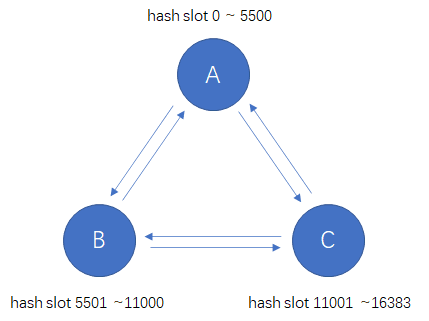
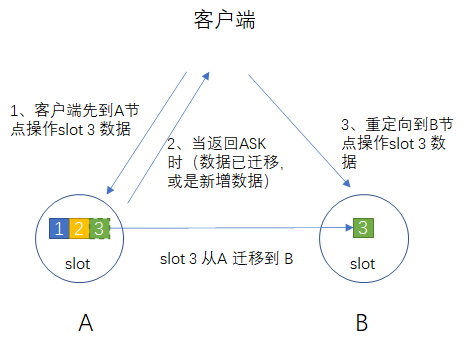
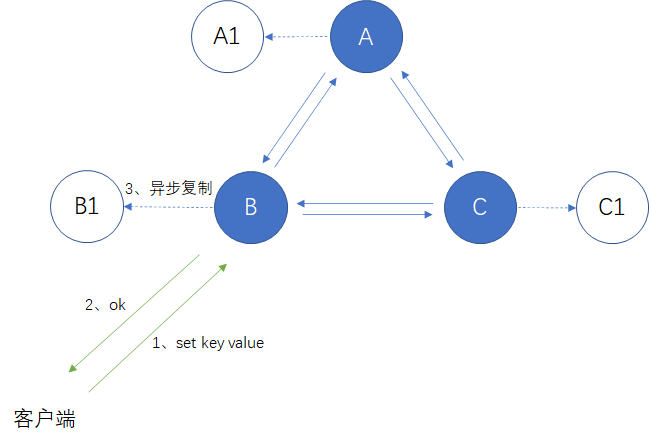
从Redis的集群设计中能够得到哪些启发?WU双关注共 2612字,需浏览 6分钟 ·2021-09-02 09:01 聊技术,不止于技术在大型的分布式系统中,我们都会听到集群的概念,比如Redis集群、ES集群等。那么集群主要的作用是什么呢?个人看来集群主要做了这几件事,或者说集群的设计主要为了解决如下问题:(1) 可扩展,好的集群设计可以实现近乎线性扩展,即存储和性能随着硬件的增加而线性增长;(2) 高可用,能够在部分节点故障时实现故障转移。今天让我们一起来看看Redis集群是如何设计来解决可扩展及高可用问题的,从中我们又能得到哪些启发。1Redis集群的可扩展设计Redis集群引入了hash slot的概念,实际上也就是数据分区,Redis集群总共有16384个hash slot,集群中的每个节点都会负责一部分hash slot。假如我们集群中有三个节点,那么:(1) 节点A将包含hash slot 0 ~ 5500;(2) 节点B将包含hash slot 5501 ~11000;(3) 节点C将包含hash slot 11001 ~16383。Redis集群通过计算每个key值的crc16值,然后对16384取模,来获得key对应的hash slot,实现数据写入/读取。HASH_SLOT = CRC16(key) mod 16384Redis之所以引入hash slot的概念,其实是为了方便集群的扩缩容,也就是提供了集群的可扩展性。当我们增加或是减少节点的时候,可以以hash slot为粒度来进行数据的迁移。对于有状态的集群来讲,要想实现可扩展,一定需要数据迁移的功能,数据迁移又涉及到迁移粒度,对于Redis来讲,数据迁移的粒度为hash slot,对于elasticsearch来讲,为shard分区。Redis集群允许我们动态的增加及删除节点。增加新的节点,我们可以迁移部分hash slot到新节点中,如果要删除节点,我们可以将待删除节点的hash slot迁移到其他节点,待迁移完成便可以删除相应节点。Redis集群的数据重分区不会对客户端产生影响,整个过程不影响客户端正常操作。那这是如何做到的呢?举个例子,假如我们正在把hash slot 3 从A节点迁移到B节点(hash slot的迁移会将该slot中的所有数据都迁移),在这个过程中客户端发起查询的key值在hash slot 3中:(1) 集群中的所有节点还是会将请求指向A节点;(2) 如果A节点中相应的key值还未迁移,则返回查询结果;(3) 如果A节点中相应的key值已经迁移,则A会将客户端查询重定向到B,由B处理并返回查询结果。在整个迁移过程中不会再在节点A上新创建key,新增的key值在hash slot 3中的,将在节点B中创建。数据迁移完成后,集群内会通过内部协议更新各个节点对应的hash slot信息,后续相应key的查询都会直接走B了。Redis集群通过将数据划分为hash slot,并且能够以hash slot为粒度进行数据迁移,从而实现集群了的可扩展性。通过与客户端的配合,也能够实现在集群扩展过程中的请求不中断。2Redis集群的高可用设计因为Redis本身是有状态的,而对于有状态的应用来讲,高可用的实现方式就是复制。Redis集群的高可用是通过主从复制来实现的。假设Redis集群有三个主A、B、C,他们的从节点分别为A1、B1、C1,当主节点A挂掉后,故障切换流程如下(简化流程):(1) 节点A挂掉,集群将选举A1为新的主节点,然后继续提供服务;(2) 在新的主选举成功之前,部分读写请求会返回失败;(3) 重启节点A,它会作为从节点重新加入集群。谈到了主从复制,一个无法回避的问题是数据一致性。性能与一致性之间,我们需要做个取舍。Redis选择了性能。Redis集群无法保证强一致性,因为Redis的主从复制采用的是异步的方式。Redis的数据写入流程如下:(1) 客户端向master B写入数据;(2) master B返回OK;(3) master B向自己的从节点B1发送写入数据。可以看到master B在返回客户端OK的时候,没有等待确认从节点的数据写入。所以虽然master B返回写入成功,但如果它在向从节点发送数据之前挂掉,那么重新选举产生的主节点将丢失该数据。这其实是在性能与一致性之间的权衡。如果采用同步复制,也就是在确认了从节点的数据写入成功后在返回给用户,那么我们将获得数据一致性,但牺牲了性能。可以看到,性能与一致性在分布式系统中的取舍,目前来看是一个无法打破的理论性约束。3Redis集群的客户端集群同样需要客户端的支持。从单节点变成了集群,客户端最基本的支持也得需要支持配置多个节点ip,从而能够将请求发送给集群中各个节点。Redis客户端更进一步能够缓存hash slot与各个节点间的路由信息,从而能够直接将请求发送给相应的节点,进一步提升性能。可以看出,完整的集群方案设计,不光光是集群服务端的事,客户端也是需要考虑的一个很重要的地方。两者结合,才能发挥出更好的效果。写在最后如今的计算机系统中,集群是越来越常见的概念。集群的设计主要用来解决如下两个问题:(1) 可扩展;(2) 高可用。可扩展即存储和性能能够随着硬件的增加而近乎线性增长。高可用即能够在部分节点故障时实现故障转移。可扩展需要通过数据迁移来实现,数据迁移又涉及到数据迁移粒度,Redis集群中迁移粒度为hash slot,其他的集群实现中也有类似的数据迁移粒度概念。对于有状态的系统来讲,高可用只能通过复制来实现。复制又不可避免的会遇到数据一致性与性能之间的权衡。目前理论限制下,只能二选一。集群的设计不光光是服务端的事情,也需要客户端的支持。二者结合,才能够发挥更好的效果。今天主要讲解了Redis集群的设计,相信其中的一些设计思想能够对我们有所启发。推荐阅读:《微服务中的灰度发布是什么?实现思路又是什么?》聊技术,不止于技术。在这里我会分享技术文章、管理知识以及个人的思想感悟,欢迎点击关注。 浏览 51点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 从“年轻人读毛选”,书店能得到哪些启发?阑夕0从婴儿的语言天赋得到的启发深度学习视觉0Redis集群的搭建Java老铁铁0Redis集群模式数据库干货铺0Redis 集群搭建PHP在线0Redis 集群篇JavaKeeper0从SHIB这些百倍币的造富运动中得到的启发以及币圈投资思路区块链末班车0redis-go-clusterGo 实现的 Redis 集群客户端redis-go-cluster是基于Redigo实现的GolangRedis客户端。redis-go-cluster可以在本地缓存slot信息,并且当集群修改的时候会自动更新。此客户端管理每个节点连redis-go-clusterGo 实现的 Redis 集群客户端redis-go-cluster 是基于 Redigo 实现的 Golang Redis 客户端。rStaircarTumblr的Redis集群控制层Tumblr是世界上最流行的轻博客服务,其用户量在最近的一次统计中已经达到2090万,超过了全球最大的博客服务WordPress。而我们今天要介绍的是Tumblr通知系统的架构,其通知系统由一个叫St点赞 评论 收藏 分享 手机扫一扫分享分享 举报

 下载APP
下载APP