算法分析交易描述文本,预测用户消费偏好
前言
随着第三方支付平台的涌现和支付场景的丰富,消费者越来越习惯于通过第三方支付平台进行支付,银行数据库中常用来表示消费类型的MCC码无法对这部分消费进行分类,覆盖正确率不足40%。为了对用户消费偏好进一步研究,本文通过对行内用户非结构化数据 ——交易描述的文本分析,来准确预测用户消费偏好,为银行营销活动提供切合用户需求的权益抓手以及行内产品设计创意,依托银行客户端技术的支持,实现千人千面的数字化精准营销。
银行数据应用——用户画像
近年来,银行数字化转型进程不断加快,对数据应用的探索也愈加深入。银行数据应用主要有五大类,包括数据分析、用户画像、模型预测、效果分析、风险控制,通常以业务为指导并反哺业务。其中用户画像作为数据的基础应用,在银行主要业务板块中发挥着越来越重要的作用。
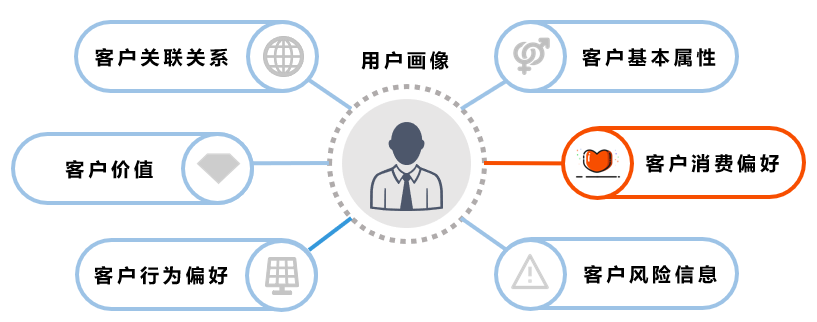
图1:用户画像的六大维度
为了更好地了解用户,银行通常利用行内外数据提取用户特征(基础特征、交易特征、行为特征等),将用户标签化,最终得到用户在某业务场景下的画像,并利用用户画像进行精准营销,提升各板块业务指标。
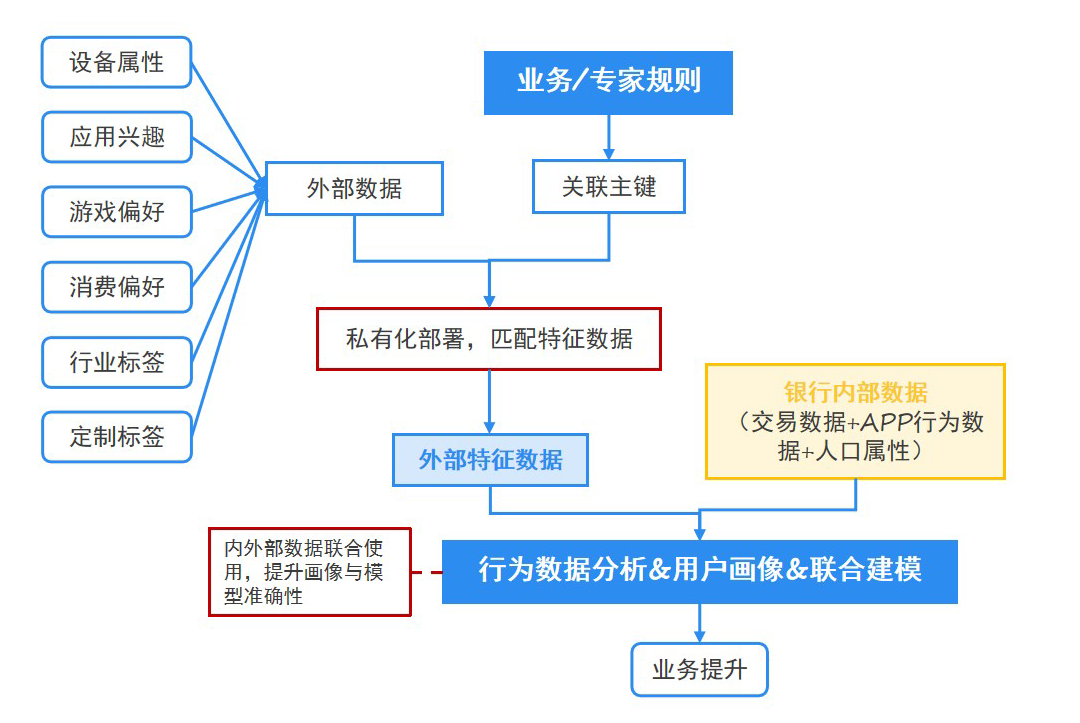
图2:内外部数据结合流程
这里的外部数据指在合规基础上接入的第三方数据合作商数据,通常包括用户应用列表、设备信息等;内部数据指行内交易数据,包括MCC商户类别码、交易描述等。
采购外部数据有利于更准确地定位用户偏好,但也存在三大弊端:
1 | 为了保证合规性,双方数据匹配需经过脱敏处理,此过程因耗时较长可能会影响数据时效性; |
2 | 外部数据的匹配率有限; |
3 | 单次采购数据成本较高,不可复用。 |
然而,目前利用行内数据对用户偏好的分析较为粗浅,大量非结构化数据未能充分利用。本文希望对行内交易描述数据进行深入探索,用以定位用户的非金融产品消费偏好。
用户消费偏好预测——交易描述文本分析
不同于购买行内产品,用户在其他场景的消费尽管难以为银行带来直接收益,却为银行打开了多维度洞察用户的窗口。通过分析用户的消费偏好,可以更好地了解用户的兴趣爱好、日常消费场景、消费需求,支撑精准营销与触达,利用用户感兴趣的权益福利、产品设计等实现营销目的(开卡、绑卡、激活、首刷、APP活跃等),因此对交易描述进一步分析是非常有必要的。
本文结合短文本分析研究与实践经验,总结出“交易类别预测+聚类模型预测”的方法论,来预测用户的非金融消费偏好。即首先落脚于交易描述,将每一条交易准确归类到消费的类别(餐饮、商旅出行、日用百货等)中;其次通过对用户一段时间内消费类别的分布情况,利用聚类模型将用户准确归类到某种消费偏好的标签下。
第一步:交易类别预测;
第二步:聚类模型预测;
第三步:得出用户消费偏好。
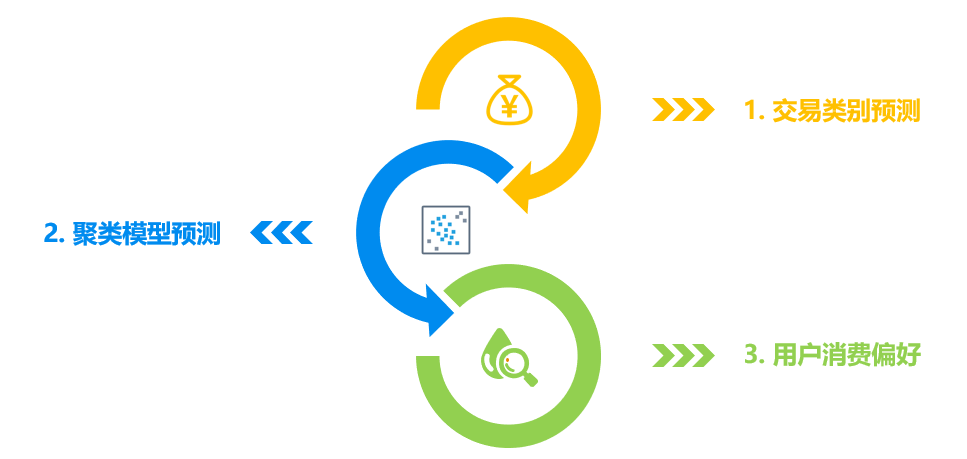
图3:用户消费偏好预测方法论
下文将结合实践详细讲述该方法论中的第一步,即如何运用文本分析进行交易类别预测。我们知道银行交易描述以短文本的形式展现,其中包含了交易支付平台、具体商户名称/消费品类等信息(如下图)。
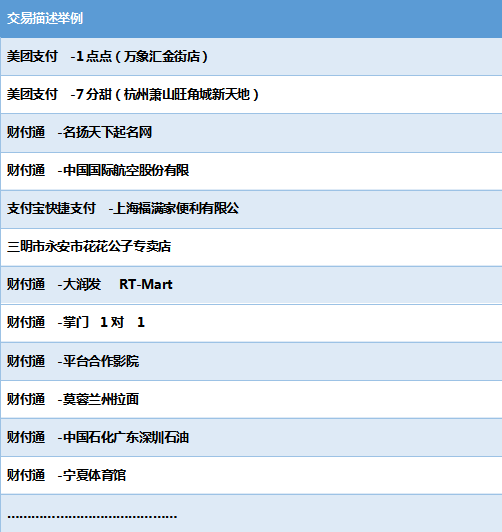
图4:交易描述示例
本文抽取20000条真实信用卡交易数据,采用算法模型预测和关键词匹配两种方式对交易描述进行分析,具体操作过程如下:
01
确定消费类型数量
根据历史业务需求以及数据情况,将所有交易归为19种交易类型,代码为0-19数字,并标注每条交易记录属于哪一类消费。
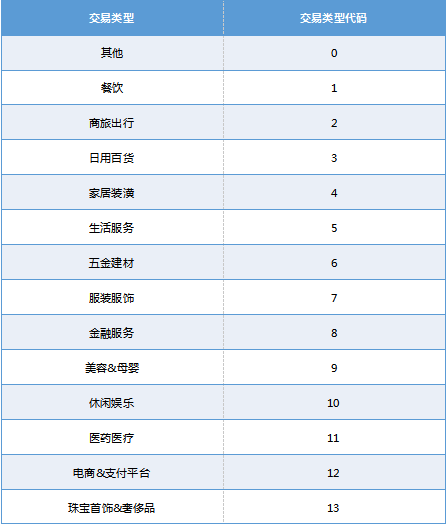

图5:交易类型分类
02
Jieba(结巴)分词
用Python对英文文本进行预处理时可选择NLTK库,中文文本预处理可选择jieba库。jieba分词是基于统计的分词方法,利用机器学习模型,从大量已分词的文本中学习词语切分的规律(即模型训练),从而实现对未知文本的切分。随着大规模语料库的建立与机器学习方法的研究和发展,基于统计的中文分词方法渐渐成为了主流方法。
jieba支持自定义词典,我们将本次项目中已知的关键词添加到词袋中,优化分词效果。
通过jieba.add_word函数将测试数据中标注的所有关键词添加到jieba中(如:兰州拉面、好利来、家得福、口留香等),具体代码如下:
jieba.add_word(k,freq=v,tag='n')
通过jieba.suggest_freq函数调节单个词语的词频,使其能(或不能)被分出来,词频越高,在分词时被分出来的概率越大,具体代码如下:
*左右滑动查看完整代码
jieba.suggest_freq(nonseglist,tune=True)
03
预测消费类型
本文采用了算法模型预测、关键词匹配两种方式进行消费类型预测,下面分别介绍:
a) 算法模型预测
首先,采用全模式输出,通过jieba.cut函数进行分词,得到原始语料。具体代码如下:
*左右滑动查看完整代码corpus = [' '.join(jieba.cut(line, cut_all = True)) for line in text['describe']]
图6:原始语料
其次,设置自定义的停用词。
在常用停用词库(如:的、认为、至、立即等)的基础上加入本次文本分析中的特殊停用词,例如有限公司、还款成功、网银跨行汇款等与消费类型无关的固定文本。这将大大优化后续模型预测准确性。
再次,建立TF-IDF向量空间。
TF-IDF用于评估一个词对于一个文件或语料库中某文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,随着它在语料库中出现的次数成反比下降。sklearn中提供现成的TF-IDF向量生成、向量转化类,可以轻松得到所需要的训练集、测试集TF-IDF矩阵。具体代码如下:
*左右滑动查看完整代码
stpwrdlst = readfile(stopword_path).splitlines() #读取停用词
vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf = True)
transformer = TfidfTransformer()
tfidf_matrix = vectorizer.fit_transform(corpus) #tf-idf矩阵
print(vectorizer.get_feature_names()) #得到不重复的单词
print(vectorizer.vocabulary_) #得到每个单词对应的ID
print(tfidf_matrix)
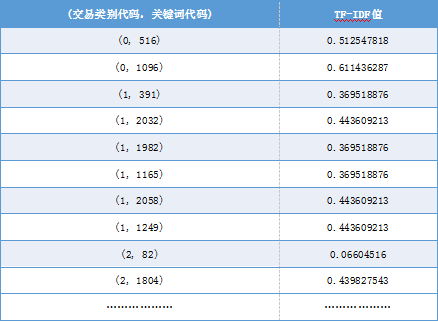
图7:TF-IDF矩阵
最后用朴素贝叶斯算法预测每条交易描述所属的交易类型,并计算预测错误率,经过多次训练,得到平均错误率低于30%,即正确率在70%以上。具体代码如下:
*左右滑动查看完整代码clf = MultinomialNB(alpha = 0.01).fit(train_tfidf_matrix, y_train)
predicted = clf.predict(test_tfidf_matrix)
total = len(predicted)
rate = 0
for text,true_label, pred_label in zip(X_test, y_test, predicted) :
if true_label != pred_label :
rate += 1
print(text,true_label, pred_label)
#打印精度
print ("error rate:", float(rate) * 100/float(total), "%")
具体结果如下图:
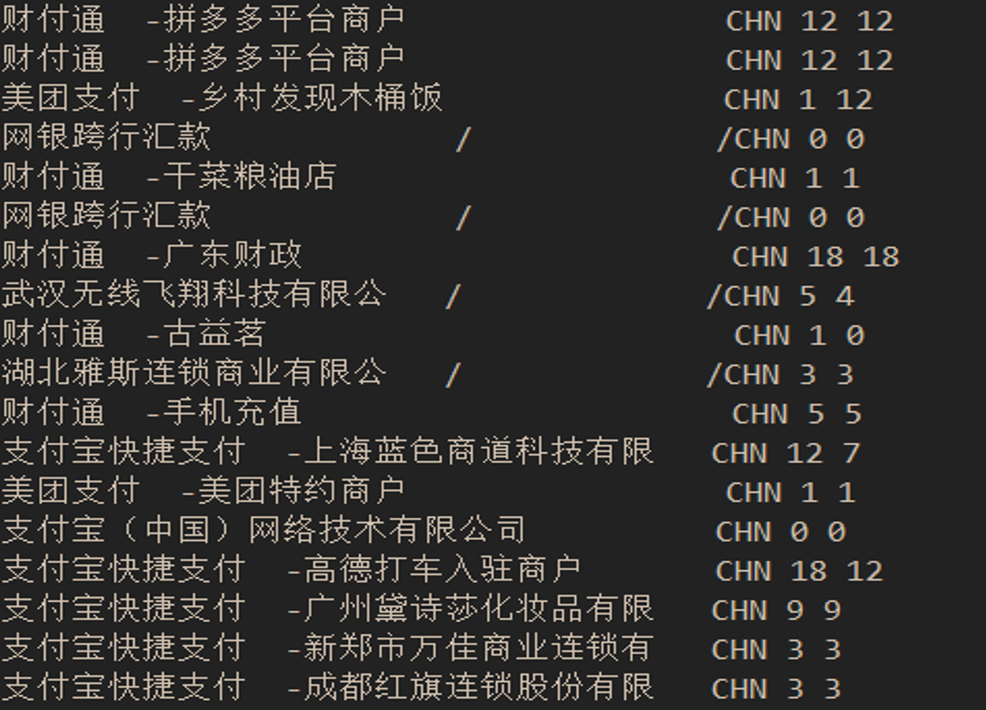
图8:实际交易类型&预测交易类型对比(交易描述、实际交易类型、预测交易类型)
b) 唯一关键词匹配
分词并提取唯一关键词
这里同样使用添加了自定义词典的jieba库。提取唯一关键词时尝试了两种方法,分别是TextRank与TF-IDF。这两种方法均严重依赖于分词结果,TextRank虽然考虑了词之间的关系,但是仍然倾向于将频繁词作为关键词。经过检验,TF-IDF方法的正确率远高于TextRank。
具体操作命令:
*左右滑动查看完整代码
jieba.analyse.extract_tags(s, topK=1, withWeight=True, allowPOS=('n','nr','ns'))
结果如下:
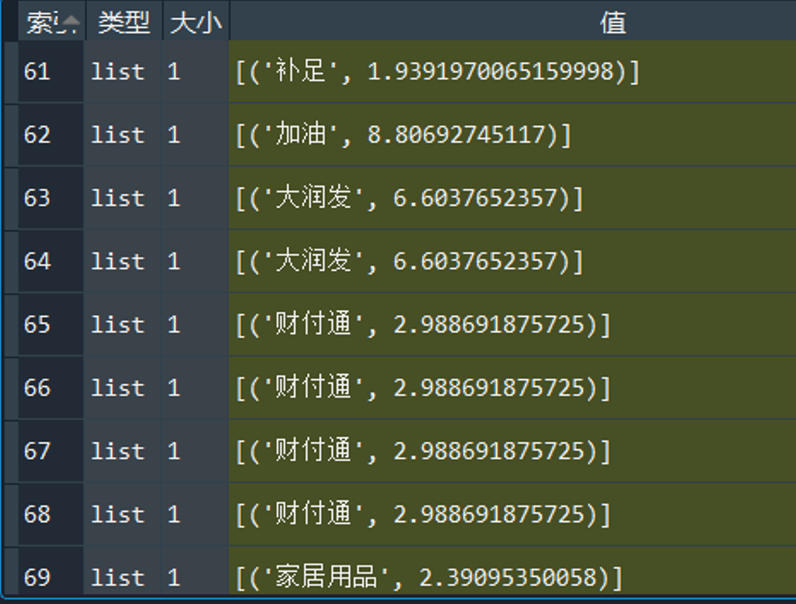
图9:提取唯一关键词结果展示
关键词匹配
根据开始的数据标注,将20000条记录中的关键词归类到19个交易类型中,形成19个小词库,代码为0-19数字。
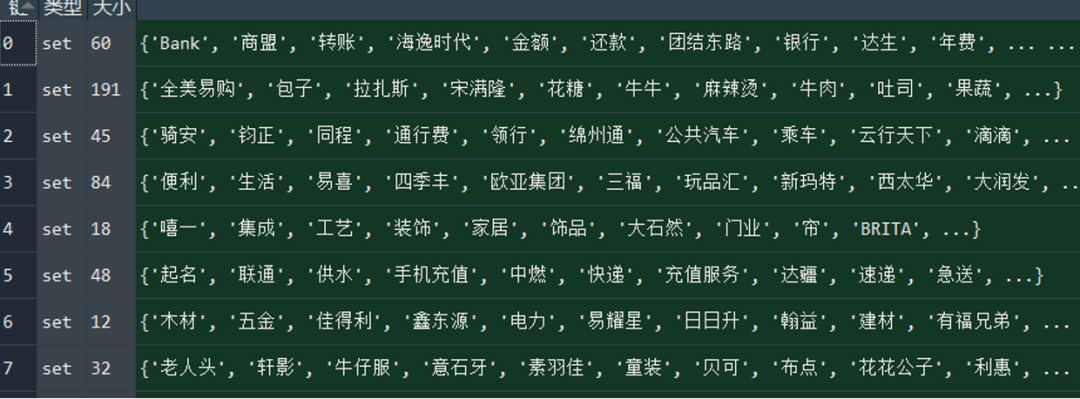
图10:关键词归类结果
再将上一步中jieba提取的唯一关键词分别匹配到19个小词库,若能匹配上则返回小词库代码(即交易类型代码),最终的预测正确率在45%左右。
结论
对比算法模型预测与唯一关键词匹配两种方法,预测交易类型的正确率分别为70%与45%,因此建议对交易描述这类短文本的分析采用算法模型预测方法。由于本次测试项目数据集仅20000条,后续需要不断更新自定义词典与停用词,优化预测效果。另外,对于“其他”交易类型的交易,可以结合MCC码等信息做进一步分析,提高预测准确性。
文本完成了用户消费偏好预测方法论中的第一步,即利用交易文本预测交易类型,如想实现对用户非金融消费偏好的了解,还需要进一步进行聚类分析,将某段时间内用户在19种交易类型中的交易次数或频次作为特征,采用无监督机器学习聚类算法进行预测,具体方式我们将在后续文章中进行介绍。
作者:TalkingData 金融咨询团队 王牧馨
转载请联系获取授权
推荐阅读:




TalkingData——用数据说话
每天一篇好文章,欢迎分享关注