
Python处理超强反爬(TSec防火墙+CSS图片背景偏移定位)
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是小小明,今天看到一个网站:

太神奇了,对于每个数字都用css背景图片裁切得到一张小图进行显示。可以确定的是每个数字的图片大小是8*17。
今天我们就一起玩玩。
开始测试
先尝试用request读取数据,结果获得一大堆极度混淆的JS的代码。然后尝试用selenium访问,结果:

感觉这个防火墙有点叼。
算了,使用大杀器来隐藏模拟浏览器的特征:
from selenium.webdriver import ChromeOptions
from selenium import webdriver
browser = webdriver.Chrome()
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
option.add_argument(
'user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
option.add_argument("--disable-blink-features=AutomationControlled")
browser = webdriver.Chrome(options=option)
with open('stealth.min.js') as f:
js = f.read()
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': js
})
url = 'http://hotels.huazhu.com/inthotel/detail/9005308'
browser.get(url)
这回页面总算是出来了:
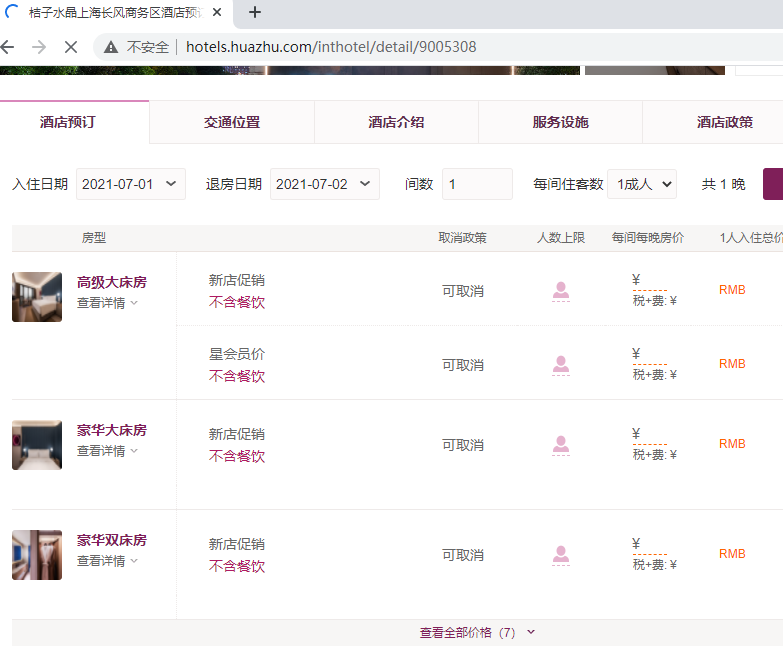
然而价格有时并不显示,只能多刷新几下页面:
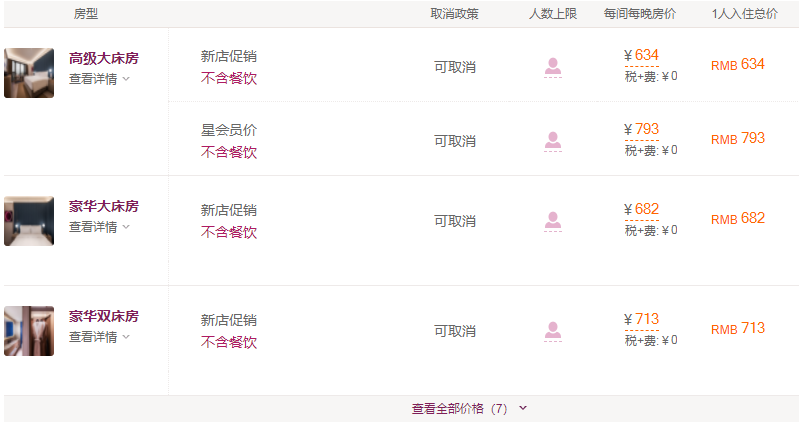
多次访问之后,数据总算能看到了。
下面让模拟器模拟点击查看全部价格:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(browser, 10)
table = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#Pdetail_part2 table')))
table.location_once_scrolled_into_view
{'x': 0, 'y': 0}
more_click = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#Pdetail_part2 a[class="viewallprice"]')))
more_click.click()
这样7条价格数据,我们就全部能够看到了。
下面我们开始抓取我们需要的数据:
截图获取需要的数据
from io import BytesIO
import base64
from PIL import Image
for tr in table.find_elements_by_css_selector("table tr[class^='room first']"):
print(tr.find_element_by_tag_name("h3").text)
price = tr.find_element_by_css_selector(
"div>a[class^='totalprice']")
img_data = base64.b64decode(price.screenshot_as_base64)
img = Image.open(BytesIO(img_data))
display(img)
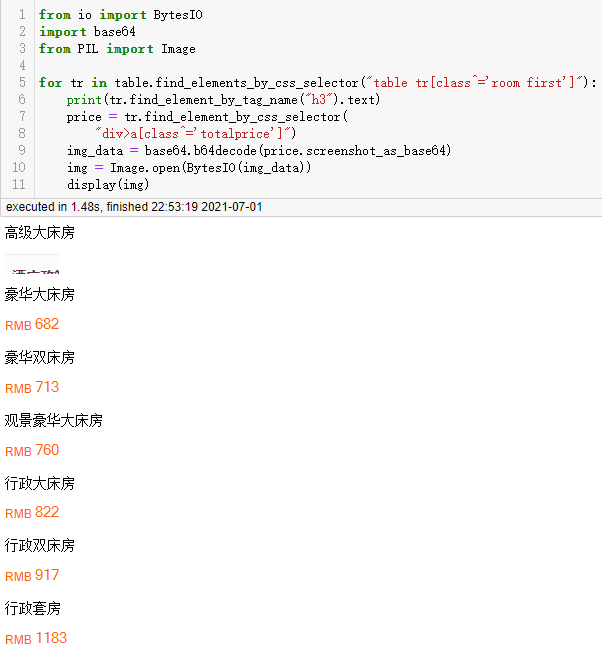
调整鼠标滑动的位置后再来一次:

说明截图有时截的并不准确,想要精准截图也非常困难,因为无法通过程序准确滚动到应该的位置。
光截图就能搞定,那就太简单了。
本文的主要目前还是为了演示解析CSS,咱们继续采用解析法来获取数据:
解析CSS获取图片数据
首先我们解析出我们需要的数据:
img_url = None
for tr in table.find_elements_by_css_selector("table tr[class^='room first']"):
name = tr.find_element_by_tag_name("h3").text
print(name)
price = tr.find_element_by_css_selector("div>a[class^='totalprice']")
for var in price.find_elements_by_tag_name("var"):
if img_url is None:
img_url = var.value_of_css_property("background-image")[5:-2]
print(img_url)
position = var.value_of_css_property("background-position")
w, h = map(lambda x: int(x[1:-2]), position.split())
print(w, h)
高级大床房
http://hotels.huazhu.com/Blur/Pic?b=81efc0b8e3094942a81d01e311864270
170 2
188 2
126 2
豪华大床房
170 2
33 2
56 2
豪华双床房
145 2
2 2
188 2
观景豪华大床房
145 2
170 2
111 2
行政大床房
33 2
56 2
56 2
行政双床房
201 2
2 2
145 2
行政套房
2 2
2 2
33 2
188 2
尝试下载CSS背景图片:
browser.get(img_url)
结果又是被腾讯T-Sec Web应用防火墙(WAF)拦截的页面,说明直接用selenium下载图片行不通。
用request下载呢?经尝试也老是被拦截。
最终,写出了如下代码(还能较为顺利的获取图片数据):
import requests
from io import BytesIO
import base64
from PIL import Image
def download_img(img_url):
cookies = {o['name']: o['value'] for o in browser.get_cookies()}
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Host": "hotels.huazhu.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
for _ in range(10):
r = requests.get(img_url, headers=headers, cookies=cookies)
if r.status_code == 200:
break
else:
return None
img = Image.open(BytesIO(r.content))
return img
img = download_img(img_url)
img
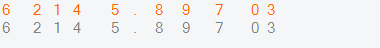
有了图片,我们就可以裁剪出相应的数字图片并进行拼接了。
对最后一条数据进行测试:

可以看到解析和拼接的效果非常不错。
然后测试批量的数据提取:
img_url = None
for tr in table.find_elements_by_css_selector("table tr[class^='room first']"):
name = tr.find_element_by_tag_name("h3").text
print(name)
price = tr.find_element_by_css_selector("div>a[class^='totalprice']")
var_el_s = price.find_elements_by_tag_name("var")
n = len(var_el_s)
target = Image.new('RGB', (10 * n, 17), color=(255, 255, 255))
for i, var in enumerate(var_el_s):
if img_url is None:
img_url = var.value_of_css_property("background-image")[5:-2]
img = download_img(img_url)
position = var.value_of_css_property("background-position")
w, h = map(lambda x: int(x[1:-2]), position.split())
r = img.crop((w, h, w+8, h+17))
target.paste(r, (10*i, 0), r)
display(target)

可以看到已经顺利的得到了需要的结果,与网站看到的数据一致:
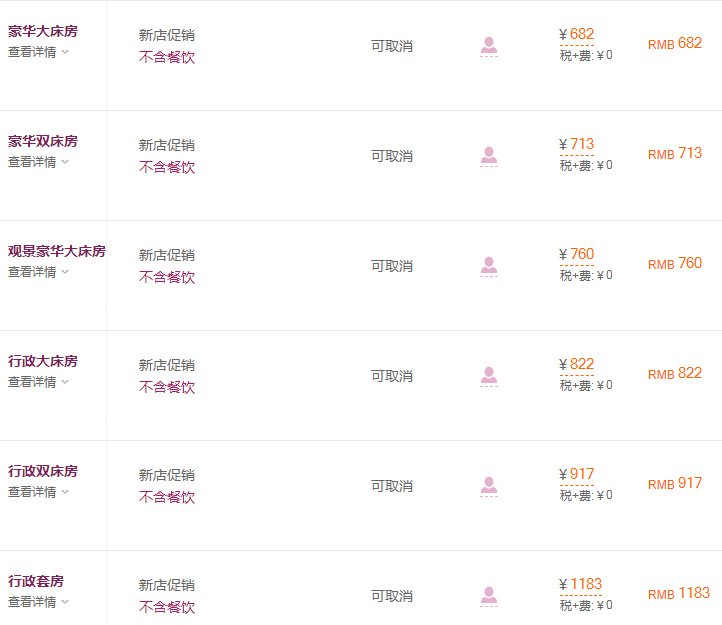
剩下的我们仅仅只需要对拼接好的图片进行图像识别即可,或者就直接原有图片形式保存。
图像识别
关于图像识别,有在线识别和离线识别两种方式。在线文字可以考虑使用百度云,腾讯云等,根据官网提供的接口进行操作。
下面呢,我们尝试进行离线文字识别,离线文字识别的准确率往往不如在线。
为了更好的识别效果,我们先对图片进行二值化处理:
def image_binarization(im, threshold=250):
Lim = im.convert("L")
table = [0 if i < threshold else 1 for i in range(256)]
return Lim.point(table, "1")
image_binarization(target)
下面我们需要安装pytesseract和Tesseract-OCR。
pytesseract是一个Python库:
pip insatll pytesseract
Tesseract-OCR则需要在https://digi.bib.uni-mannheim.de/tesseract/下载安装包。
由于网络原因,我在https://www.liangchan.net/liangchan/11545.html下载了一个。
项目地址:https://github.com/tesseract-ocr/tesseract
安装完成后,添加安装路径到path环境变量,命令行执行后出现如下提示说明安装成功:
C:\Users\ASUS>tesseract -v
tesseract v5.0.0.20190623
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0
Found AVX2
Found AVX
Found SSE
C:\Users\ASUS>
然后我们开始识别:
import pytesseract
text = pytesseract.image_to_string(image_binarization(target)).strip()
print(text)
1183
于是可以开始进行批量识别了:
import pytesseract
for tr in table.find_elements_by_css_selector("table tr[class^='room first']"):
name = tr.find_element_by_tag_name("h3").text
price = tr.find_element_by_css_selector("div>a[class^='totalprice']")
var_el_s = price.find_elements_by_tag_name("var")
n = len(var_el_s)
target = Image.new('RGB', (10 * n, 17), color=(255, 255, 255))
for i, var in enumerate(var_el_s):
if img_url is None:
img_url = var.value_of_css_property("background-image")[5:-2]
img = download_img(img_url)
position = var.value_of_css_property("background-position")
w, h = map(lambda x: int(x[1:-2]), position.split())
r = img.crop((w, h, w+8, h+17))
target.paste(r, (10*i, 0), r)
display(target)
text = pytesseract.image_to_string(image_binarization(target)).strip()
print(name, text)

从结果可以看到,识别的准确率还是非常高的,至少目前看到的全部都正确了。
版权声明:本文为CSDN博主「小小明-代码实体」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/as604049322/article/details/118401598
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~