
英伟达「核弹级」GPU A100不敌AMD?比起算力,CUDA才是核心武器

新智元报道
新智元报道
编辑:小咸鱼 好困
【新智元导读】AMD自从进军GPU领域后,一直想要挑战一下英伟达在GPU市场的领先地位。周一,AMD发布了最新一代数据中心GPU Instinct MI200加速器,声称其最高性能是英伟达A100 GPU的4.9倍。但Reddit网友并不买账,他们认为AMD在人工智能方面所做的工作比英伟达少得多,尤其是难以和CUDA抗衡这一点。
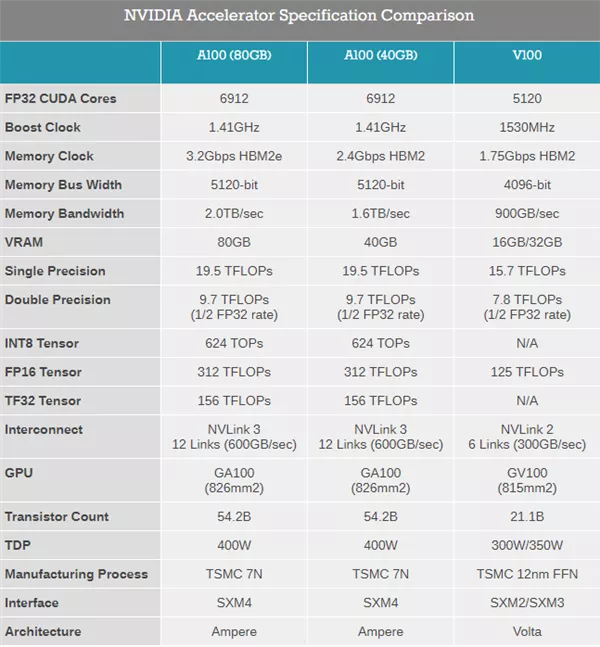
英伟达 A100 VS AMD MI200
英伟达 A100 VS AMD MI200




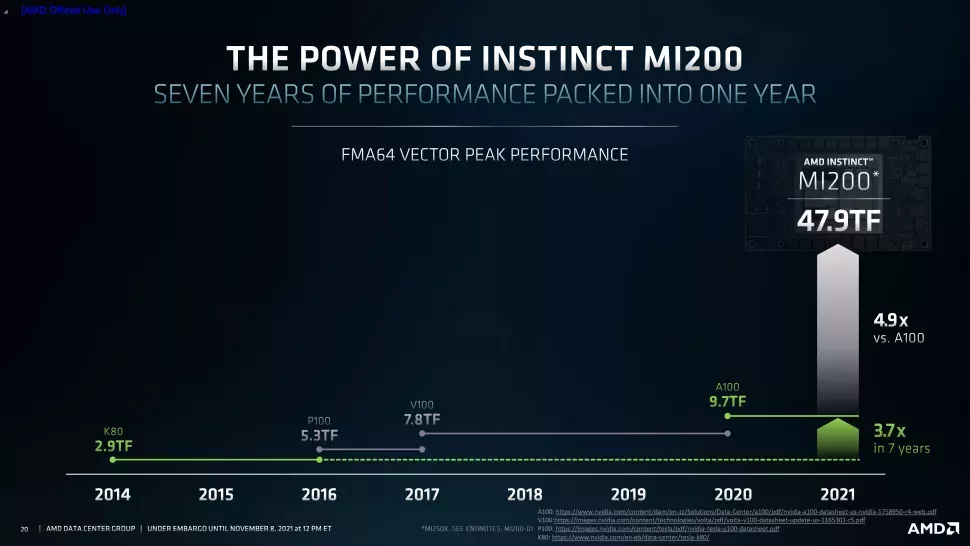


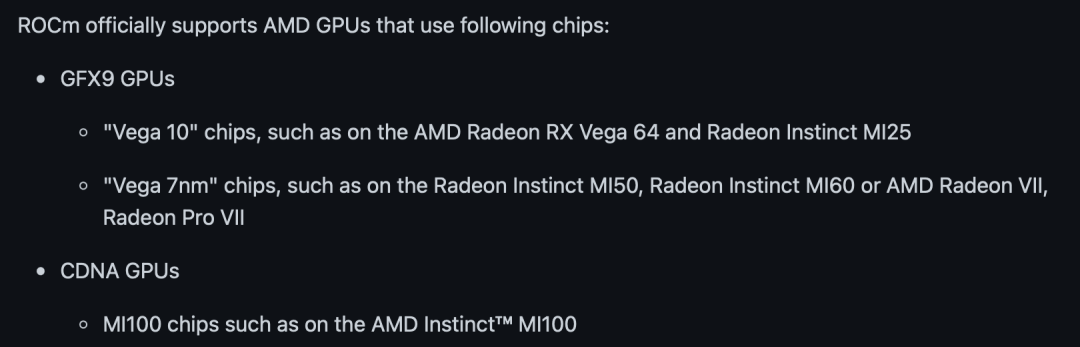
CUDA VS ROCm




参考资料:
本文引用了以下知乎网友的回答:
「三十一级火法」
https://zhuanlan.zhihu.com/p/80531243
「Huisheng Xu」
https://www.zhihu.com/question/447729368/answer/1765993650
https://www.zhihu.com/question/434685319/answer/1627612611

评论