
如何基于RFM和AHP构建用户评分分析体系
花花是某电商公司的一名产品运营,如果新上线一款产品他的一贯做法都是做活动、蹭热点、做营销等等。但是,这些做法引来了大量的羊毛党,获取的真实客户却是屈指可数。
正在花花为此事头疼之际,同组的前辈豆豆给他支个招,运用 AHP 和 RFM 构建用户评分体系,精细化运营,能带来很好的效果。开心之余,花花赶紧使用度娘搜索,AHP 和 RFM 究竟是什么东西?又怎么运用呢?接下来作者就给你唠叨唠叨。
1
AHP制定权重
1.1
AHP是什么?
层次分析法(Analytic Hierarchy Process)简称 AHP,20 世纪 70 年代中期由美国运筹学家托马斯·塞蒂(T·L·Saaty)提出。
AHP 是指将与决策有关的元素分解成目标、准则、方法等层次,主要用于定性的问题进行定量化分析决策。
比如,某电商平台根据用户行为数据对用户做综合评分模型,找出忠诚用户、活跃用户、沉默用户等等,进而对各类用户进行精细化运营。
1.2
AHP基本原理
AHP 的思路是密切的和决策者的主观判断以及推理联系起来,也就是对决策者的推理或者判断过程进行量化,从而避免决策者在结构复杂或方案较多时逻辑推理失误。具体步骤如下:
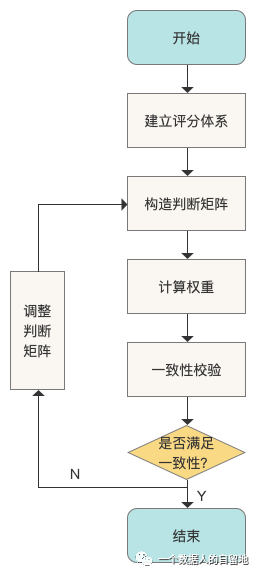
1)建立评分体系
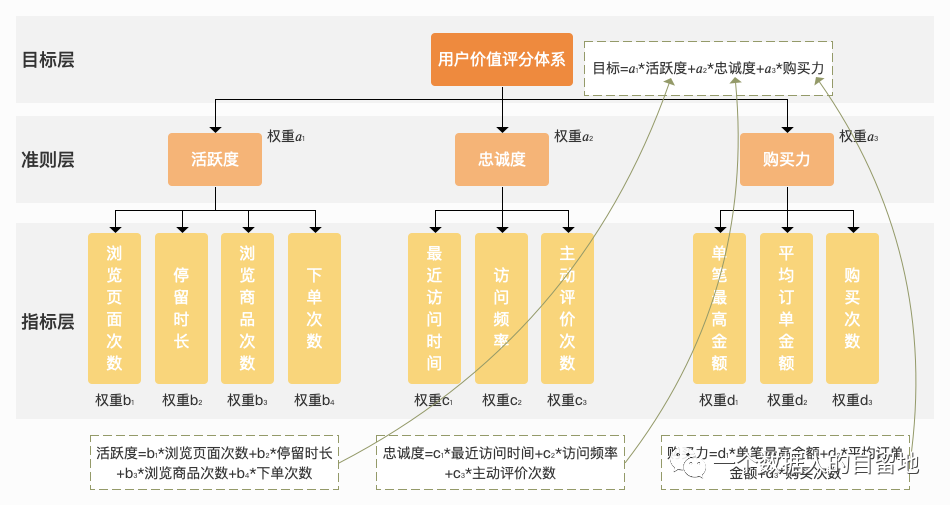
构建用户价值评分体系,对各类用户进行精细化运营。
设定目标,列出影响目标的所有元素。采用专家打分、用户问卷等方式,逐一列出所有的影响因素,比如活跃度、忠诚度、购买力等。
2)构建层次结构、判断矩阵
列出影响因素的指标或方案。
判断影响用户活跃度的指标有浏览页面次数、停留时长、浏览商品次数、下单次数。
判断影响用户忠诚度的指标有最近访问时间、访问频率、主动评价次数。
判断影响用户购买力的指标有单笔最高金额、平均订单金额、购买次数。
3)算出权重系数
分别算出各个指标层、准则层的指标权重,然后再算出决策公式(如下图)。
4)一致性校验
若一致性指标 CR<0.1,就进入下一环节;否则,对各指标权重重新赋值(即,重新构建判断矩阵)。
5)层次排序
层次排序分为层次单排序和层次总排序。所谓层次单排序,指对于上一层某因素而言,本层次各因素的重要性的排序;所谓层次总排序,指确定某层所有因素总目标相对重要性的排序权值过程。
层次排序是从最高层到最底层依次进行的。对于最高层次而言,其层次单排序的结果也是总排序的结果。
1.3
确定权重
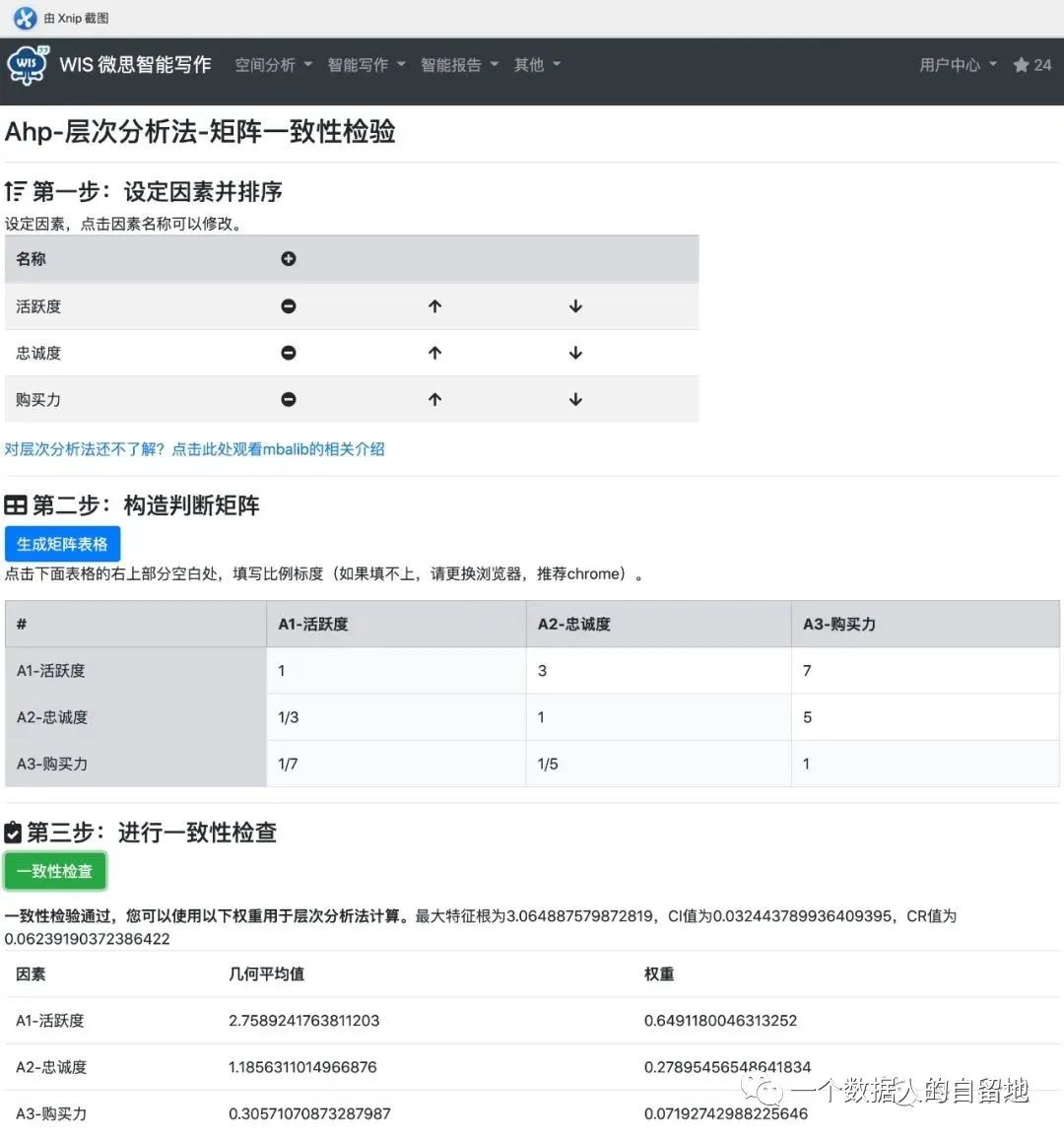
1.3.1 构建判断矩阵
在确定各层次各因素间的权重时,如果仅是定性的结果,则通常不容易被其他人接受,因而 Saaty 提出一致性矩阵法,即两两因素相互比较,采用标度,尽可能减少不同因素相互比较的困难,以提高准确度。
运用专家打分将所有因素两两比较确定合适的标度。建立层次结构后,比较因子及下属指标的各个比重,实现定性向定量转化。
比如,采用 1-9 分标度法,构建决策层的打分矩阵 A,如下图。
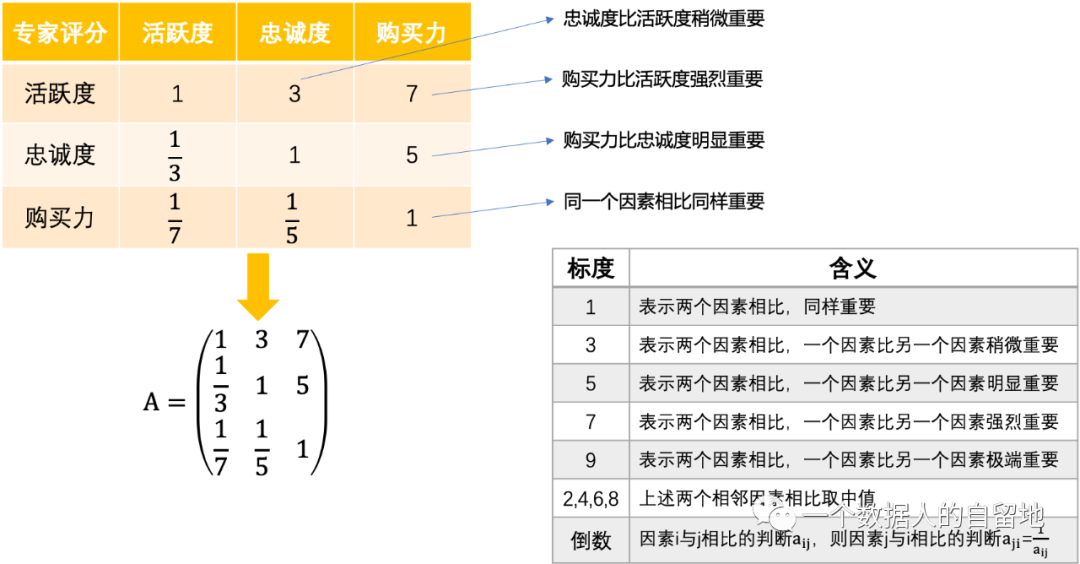

实际上,上述打分矩阵就是层次分析法中的判断矩阵。
1.3.2 一致性检验
一致性检验是为了检验各元素重要程度之间的协调性,避免出现 A 比 B 重要,B 比 C 重要,而 C 又比 A 重要,这样的矛盾情况。
1)相关理论
(1)一致性矩阵

(2)判断矩阵是否为一致性矩阵

在判断矩阵的构造中,并不要求判断矩阵一定具有一致性,这是由客观事物的复杂性和人的认识多样性决定的。但判断矩阵是计算排序权向量的依据,因此要求判断矩阵应该满足大体上的一致性。
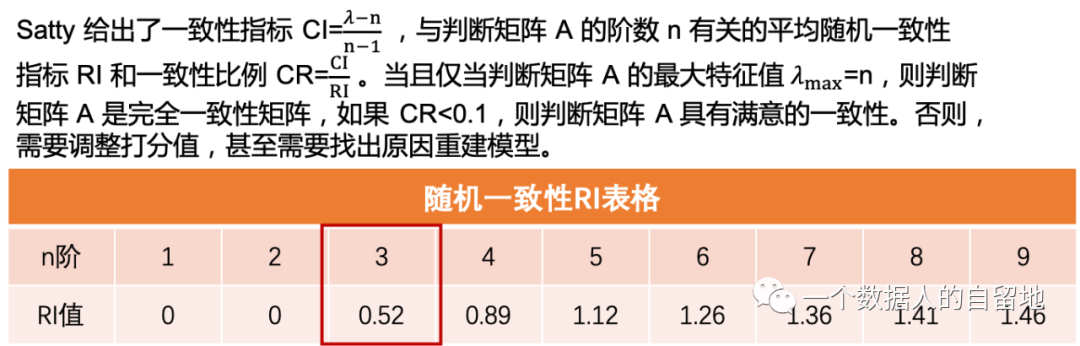
2)对判断矩阵一致性校验
先求解特征向量,采用手工计算方法——和积法:

手工计算矩阵 A 的特征值:
(1)求特征向量

(2)求最大特征值
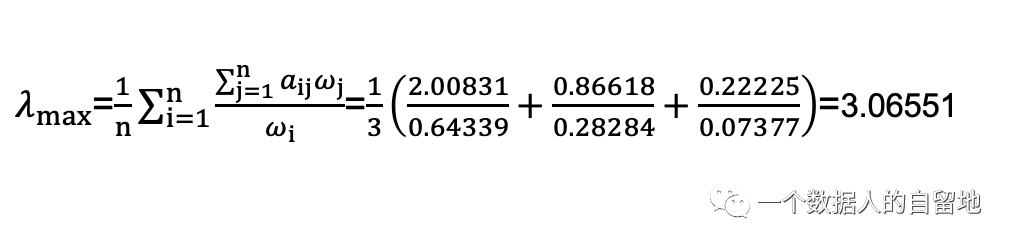
手工求解精确度较低,只是求得最大特征值的近似值。一般情况下,可以采用在线计算工具 Matlab,链接地址:https://wis-ai.com/tools/ahp
(3)一致性校验


1.3.3 计算指标层权重
1)计算活跃度的权重
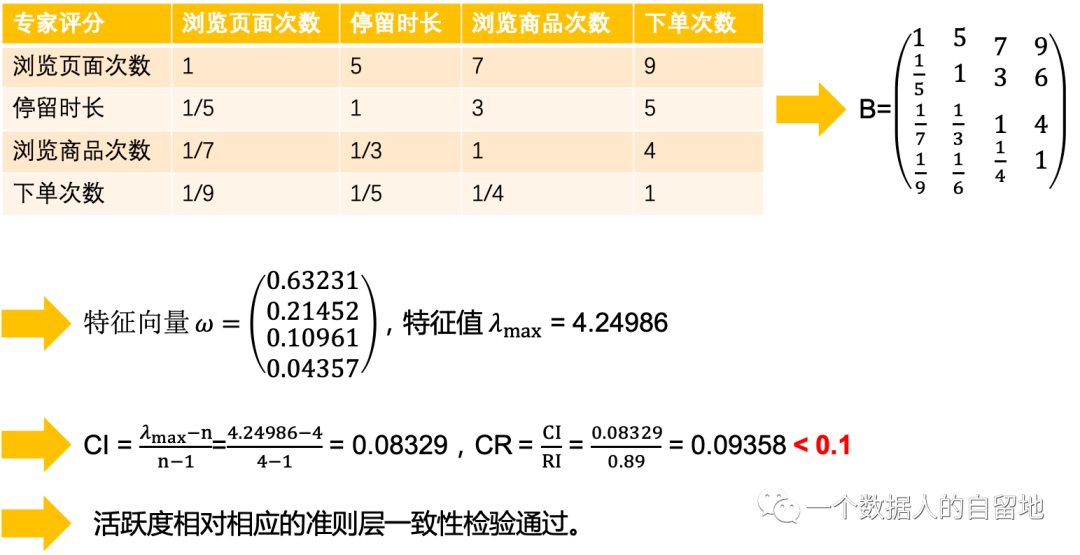
因此,准则层相对活跃度的权重依次为:
浏览页面次数的权重:b1=0.63231
停留时长的权重:b2=0.21452
浏览商品次数的权重:b3=0.10961
下单次数的权重:b4=0.04357
2)计算忠诚度的权重
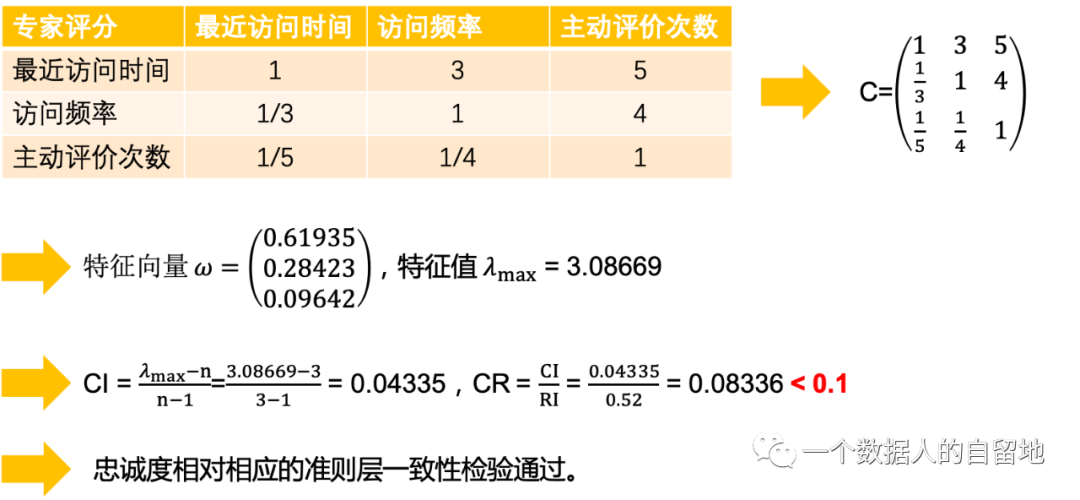
因此,准则层相对忠诚度的权重依次为:
最近访问时间的权重:c1=0.61935
访问频率的权重:c2=0.28423
主动评价次数的权重:c3=0.09642
3)计算购买力的权重

因此,准则层相对购买力的权重依次为:
单笔最高金额的权重:d1=0.70706
平均订单金额的权重:d2=0.20141
购买次数的权重:d3=0.09153
4)列出全部权重
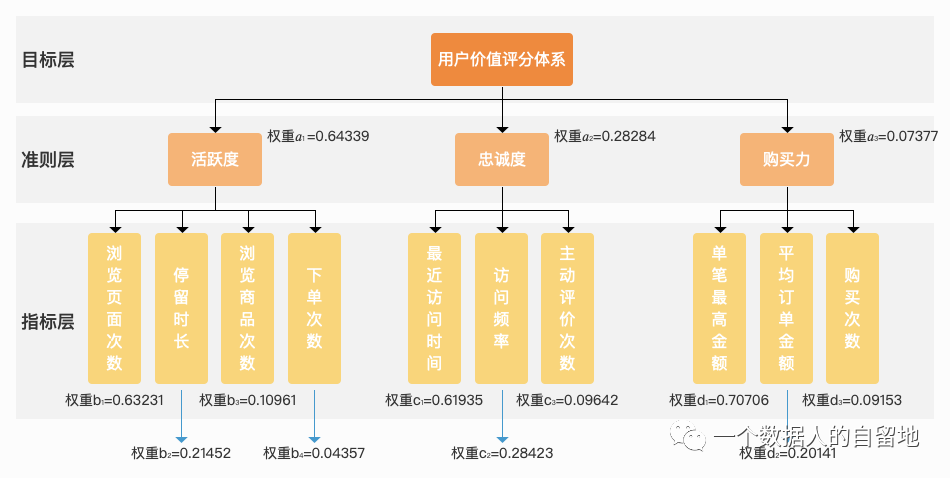
5)如果一致性校验没有通过,怎么办?
作者在实际构建评分矩阵时,发生了好几次一致性校验不通过(如 CR>=0.1)。这可能由于一些主观因素导致,也可能是由于构建模型不合理导致。所以需要专家重新构建打分矩阵,甚至需要重新构建层次分析模型。
(1)构建模型影响
因素是否合理、含义是否清晰、要素间是否重叠,这都会有影响。建议每层要素尽量不超过 7 个;如果元素之间的强度相差很大,尽量不要放在同一个层级。
(2)计算精度影响
特征值求解方法的不同(比如和积法、方根法等)、Excel 计算值的误差、计算工具的误差等,都可能导致一致性校验结果有些偏差,可以使用 Matlab 等精度更高的计算工具(https://wis-ai.com/tools/ahp),如下图。
6)结论
运用 AHP 模型得出和公式:
活跃度=b1*浏览页面次数+b2*停留时长+b3*浏览商品次数+b4*下单次数;
忠诚度=c1*最近访问时间+c2*访问频率+c3*主动评价次数;
购买力=d1*单笔最高金额+d2*平均订单金额+d3*购买次数;
用户价值评分=0.64339*活跃度+0.28284*忠诚度+0.07377*购买力。
AHP 方法使用较少的定量数据,就可以构建模型,最终的结论只能表明因素的重要程度,不能得出用户价值的评分值是多少。
因此,将 RFM 模型和 AHP 模型相结合,算出各个因素的分值,得出每个用户的评分。
2
RFM计算分值
2.1
RFM是什么?
RFM 模型是衡量客户价值和客户创利能力的重要工具和手段。该模型通过一个客户的近期购买行为(Recency)、购买的总体频率(Frequency)以及消费金额(Monetary)3 项指标切分出多类客户,最后根据不同类型客户(如下图)占比情况来评估客户的整体分布,并针对不同类型的客户进行有针对性的营销。

一个 RFM 用户分层模型,重要发展客户到底多少分?一般价值客户多少分?作者将用某电商公司 2018 年 11 月 1 日-2019 年 4 月 30 日共 5 个月的交易数据来讲述,为了保护隐私,数据经过脱敏处理。
2.2
构建RFM模型的步骤
2.2.1 获取与清洗数据
RFM 模型主要用于分析用户购买行为,通常获得的数据包含付款时间、实付金额、订单状态等等信息的数据,部分数据如下图。

获得数据后,其中可能存在空值、异常值等情况,这类脏数据无法进行分析,需要通过简单的数据清洗去除。数据清洗的方式有两类:异常值处理,如删除、均值补差等;异常值识别,如按业务规则查找、语义冲突等。
比如,作者获得交易数据后,发现 “发货时间” 为空,是脏数据,需要剔除;对应 “订单状态” 的值是 “付款以后用户退款成功,交易自动关闭”,退款用户数据不该纳入模型,需要去除。
清洗完之后,分别对 “发货时间”、“订单状态” 进行筛选,这时发现 “发货时间” 为空或订单状态为 “付款以后用户退款成功,交易自动关闭” 这类数据已经不存在了,说明已经筛选干净了。
2.2.2 建立模型
接下来,作者需要提取 R、F、M 的值:R(最近一次购买距今天的天数)、F(购买了几次)和 M(平均购买金额)。
构建一张透视表,将 “买家昵称” 分别拖到行位置和值位置,对 “买家昵称” 进行计数汇总,也就是得出买家的消费次数,即 F 值。将 “付款时间” 拖到值位置,设为最大值,将 “实付金额” 拖到值位置,设为平均值,即 M 值,如下图。
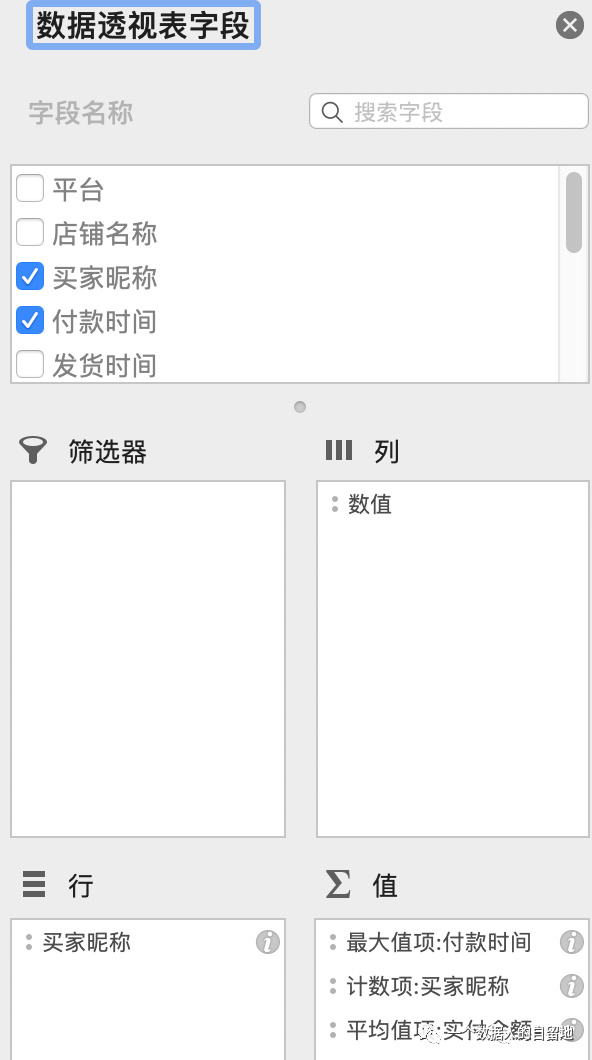
将初步透视好的数据复制到一张新的表格(选择性粘贴「值和数字格式」)。接着处理 R 的值,由于订单截止日期是 2019 年 4 月 30 日,作者将建模时间设为 2019 年 5 月 1 日,求距离 5 月 1 日这一天客户最近一次付款时间的间隔天数,就是求每个客户的 R 值,如下图。

用 RFM 的计算方式,对所有因素(R、F、M)进行 0-5 评分区段的映射。

或者用下面的公式归一化处理(如下图),正相关使用第一个公式,负相关使用第二个公式,R 属于负相关,因为最近一次购买时间距越小,那么越重要。F 和 M 都是正相关。
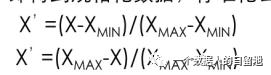
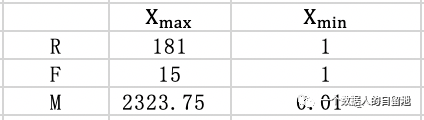
规范化计算也可以使用 (X-Xmin)/均值(X) 和 (Xmax-X)/均值(X) ,需要注意的是,如果真实数据分布不平均的话,均值就可能出现偏差,比如有人消费 100 万元,有人消费 1000 元,平均数的偏差就很大。所以,可以使用三分位、中位数或者(Xmax-Xmin)等方式进行归一化。
由于获取的数据字段有限,无法通过指标层得到准则层的权重,所以直接使用 AHP 算出活跃度、忠诚度和购买力的权重,依次分别是 0.64339、0.28284、0.07377。得出标准化的数据以及一定权重的用户价值,如下图。
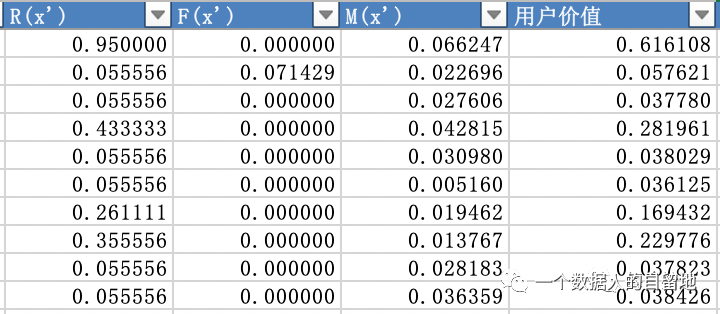
把 R、F、M、用户价值按照 0、1 区分,如果大于均值为 1,否则为 0,得到 16 种用户类型,如下图。
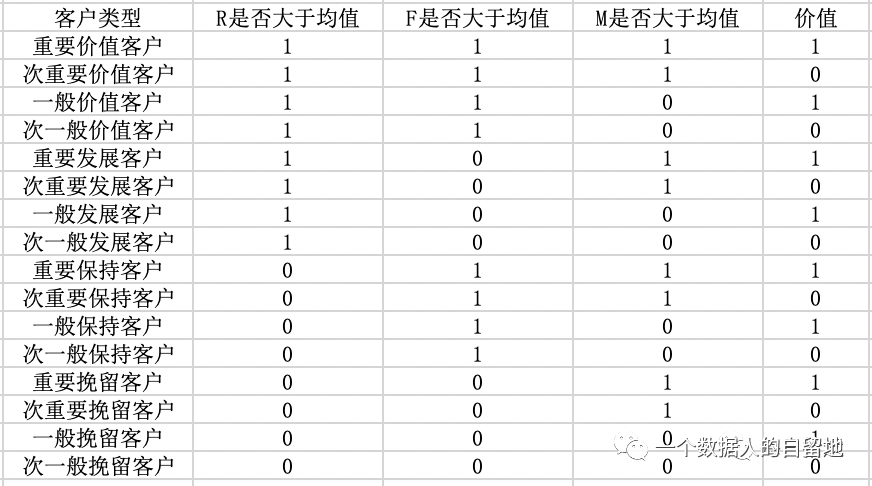
将用户类型代入数据中,得出的部分结果,如下图。

2.3
模型可视化
2.3.1 分析各类客户占比
对刚刚完成 RFM 模型表格进行透视,将 “客户类型” 拖至行区域,再把 “客户类型” 拖至值区域两次,第一次是为了计数,第二次是为了查看客户占比,如下图。
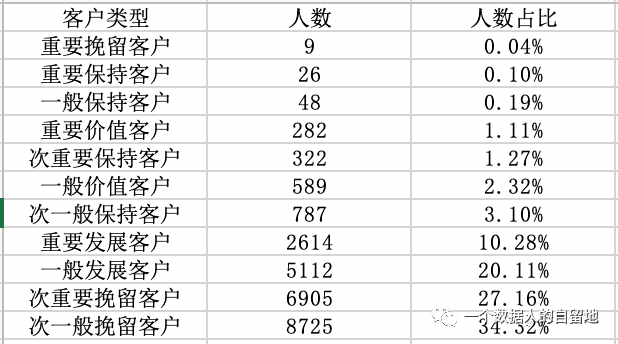
绘图,更清晰的查看不同客户类型的用户数占比,如下图。

2.3.2 分析客户金额占比
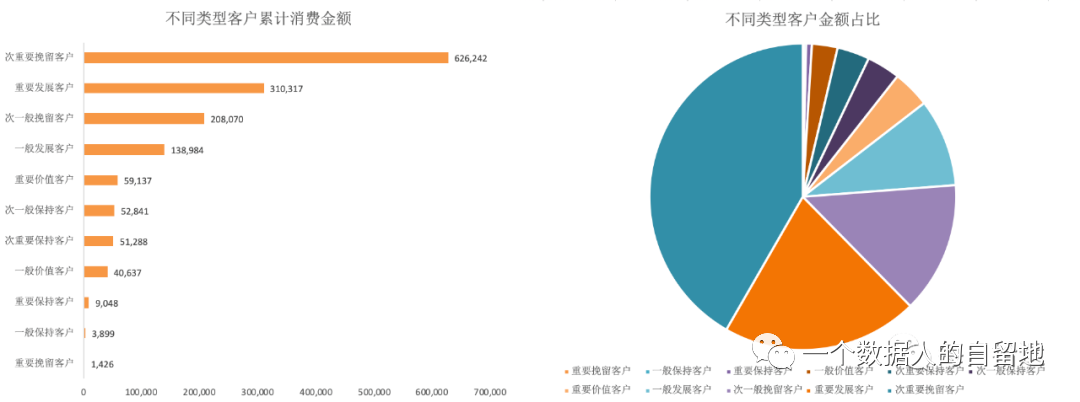
对 RFM 模型表格进行透视,将 “客户类型” 拖至行区域,再把 “累计金额” 拖至值区域两次,第一次是为了计算每类客户的累计消费金额,第二次是为了查看每类客户的金额占比,如下图。
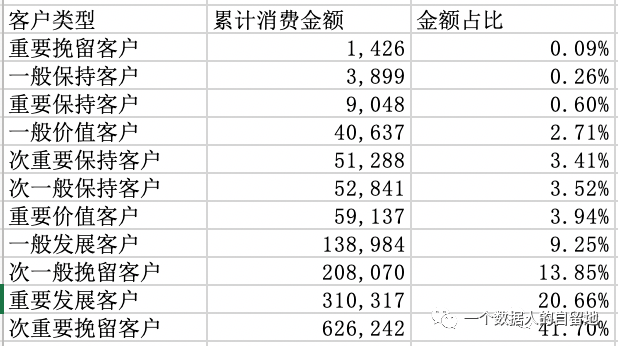
绘图,更清晰的查看不同客户类型的金额占比,如下图。
3
总结与建议
1)从各类客户占比图中看出,次一般挽留客户(0000)的人数最高,竟达 8725 人,人数占比 34.52%,此类客户近期没有购买,购买频次低于平均值,下单平均金额比较低,并且用户价值也较低,大约在 2018 年 双11 下的单,属于价格敏感性客户,所以可以在促销活动(如国庆节、六一等)时试着唤醒他们。
2)次重要挽留客户(0010),最近没有购买商品,消费频率较低,消费金额较大的一类客户,有 6905 人,人数占比 27.16%,支付金额占比最高。换句话说,对于该商家销售额贡献率最高的一批客户,下单时间远,购买次数低,已经处于流失的边缘,但是不同于次一般挽留客户,这类客户的平均销售额较高。
对于这类客户,运营人员需要获取他们的联系方式,进行回访,询问客户沉睡的原因;或者说商品本身就属于复购率低、消费金额占比高的商品;或者从商品本身入手,试着比较客户购买时间与商品的回购日期,是不是上次购买的商品还没有用完。
3)重要发展客户(1011),最近购买,购买频次低,消费金额大,用户价值大的客户有 2614 人,占总人数的 20.28%,支付金额相对较高。这类客户大致是新客户。
对于这类客户,运营人员近期适当的进行短信推送,优惠券发放等形式,来提高他们的购买频率,争取提高这类用户的忠诚度,最终将他们转变成重要价值客户。

推荐阅读
欢迎长按扫码关注「数据管道」