的输出 image,可以看到,边缘检测的效果,并不总是很理想的,有些场景中,矩形的边,出现了很严重的断裂,有些边,甚至被完全擦除掉了,而另一些场景中,又会检测出很多干扰性质的长短边。可想而知,想用一个数学模型,适应这么不规则的边缘图,会是多么困难的一件事情。
思考如何改善
在第一版的技术方案中,负责的同学花费了大量的精力进行各种调优,终于取得了还不错的效果,但是,就像前面描述的那样,还是会遇到检测不出来的场景。在第一版技术方案中,遇到这种情况的时候,采用的做法是针对这些不能检测的场景,人工进行分析和调试,调整已有的一组阈值参数和算法,可能还需要加入一些其他的算法流程(可能还会引入新的一些阈值参数),然后再整合到原有的代码逻辑中。经过若干轮这样的调整后,我们发现,已经进入一个瓶颈,按照这种手段,很难进一步提高检测效果了。
既然传统的算法手段已经到极限了,那不如试试机器学习/神经网络。
1 神经网络的输入和输出

按照这种思路,对于神经网络部分,现在的需求变成了上图所示的样子。
2 HED(Holistically-Nested Edge Detection) 网络
边缘检测这种需求,在图像处理领域里面,通常叫做 Edge Detection 或 Contour Detection,按照这个思路,找到了 Holistically-Nested Edge Detection 网络模型。
HED 网络模型是在 VGG16 网络结构的基础上设计出来的,所以有必要先看看 VGG16。
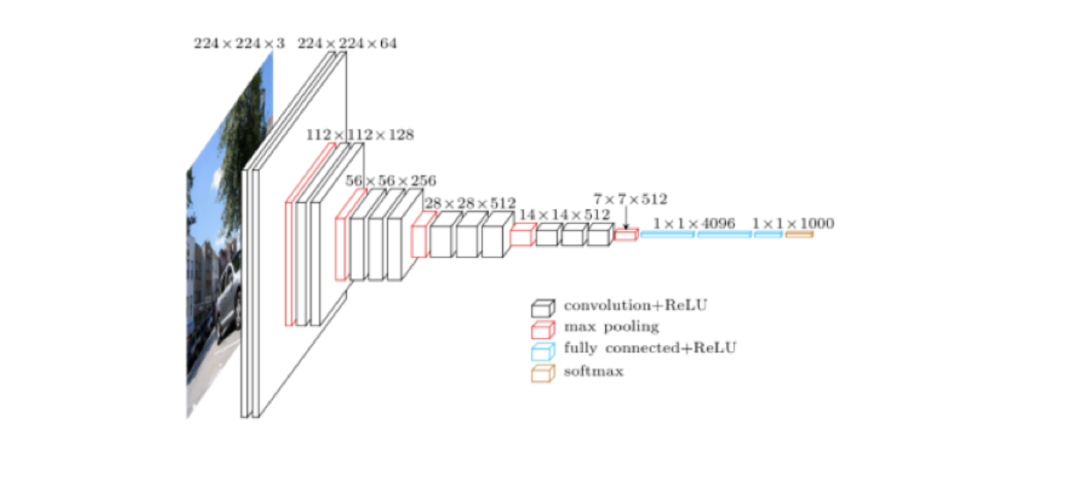
上图是 VGG16 的原理图,为了方便从 VGG16 过渡到 HED,我们先把 VGG16 变成下面这种示意图:
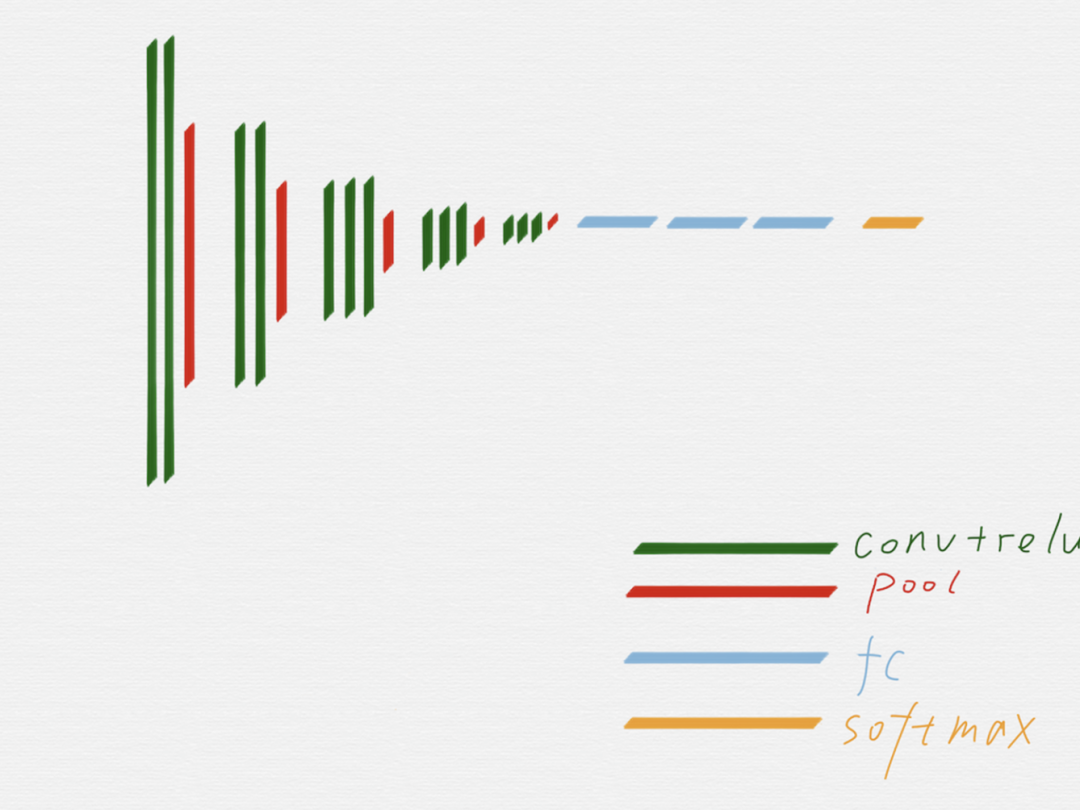
在上面这个示意图里,用不同的颜色区分了 VGG16 的不同组成部分。
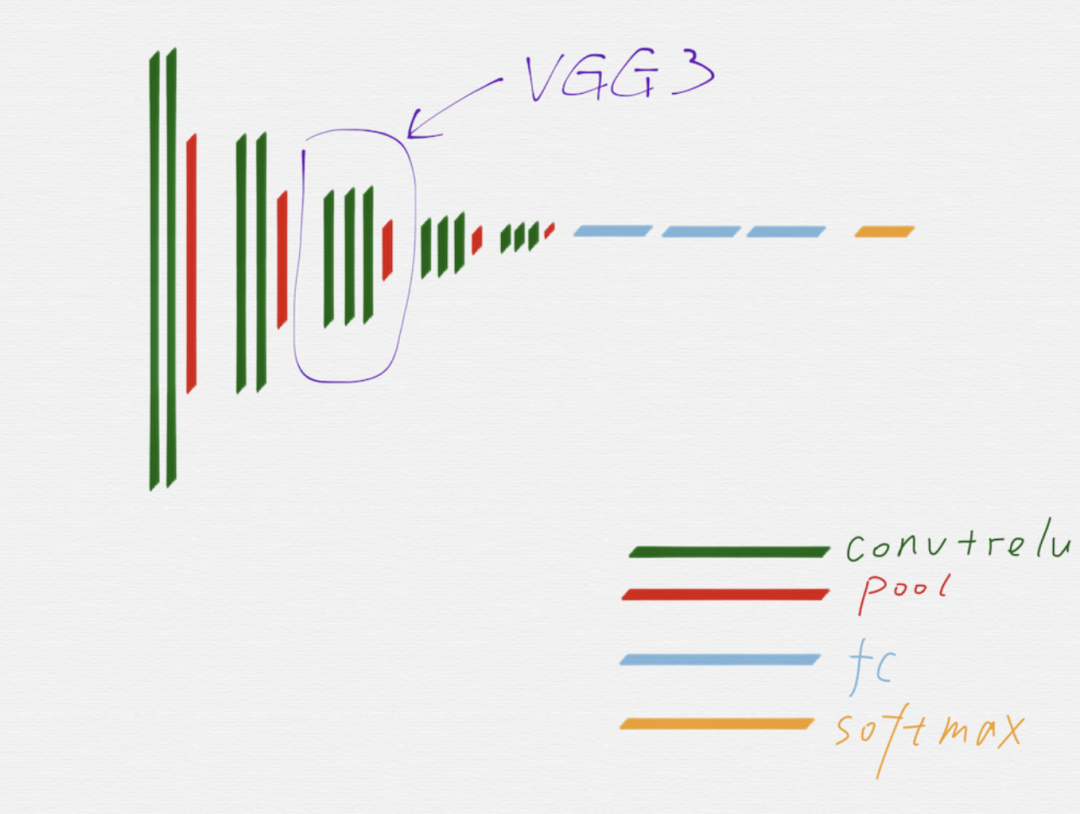
从示意图上可以看到,绿色代表的卷积层和红色代表的池化层,可以很明显的划分出五组,上图用紫色线条框出来的就是其中的第三组。
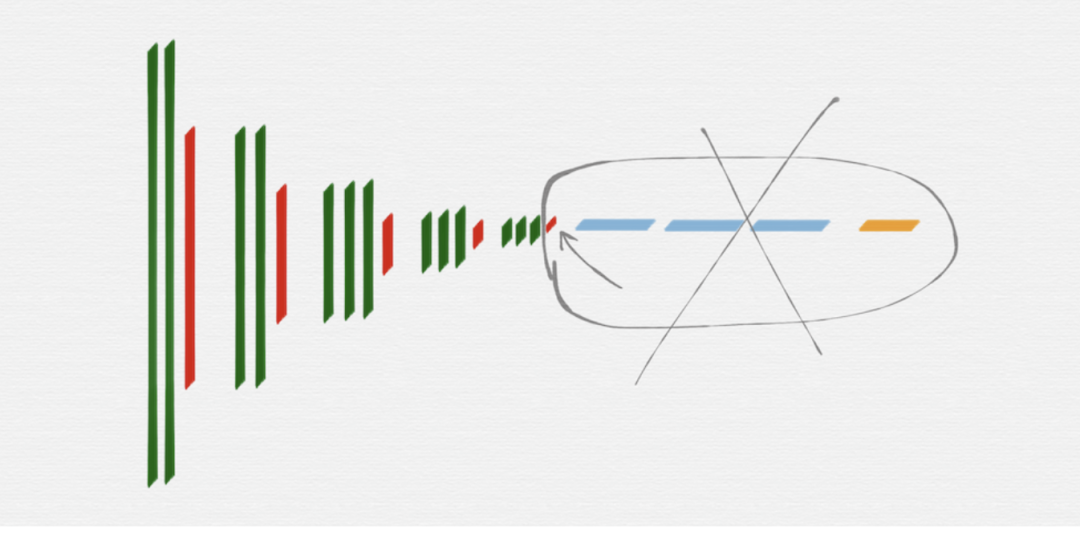
HED 网络要使用的就是 VGG16 网络里面的这五组,后面部分的 fully connected 层和 softmax 层,都是不需要的,另外,第五组的池化层(红色)也是不需要的。

去掉不需要的部分后,就得到上图这样的网络结构,因为有池化层的作用,从第二组开始,每一组的输入 image 的长宽值,都是前一组的输入 image 的长宽值的一半。
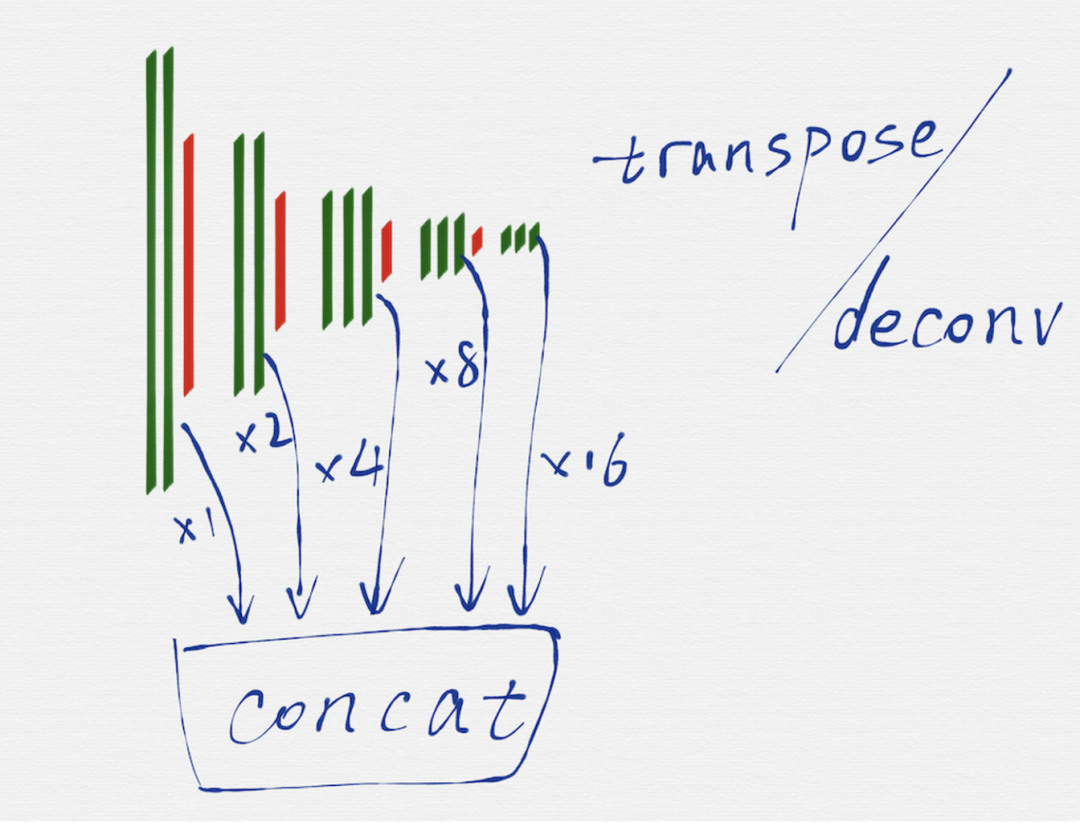
HED 网络是一种多尺度多融合(multi-scale and multi-level feature learning)的网络结构,所谓的多尺度,就是如上图所示,把 VGG16 的每一组的最后一个卷积层(绿色部分)的输出取出来,因为每一组得到的 image 的长宽尺寸是不一样的,所以这里还需要用转置卷积(transposed convolution)/反卷积(deconv)对每一组得到的 image 再做一遍运算,从效果上看,相当于把第二至五组得到的 image 的长宽尺寸分别扩大 2 至 16 倍,这样在每个尺度(VGG16 的每一组就是一个尺度)上得到的 image,都是相同的大小了。

把每一个尺度上得到的相同大小的 image,再融合到一起,这样就得到了最终的输出 image,也就是具有边缘检测效果的 image。
基于 TensorFlow 编写的 HED 网络结构代码如下:



训练网络
1 cost 函数
论文给出的 HED 网络是一个通用的边缘检测网络,按照论文的描述,每一个尺度上得到的 image,都需要参与 cost 的计算,这部分的代码如下:
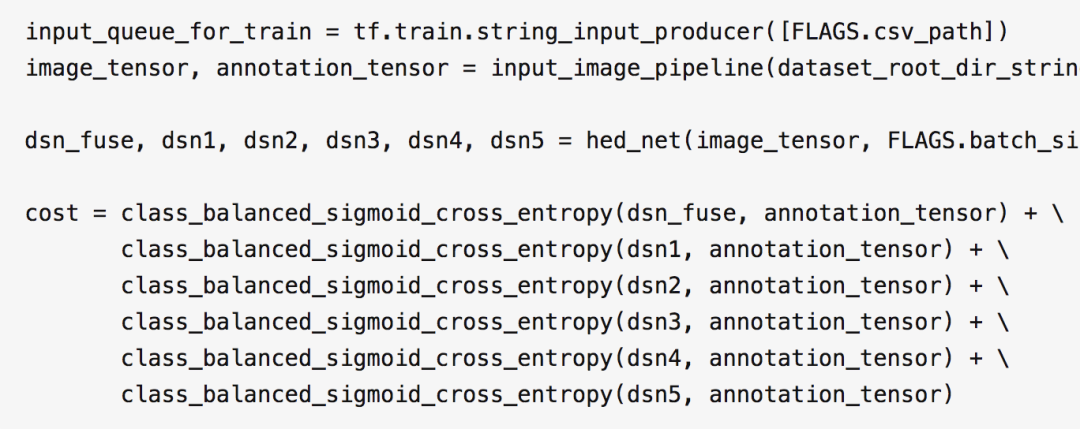
按照这种方式训练出来的网络,检测到的边缘线是有一点粗的,为了得到更细的边缘线,通过多次试验找到了一种优化方案,代码如下:

也就是不再让每个尺度上得到的 image 都参与 cost 的计算,只使用融合后得到的最终 image 来进行计算。
两种 cost 函数的效果对比如下图所示,右侧是优化过后的效果:

另外还有一点,按照 HED 论文里的要求,计算 cost 的时候,不能使用常见的方差 cost,而应该使用 cost-sensitive loss function,代码如下:
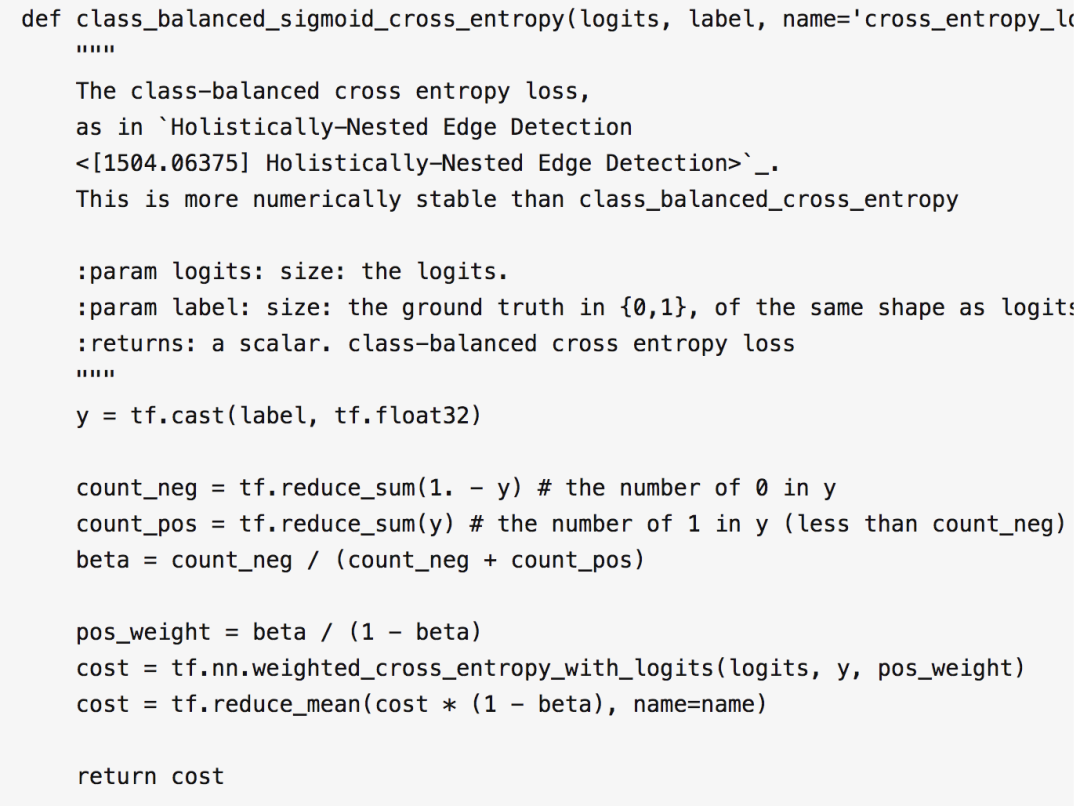
2 转置卷积层的双线性初始化
在尝试 FCN 网络的时候,就被这个问题卡住过很长一段时间,按照 FCN 的要求,在使用转置卷积(transposed convolution)/反卷积(deconv)的时候,要把卷积核的值初始化成双线性放大矩阵(bilinear upsampling kernel),而不是常用的正态分布随机初始化,同时还要使用很小的学习率,这样才更容易让模型收敛。
HED 的论文中,并没有明确的要求也要采用这种方式初始化转置卷积层,但是,在训练过程中发现,采用这种方式进行初始化,模型才更容易收敛。
这部分的代码如下:

3 训练过程冷启动
HED 网络不像 VGG 网络那样很容易就进入收敛状态,也不太容易进入期望的理想状态,主要是两方面的原因:
前面提到的转置卷积层的双线性初始化,就是一个重要因素,因为在 4 个尺度上,都需要反卷积,如果反卷积层不能收敛,那整个 HED 都不会进入期望的理想状态
另外一个原因,是由 HED 的多尺度引起的,既然是多尺度了,那每个尺度上得到的 image 都应该对模型的最终输出 image 产生贡献,在训练的过程中发现,如果输入 image 的尺寸是 224224,还是很容易就训练成功的,但是当把输入 image 的尺寸调整为 256256 后,很容易出现一种状况,就是 5 个尺度上得到的 image,会有 1 ~ 2 个 image 是无效的(全部是黑色)
为了解决这里遇到的问题,采用的办法就是先使用少量样本图片(比如 2000 张)训练网络,在很短的训练时间(比如迭代 1000 次)内,如果 HED 网络不能表现出收敛的趋势,或者不能达到 5 个尺度的 image 全部有效的状态,那就直接放弃这轮的训练结果,重新开启下一轮训练,直到满意为止,然后才使用完整的训练样本集合继续训练网络。
训练数据集(大量合成数据 + 少量真实数据)
HED 论文里使用的训练数据集,是针对通用的边缘检测目的的,什么形状的边缘都有,比如下面这种:

用这份数据训练出来的模型,在做文档扫描的时候,检测出来的边缘效果并不理想,而且这份训练数据集的样本数量也很小,只有一百多张图片(因为这种图片的人工标注成本太高了),这也会影响模型的质量。
现在的需求里,要检测的是具有一定透视和旋转变换效果的矩形区域,所以可以大胆的猜测,如果准备一批针对性更强的训练样本,应该是可以得到更好的边缘检测效果的。
借助第一版技术方案收集回来的真实场景图片,我们开发了一套简单的标注工具,人工标注了 1200 张图片(标注这 1200 张图片的时间成本也很高),但是这 1200 多张图片仍然有很多问题,比如对于神经网络来说,1200 个训练样本其实还是不够的,另外,这些图片覆盖的场景其实也比较少,有些图片的相似度比较高,这样的数据放到神经网络里训练,泛化的效果并不好。
所以,还采用技术手段,合成了80000多张训练样本图片。

如上图所示,一张背景图和一张前景图,可以合成出一对训练样本数据。在合成图片的过程中,用到了下面这些技术和技巧:
在前景图上添加旋转、平移、透视变换
对背景图进行了随机的裁剪
通过试验对比,生成合适宽度的边缘线
OpenCV 不支持透明图层之间的旋转和透视变换操作,只能使用最低精度的插值算法,为了改善这一点,后续改成了使用 iOS 模拟器,通过 CALayer 上的操作来合成图片
在不断改进训练样本的过程中,还根据真实样本图片的统计情况和各种途径的反馈信息,刻意模拟了一些更复杂的样本场景,比如凌乱的背景环境、直线边缘干扰等等
经过不断的调整和优化,最终才训练出一个满意的模型,可以再次通过下面这张图表中的第二列看一下神经网络模型的边缘检测效果:
虽然用神经网络技术,已经得到了一个比 canny 算法更好的边缘检测效果,但是,神经网络也并不是万能的,干扰是仍然存在的,所以,第二个步骤中的数学模型算法,仍然是需要的,只不过因为第一个步骤中的边缘检测有了大幅度改善,所以第二个步骤中的算法,得到了适当的简化,而且算法整体的适应性也更强了。
这部分的算法如下图所示:
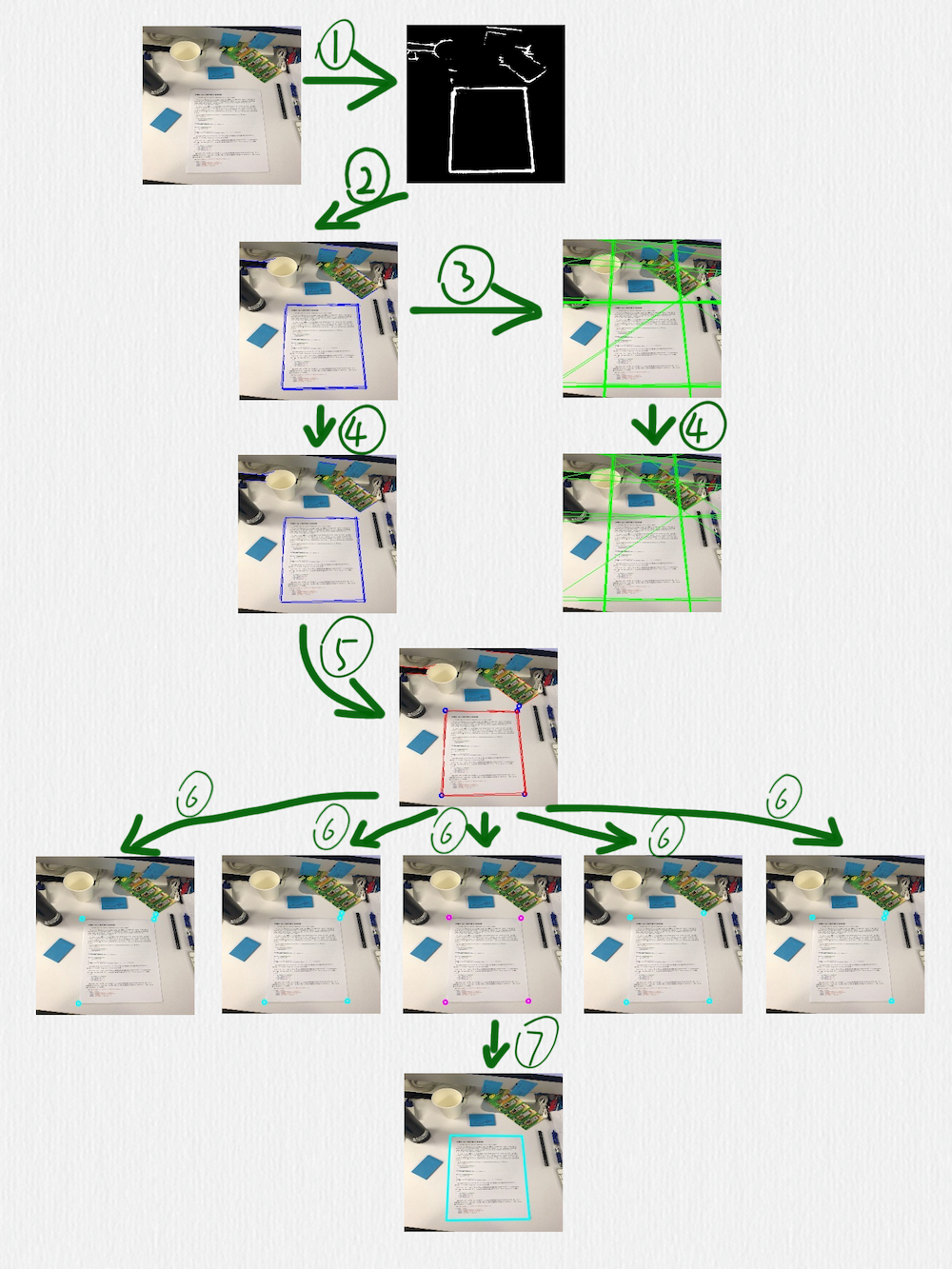
按照编号顺序,几个关键步骤做了下面这些事情:
用 HED 网络检测边缘,可以看到,这里得到的边缘线还是存在一些干扰的
在前一步得到的图像上,使用 HoughLinesP 函数检测线段(蓝色线段)
把前一步得到的线段延长成直线(绿色直线)
在第二步中检测到的线段,有一些是很接近的,或者有些短线段是可以连接成一条更长的线段的,所以可以采用一些策略把它们合并到一起,这个时候,就要借助第三步中得到的直线。定义一种策略判断两条直线是否相等,当遇到相等的两条直线时,把这两条直线各自对应的线段再合并或连接成一条线段。这一步完成后,后面的步骤就只需要蓝色的线段而不需要绿色的直线了
根据第四步得到的线段,计算它们之间的交叉点,临近的交叉点也可以合并,同时,把每一个交叉点和产生这个交叉点的线段也要关联在一起(每一个蓝色的点,都有一组红色的线段和它关联)
对于第五步得到的所有交叉点,每次取出其中的 4 个,判断这 4 个点组成的四边形是否是一个合理的矩形(有透视变换效果的矩形),除了常规的判断策略,比如角度、边长的比值之外,还有一个判断条件就是每条边是否可以和第五步中得到的对应的点的关联线段重合,如果不能重合,则这个四边形就不太可能是我们期望检测出来的矩形
经过第六步的过滤后,如果得到了多个四边形,可以再使用一个简单的过滤策略,比如排序找出周长或面积最大的矩形
对于上面这个例子,第一版技术方案中检测出来的边缘线如下图所示:

有兴趣的读者也可以考虑一下,在这种边缘图中,如何设计算法才能找出我们期望的那个矩形。
原文 https://blog.csdn.net/Tencent_Bugly/article/details/72828569
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx