
UDP ,你要耗子喂汁呀!

欢迎阅读「程序员cxuan」 的文章,从今往后,你就是我的读者了。你可以加个星标,及时阅读最新文章哦!
这一篇文章是计算机网络连载文章的第四篇,历史文章请阅读
那么下面就开始我们本篇文章。
运输层位于应用层和网络层之间,是 OSI 分层体系中的第四层,同时也是网络体系结构的重要部分。运输层主要负责网络上的端到端通信。

运输层为运行在不同主机上的应用程序之间的通信起着至关重要的作用。下面我们就来一起探讨一下关于运输层的协议部分
运输层概述
计算机网络的运输层非常类似于高速公路,高速公路负责把人或者物品从一端运送到另一端,而计算机网络的运输层则负责把报文从一端运输到另一端,这个端指的就是 端系统。在计算机网络中,任意一个可以交换信息的介质都可以称为端系统,比如手机、网络媒体、电脑、运营商等。
在运输层运输报文的过程中,会遵守一定的协议规范,比如一次传输的数据限制、选择什么样的运输协议等。运输层实现了让两个互不相关的主机进行逻辑通信的功能,看起来像是让两个主机相连一样。
运输层协议是在端系统中实现的,而不是在路由器中实现的。路由只是做识别地址并转发的功能。这就比如快递员送快递一样,当然是要由地址的接受人也就是 xxx 号楼 xxx 单元 xxx 室的这个人来判断了!
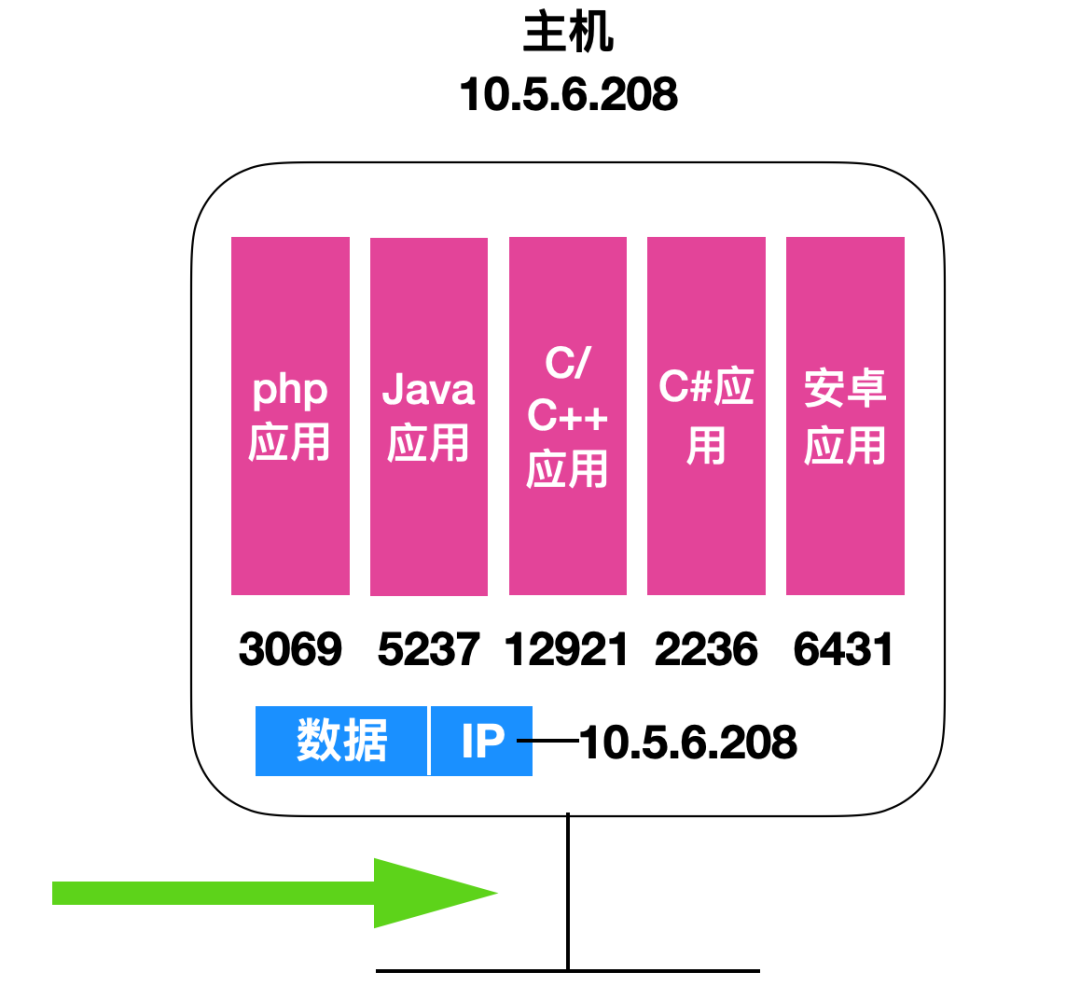
TCP 如何判断是哪个端口的呢?
还记得数据包的结构吗,这里来回顾一下
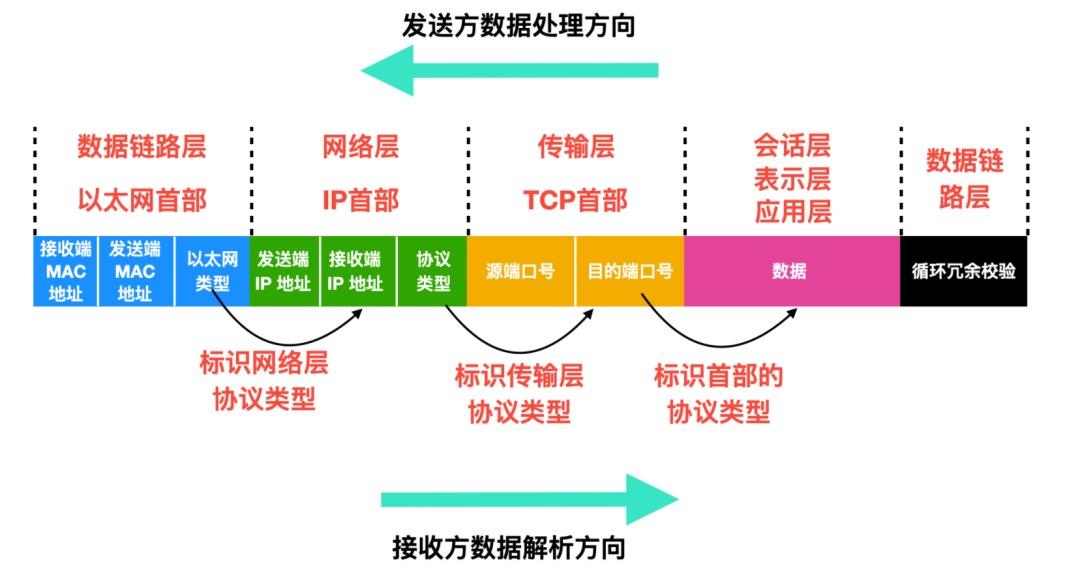
数据包经过每层后,该层协议都会在数据包附上包首部,一个完整的包首部图如上所示。
在数据传输到运输层后,会为其附上 TCP 首部,首部包含着源端口号和目的端口号。
在发送端,运输层将从发送应用程序进程接收到的报文转化成运输层分组,分组在计算机网络中也称为 报文段(segment)。运输层一般会将报文段进行分割,分割成为较小的块,为每一块加上运输层首部并将其向目的地发送。
在发送过程中,可选的运输层协议(也就是交通工具) 主要有 TCP 和 UDP ,关于这两种运输协议的选择及其特性也是我们着重探讨的重点。
TCP 和 UDP 前置知识
在 TCP/IP 协议中能够实现传输层功能的,最具代表性的就是 TCP 和 UDP。提起 TCP 和 UDP ,就得先从这两个协议的定义说起。
TCP 叫做传输控制协议(TCP,Transmission Control Protocol),通过名称可以大致知道 TCP 协议有控制传输的功能,主要体现在其可控,可控就表示着可靠,确实是这样的,TCP 为应用层提供了一种可靠的、面向连接的服务,它能够将分组可靠的传输到服务端。
UDP 叫做 用户数据报协议(UDP,User Datagram Protocol),通过名称可以知道 UDP 把重点放在了数据报上,它为应用层提供了一种无需建立连接就可以直接发送数据报的方法。
怎么计算机网络中的术语对一个数据的描述这么多啊?
在计算机网络中,在不同层之间会有不同的描述。我们上面提到会将运输层的分组称为报文段,除此之外,还会将 TCP 中的分组也称为报文段,然而将 UDP 的分组称为数据报,同时也将网络层的分组称为数据报
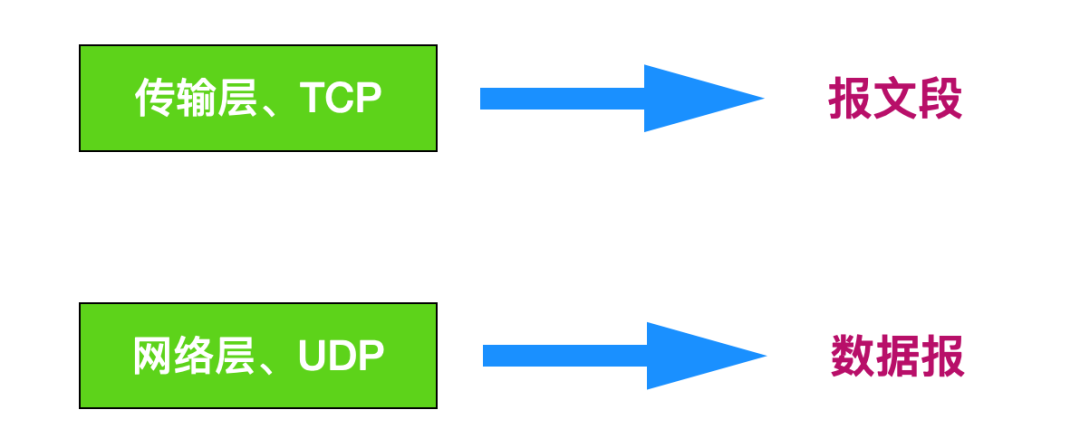
但是为了统一,一般在计算机网络中我们统一称 TCP 和 UDP 的报文为 报文段,这个就相当于是约定,到底如何称呼不用过多纠结啦。
套接字
在 TCP 或者 UDP 发送具体的报文信息前,需要先经过一扇 门,这个门就是套接字(socket),套接字向上连接着应用层,向下连接着网络层。在操作系统中,操作系统分别为应用和硬件提供了接口(Application Programming Interface)。而在计算机网络中,套接字同样是一种接口,它也是有接口 API 的。
使用 TCP 或 UDP 通信时,会广泛用到套接字的 API,使用这套 API 设置 IP 地址、端口号,实现数据的发送和接收。
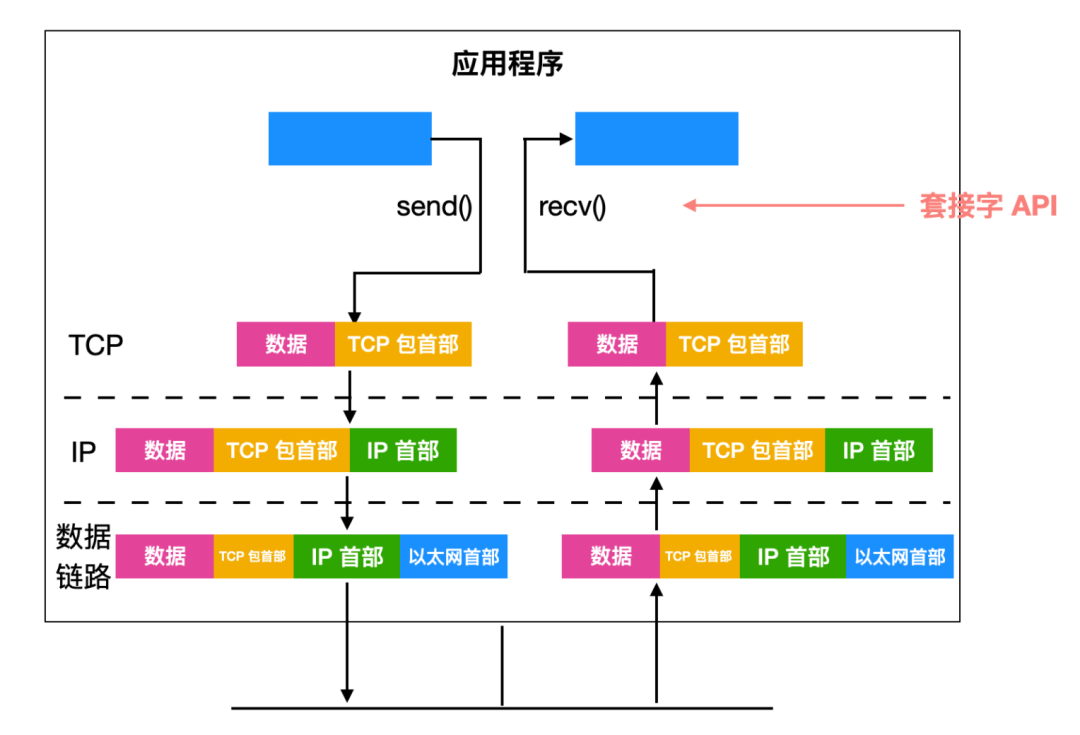
现在我们知道了, Socket 和 TCP/IP 没有必然联系,Socket 的出现只是方便了 TCP/IP 的使用,如何方便使用呢?你可以直接使用下面 Socket API 的这些方法。
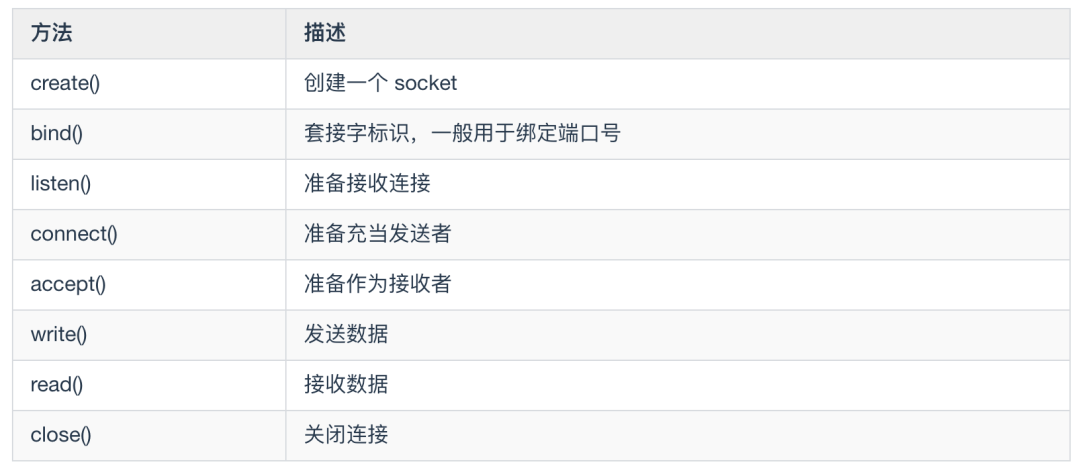
套接字类型
套接字的主要类型有三种,下面我们分别介绍一下
数据报套接字(Datagram sockets):数据报套接字提供一种无连接的服务,而且并不能保证数据传输的可靠性。数据有可能在传输过程中丢失或出现数据重复,且无法保证顺序地接收到数据。数据报套接字使用UDP( User DatagramProtocol)协议进行数据的传输。由于数据报套接字不能保证数据传输的可靠性,对于有可能出现的数据丢失情况,需要在程序中做相应的处理。流套接字(Stream sockets):流套接字用于提供面向连接、可靠的数据传输服务。能够保证数据的可靠性、顺序性。流套接字之所以能够实现可靠的数据服务,原因在于其使用了传输控制协议,即TCP(The Transmission Control Protocol)协议原始套接字(Raw sockets): 原始套接字允许直接发送和接收 IP 数据包,而无需任何特定于协议的传输层格式,原始套接字可以读写内核没有处理过的 IP 数据包。
套接字处理过程
在计算机网络中,要想实现通信,必须至少需要两个端系统,至少需要一对两个套接字才行。下面是套接字的通信过程。
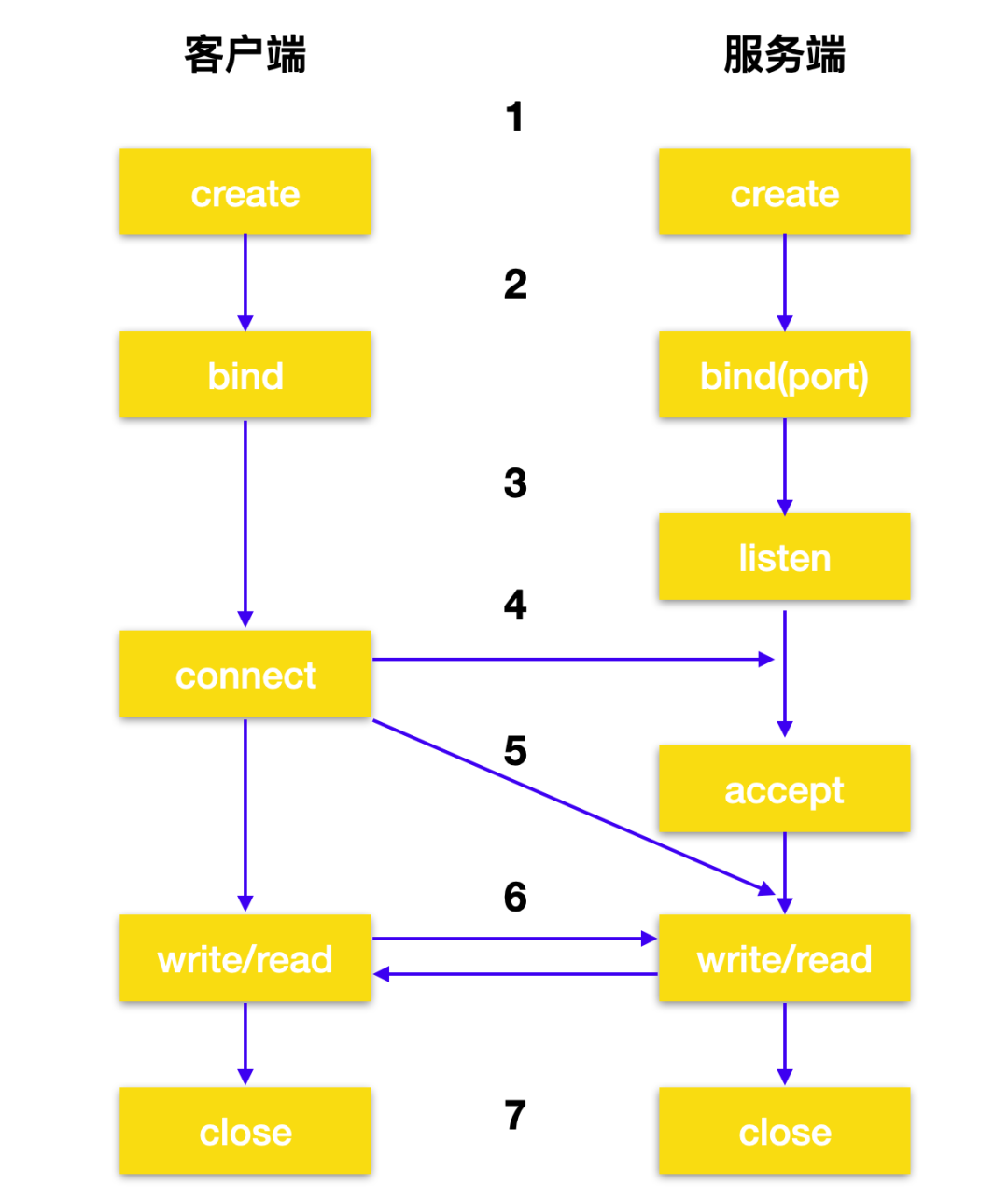
socket 中的 API 用于创建通信链路中的端点,创建完成后,会返回描述该套接字的
套接字描述符。
就像使用文件描述符来访问文件一样,套接字描述符用来访问套接字。
当应用程序具有套接字描述符后,它可以将唯一的名称绑定在套接字上,服务器必须绑定一个名称才能在网络中访问
在为服务端分配了 socket 并且将名称使用 bind 绑定到套接字上后,将会调用 listen api。
listen表示客户端愿意等待连接的意愿,listen 必须在 accept api 之前调用。客户端应用程序在流套接字(基于 TCP)上调用
connect发起与服务器的连接请求。服务器应用程序使用
acceptAPI 接受客户端连接请求,服务器必须先成功调用 bind 和 listen 后,再调用 accept api。在流套接字之间建立连接后,客户端和服务器就可以发起 read/write api 调用了。
当服务器或客户端要停止操作时,就会调用
closeAPI 释放套接字获取的所有系统资源。
虽然套接字 API 位于应用程序层和传输层之间的通信模型中,但是套接字 API 不属于通信模型。套接字 API 允许应用程序与传输层和网络层进行交互。
在往下继续聊之前,我们先播放一个小插曲,简单聊一聊 IP。
聊聊 IP
IP 是Internet Protocol(网际互连协议)的缩写,是 TCP/IP 体系中的网络层协议。设计 IP 的初衷主要想解决两类问题
提高网络扩展性:实现大规模网络互联
对应用层和链路层进行解藕,让二者独立发展。
IP 是整个 TCP/IP 协议族的核心,也是构成互联网的基础。为了实现大规模网络的互通互联,IP 更加注重适应性、简洁性和可操作性,并在可靠性做了一定的牺牲。IP 不保证分组的交付时限和可靠性,所传送分组有可能出现丢失、重复、延迟或乱序等问题。
我们知道,TCP 协议的下一层就是 IP 协议层,既然 IP 不可靠,那么如何保证数据能够准确无误地到达呢?
这就涉及到 TCP 传输机制的问题了,我们后面聊到 TCP 的时候再说。
端口号
在聊端口号前,先来聊一聊文件描述以及 socket 和端口号的关系
为了方便资源的使用,提高机器的性能、利用率和稳定性等等原因,我们的计算机都有一层软件叫做操作系统,它用于帮我们管理计算机可以使用的资源,当我们的程序要使用一个资源的时候,可以向操作系统申请,再由操作系统为我们的程序分配和管理资源。通常当我们要访问一个内核设备或文件时,程序可以调用系统函数,系统就会为我们打开设备或文件,然后返回一个文件描述符fd(或称为ID,是一个整数),我们要访问该设备或文件,只能通过该文件描述符。可以认为该编号对应着打开的文件或设备。
而当我们的程序要使用网络时,要使用到对应的操作系统内核的操作和网卡设备,所以我们可以向操作系统申请,然后系统会为我们创建一个套接字 Socket,并返回这个 Socket 的ID,以后我们的程序要使用网络资源,只要向这个 Socket 的编号 ID 操作即可。而我们的每一个网络通信的进程至少对应着一个 Socket。向 Socket 的 ID 中写数据,相当于向网络发送数据,向 Socket 中读数据,相当于接收数据。而且这些套接字都有唯一标识符——文件描述符 fd。
端口号是 16 位的非负整数,它的范围是 0 - 65535 之间,这个范围会分为三种不同的端口号段,由 Internet 号码分配机构 IANA 进行分配
周知/标准端口号,它的范围是 0 - 1023
注册端口号,范围是 1024 - 49151
私有端口号,范围是 49152 - 6553
一台计算机上可以运行多个应用程序,当一个报文段到达主机后,应该传输给哪个应用程序呢?你怎么知道这个报文段就是传递给 HTTP 服务器而不是 SSH 服务器的呢?
是凭借端口号吗?当报文到达服务器时,是端口号来区分不同应用程序的,所以应该借助端口号来区分。
举个例子反驳一下 cxuan,假如到达服务器的两条数据都是由 80 端口发出的你该如何区分呢?或者说到达服务器的两条数据端口一样,协议不同,该如何区分呢?
所以仅凭端口号来确定某一条报文显然是不够的。
互联网上一般使用 源 IP 地址、目标 IP 地址、源端口号、目标端口号 来进行区分。如果其中的某一项不同,就被认为是不同的报文段。这些也是多路分解和多路复用 的基础。
确定端口号
在实际通信之前,需要先确定一下端口号,确定端口号的方法分为两种:
标准既定的端口号
标准既定的端口号是静态分配的,每个程序都会有自己的端口号,每个端口号都有不同的用途。端口号是一个 16 比特的数,其大小在 0 - 65535 之间,0 - 1023 范围内的端口号都是动态分配的既定端口号,例如 HTTP 使用 80 端口来标识,FTP 使用 21 端口来标识,SSH 使用 22 来标识。这类端口号有一个特殊的名字,叫做 周知端口号(Well-Known Port Number)。
时序分配的端口号
第二种分配端口号的方式是一种动态分配法,在这种方法下,客户端应用程序可以完全不用自己设置端口号,凭借操作系统进行分配,操作系统可以为每个应用程序分配互不冲突的端口号。这种动态分配端口号的机制即使是同一个客户端发起的 TCP 连接,也能识别不同的连接。
多路复用和多路分解
我们上面聊到了在主机上的每个套接字都会分配一个端口号,当报文段到达主机时,运输层会检查报文段中的目的端口号,并将其定向到相应的套接字,然后报文段中的数据通过套接字进入其所连接的进程。下面我们来聊一下什么是多路复用和多路分解的概念。
多路复用和多路分解分为两种,即无连接的多路复用(多路分解)和面向连接的多路复用(多路分解)
无连接的多路复用和多路分解
开发人员会编写代码确定端口号是周知端口号还是时序分配的端口号。假如主机 A 中的一个 10637 端口要向主机 B 中的 45438 端口发送数据,运输层采用的是 UDP 协议,数据在应用层产生后,会在运输层中加工处理,然后在网络层将数据封装得到 IP 数据报,IP 数据包通过链路层尽力而为的交付给主机 B,然后主机 B 会检查报文段中的端口号判断是哪个套接字的,这一系列的过程如下所示
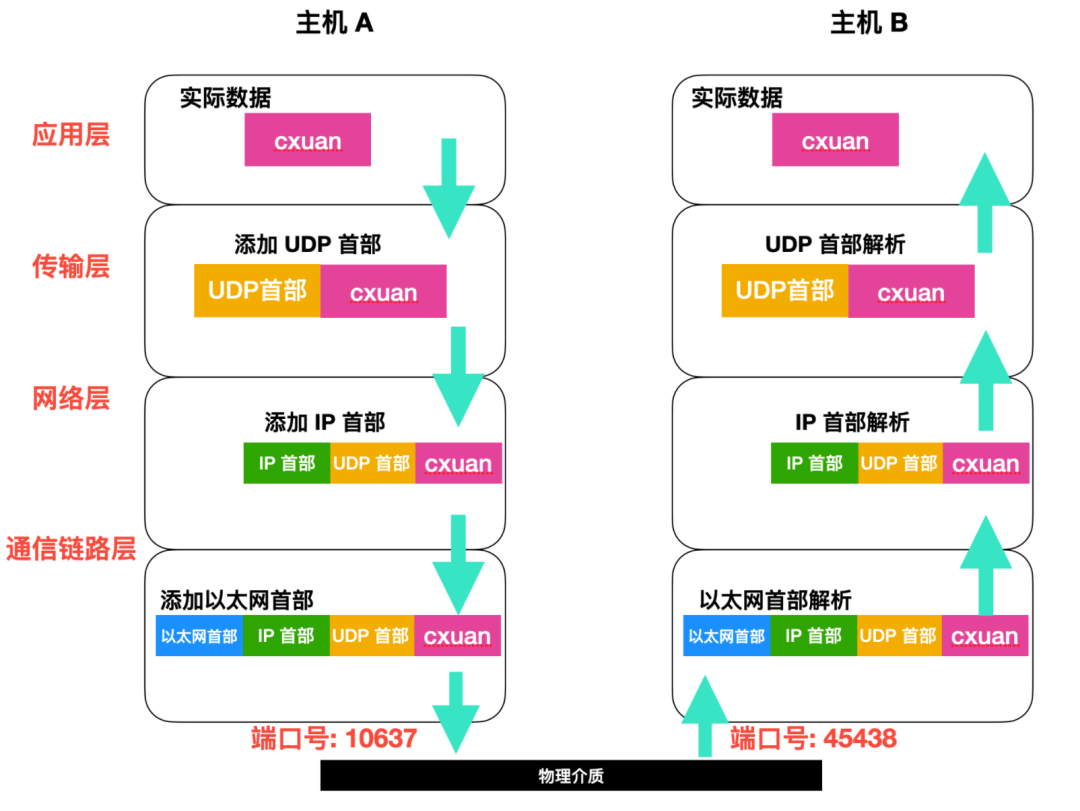
UDP 套接字就是一个二元组,二元组包含目的 IP 地址和目的端口号。
所以,如果两个 UDP 报文段有不同的源 IP 地址和/或相同的源端口号,但是具有相同的目的 IP 地址和目的端口号,那么这两个报文会通过套接字定位到相同的目的进程。
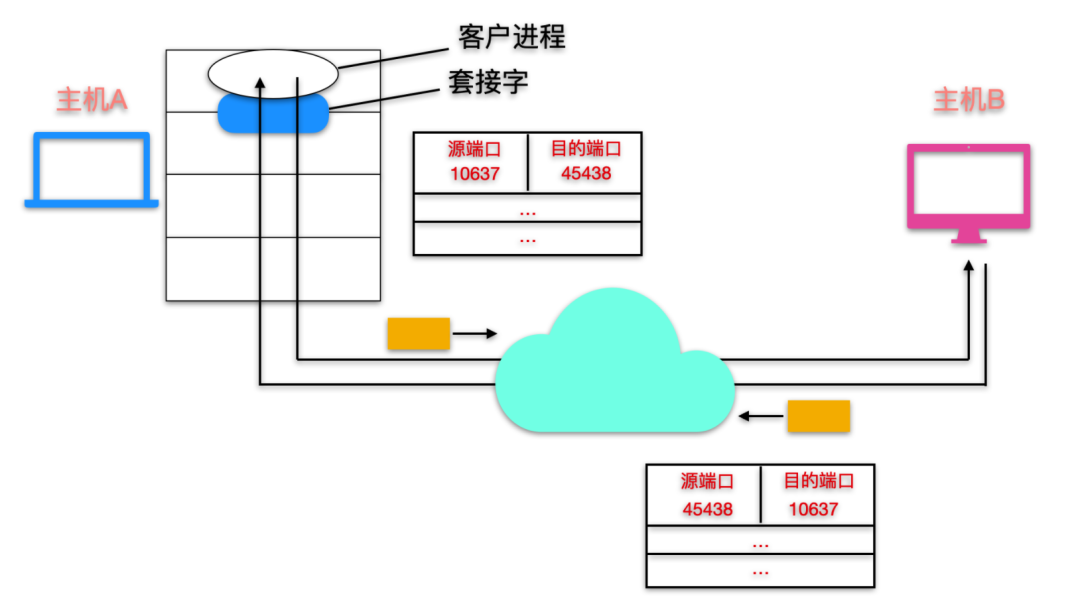
这里思考一个问题,主机 A 给主机 B 发送一个消息,为什么还需要知道源端口号呢?比如我给妹子表达出我对你有点意思的信息,妹子还需要知道这个信息是从我的哪个器官发出的吗?知道是我这个人对你有点意思不就完了?实际上是需要的,因为妹子如果要表达出她对你也有点意思,她是不是可能会亲你一口,那她得知道往哪亲吧?
这就是,在 A 到 B 的报文段中,源端口号会作为 返回地址 的一部分,即当 B 需要回发一个报文段给 A 时,B 需要从 A 到 B 中的源端口号取值,如下图所示
面向连接的多路复用与多路分解
如果说无连接的多路复用和多路分解指的是 UDP 的话,那么面向连接的多路复用与多路分解指的是 TCP 了,TCP 和 UDP 在报文结构上的差别是,UDP 是一个二元组而 TCP 是一个四元组,即源 IP 地址、目标 IP 地址、源端口号、目标端口号 ,这个我们上面也提到了。当一个 TCP 报文段从网络到达一台主机时,这个主机会根据这四个值拆解到对应的套接字上。

上图显示了面向连接的多路复用和多路分解的过程,图中主机 C 向主机 B 发起了两个 HTTP 请求,主机 A 向主机 C 发起了一个 HTTP 请求,主机 A、B、C 都有自己唯一的 IP 地址,当主机 C 发出 HTTP 请求后,主机 B 能够分解这两个 HTTP 连接,因为主机 C 发出请求的两个源端口号不同,所以对于主机 B 来说,这是两条请求,主机 B 能够进行分解。对于主机 A 和主机 C 来说,这两个主机有不同的 IP 地址,所以对于主机 B 来说,也能够进行分解。
UDP
终于,我们开始了对 UDP 协议的探讨,淦起!
UDP 的全称是 用户数据报协议(UDP,User Datagram Protocol),UDP 为应用程序提供了一种无需建立连接就可以发送封装的 IP 数据包的方法。如果应用程序开发人员选择的是 UDP 而不是 TCP 的话,那么该应用程序相当于就是和 IP 直接打交道的。
从应用程序传递过来的数据,会附加上多路复用/多路分解的源和目的端口号字段,以及其他字段,然后将形成的报文传递给网络层,网络层将运输层报文段封装到 IP 数据报中,然后尽力而为的交付给目标主机。最关键的一点就是,使用 UDP 协议在将数据报传递给目标主机时,发送方和接收方的运输层实体间是没有握手的。正因为如此,UDP 被称为是无连接的协议。
UDP 特点
UDP 协议一般作为流媒体应用、语音交流、视频会议所使用的传输层协议,我们大家都知道的 DNS 协议底层也使用了 UDP 协议,这些应用或协议之所以选择 UDP 主要是因为以下这几点
速度快,采用 UDP 协议时,只要应用进程将数据传给 UDP,UDP 就会将此数据打包进 UDP 报文段并立刻传递给网络层,然后 TCP 有拥塞控制的功能,它会在发送前判断互联网的拥堵情况,如果互联网极度阻塞,那么就会抑制 TCP 的发送方。使用 UDP 的目的就是希望实时性。无须建立连接,TCP 在数据传输之前需要经过三次握手的操作,而 UDP 则无须任何准备即可进行数据传输。因此 UDP 没有建立连接的时延。如果使用 TCP 和 UDP 来比喻开发人员:TCP 就是那种凡事都要设计好,没设计不会进行开发的工程师,需要把一切因素考虑在内后再开干!所以非常靠谱;而 UDP 就是那种上来直接干干干,接到项目需求马上就开干,也不管设计,也不管技术选型,就是干,这种开发人员非常不靠谱,但是适合快速迭代开发,因为可以马上上手!无连接状态,TCP 需要在端系统中维护连接状态,连接状态包括接收和发送缓存、拥塞控制参数以及序号和确认号的参数,在 UDP 中没有这些参数,也没有发送缓存和接受缓存。因此,某些专门用于某种特定应用的服务器当应用程序运行在 UDP 上,一般能支持更多的活跃用户分组首部开销小,每个 TCP 报文段都有 20 字节的首部开销,而 UDP 仅仅只有 8 字节的开销。
这里需要注意一点,并不是所有使用 UDP 协议的应用层都是
不可靠的,应用程序可以自己实现可靠的数据传输,通过增加确认和重传机制。所以使用 UDP 协议最大的特点就是速度快。
UDP 报文结构
下面来一起看一下 UDP 的报文结构,每个 UDP 报文分为 UDP 报头和 UDP 数据区两部分。报头由 4 个 16 位长(2 字节)字段组成,分别说明该报文的源端口、目的端口、报文长度和校验值。
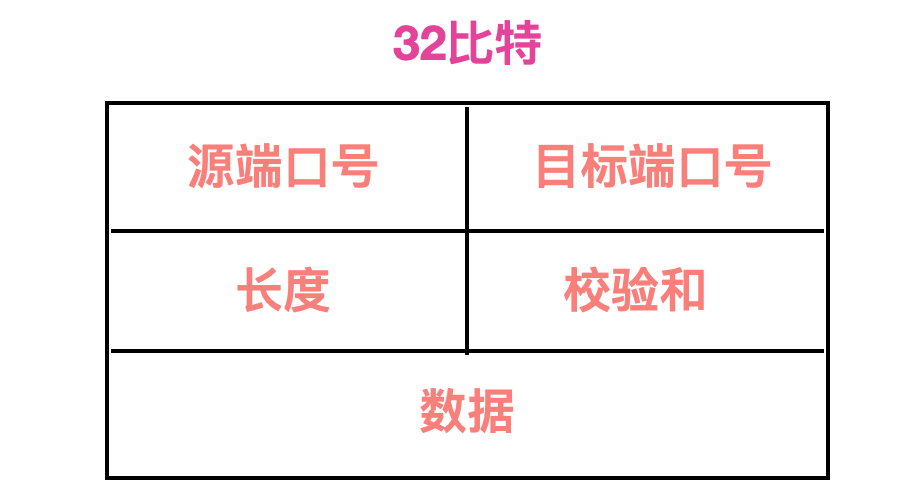
源端口号(Source Port):这个字段占据 UDP 报文头的前 16 位,通常包含发送数据报的应用程序所使用的 UDP 端口。接收端的应用程序利用这个字段的值作为发送响应的目的地址。这个字段是可选项,有时不会设置源端口号。没有源端口号就默认为 0 ,通常用于不需要返回消息的通信中。目标端口号(Destination Port): 表示接收端端口,字段长为 16 位长度(Length): 该字段占据 16 位,表示 UDP 数据报长度,包含 UDP 报文头和 UDP 数据长度。因为 UDP 报文头长度是 8 个字节,所以这个值最小为 8,最大长度为 65535 字节。校验和(Checksum):UDP 使用校验和来保证数据安全性,UDP 的校验和也提供了差错检测功能,差错检测用于校验报文段从源到目标主机的过程中,数据的完整性是否发生了改变。发送方的 UDP 对报文段中的 16 比特字的和进行反码运算,求和时遇到的位溢出都会被忽略,比如下面这个例子,三个 16 比特的数字进行相加

这些 16 比特的前两个和是

然后再将上面的结果和第三个 16 比特的数进行相加

最后一次相加的位会进行溢出,溢出位 1 要被舍弃,然后进行反码运算,反码运算就是将所有的 1 变为 0 ,0 变为 1。因此 1000 0100 1001 0101 的反码就是 0111 1011 0110 1010,这就是校验和,如果在接收方,数据没有出现差错,那么全部的 4 个 16 比特的数值进行运算,同时也包括校验和,如果最后结果的值不是 1111 1111 1111 1111 的话,那么就表示传输过程中的数据出现了差错。
下面来想一个问题,为什么 UDP 会提供差错检测的功能?
这其实是一种 端到端 的设计原则,这个原则说的是要让传输中各种错误发生的概率降低到一个可以接受的水平。
文件从主机A传到主机B,也就是说AB主机要通信,需要经过三个环节:首先是主机A从磁盘上读取文件并将数据分组成一个个数据包packet,,然后数据包通过连接主机A和主机B的网络传输到主机B,最后是主机B收到数据包并将数据包写入磁盘。在这个看似简单其实很复杂的过程中可能会由于某些原因而影响正常通信。比如:磁盘上文件读写错误、缓冲溢出、内存出错、网络拥挤等等这些因素都有可能导致数据包的出错或者丢失,由此可见用于通信的网络是不可靠的。
由于实现通信只要经过上述三个环节,那么我们就想是否在其中某个环节上增加一个检错纠错机制来用于对信息进行把关呢?
网络层肯定不能做这件事,因为网络层的最主要目的是增大数据传输的速率,网络层不需要考虑数据的完整性,数据的完整性和正确性交给端系统去检测就行了,因此在数据传输中,对于网络层只能要求其提供尽可能好的数据传输服务,而不可能寄希望于网络层提供数据完整性的服务。
UDP 不可靠的原因是它虽然提供差错检测的功能,但是对于差错没有恢复能力更不会有重传机制。