
如何做用户分层或用户分群

技术角度下的用户分群
单维度的组别划分
多维度的类别组合
聚类算法得到的分类
业务角度下的用户分群
用户属性
用户行为
用户价值
生命周期
其他补充
用户分层和用户分群是经常在工作中被提到的两个词,有的场景下这两个词的可以理解为同一含义,不过严谨来说:
“分层”有顺序或者嵌套的关系; “分群”则更多是“分类”的含义,类似于MECE的平级并列关系;
为了方便讨论,本文主要以“用户分群”的概念来进行讨论。另,本文只能算作一个纲要,“用户分群”的内容包含但不限于文中所及。
可以从两个角度来看“用户分群”:
技术角度,从数据上来看是怎么做的; 业务角度,即业务上对用户进行划分方法;
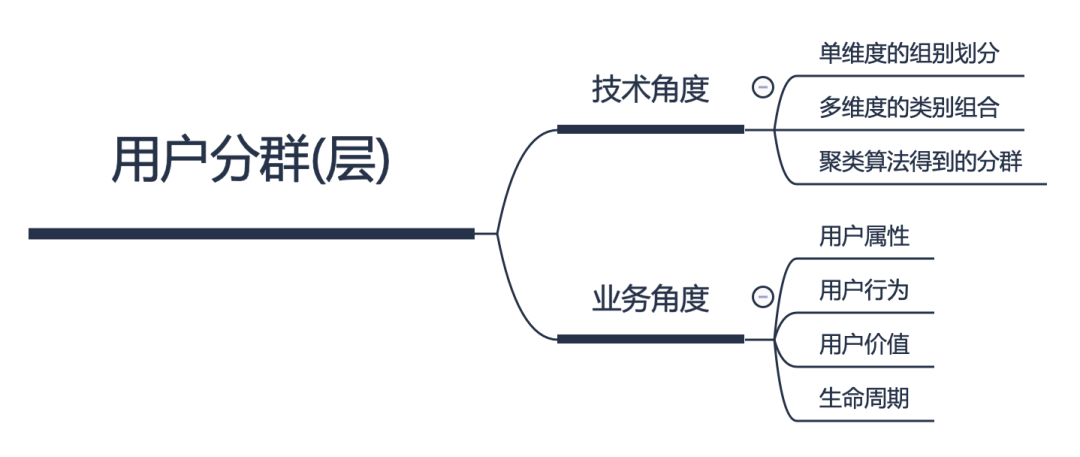
技术角度下的用户分群
主要有如下3类方法:
单维度的组别划分; 多维度的组合,再划分组别; 使用聚类算法来得到分组;
单维度的组别划分
用户的一系列属性值可以看做一个个变量。变量取值可能存在两种情况:
离散值,常见的是是否标记(e.g. 是否为付费用户)、类别归属(e.g. 收货所在省、支付状态)、等级顺序(e.g.会员等级);连续值,常见的有时间(e.g. 注册时长、使用时长)、金钱(e.g.交易金额)、频次(e.g.订单数量),连续值可以进行二值化或者分箱得到组别划分,比如考试成绩设定分数线来判定合格或不合格;
多维度的类别组合
多维度下的分组是可以通过多个已经分类的维度进行排列组合得到。
e.g. 两个维度进行组合得到的BCG/GE矩阵
e.g. 3个维度进行组合得到的RFM模型。
聚类算法得到的分类
前两者更依赖于先验的业务知识来进行划分,聚类算法则是从底层数据发现规律,可能会得到业务上可能不能解释但是却能带来业务价值的分组。
从技术上讲,聚类算法也是多个维度的数据衍生出一个新的分类字段,但是不同于多维度的组别划分那样,所使用的多个维度本来就是分组的,只是对分组进行组合即可。而聚类算法对于所使用的原始的多个变量并不在乎其取值是连续还是离散的,最终输出的是离散的类别就行。
业务角度下的用户分群
主要方法如下:
用户属性,e.g. 用户在产品中扮演的角色、用户的产品属性、社会属性等; 用户价值,通常和用户能带给产品的收入有关,28法则或者金字塔法则是用户价值的划分的两个常用规则; 用户行为,用户对产品的认知、选择产品的决策过程、用户从新手到忠诚发生的变化等都可以从用户的行为上得到洞察; 生命周期,这个生命周期是相对于用户在产品中的经历而言,从不知道某个产品->初次使用->建立信任->成为忠诚用户->流失,这个过程中体现了用户认知的变化,还涉及用户的决策过程的循序渐进以及用户需求的衰退或者转移;
用户属性
用户属性可以大致分为两类:
依托于产品的属性,也就是这个属性只是针对当前的产品或者平台而定义,e.g. 用户的角色,会员层级,是否开通或使用某产品服务;独立于产品的属性,用户作为自然人具有的属性,e.g. 性别、年龄、所在地、职业、收入等;
依托于产品的属性,用户在产品中的
角色(role) ,e.g. 授课平台上的讲师、学生;打车平台上的司机、乘客;电商平台上的卖家、卖家;外卖平台上的商铺、订餐用户、送餐员; 状态(status) ,一般是从初始(默认)状态发生变化,状态相对稳定且有些条件下不可逆,比如对特定行为的标记,e.g.是否付费、是否购买了某服务、是否使用了某功能、是否开通会员等; 类型(type) ,e.g. 登陆设备类型、操作系统类型、登陆账号类型、会员类型等; 标记(stamp) ,e.g. 注册标记(日期、来源的渠道、活动等),“首次”标记(首单日期、金额),“上次”标记,“最”大(小)标记等;
独立于产品的属性,这些用户属性不以产品的不同而转移;
作为“自然”人,具有种族、性别、年龄、婚育、所在地等特征; 作为“社会”人,则和用户在社会生活中扮演的角色有关,e.g.教育(专业、学历等)、职业(行业、职位、收入、工作年限等)、家庭(人口、资产、住房等)、兴趣爱好等;
用户行为
对于用户的行为,需要关注如下方面:
有业务价值的行为,包括有直接价值(带来收入)的行为(页面浏览、付费交易等),也包括有潜在价值的行为,e.g. 注册、登陆、浏览、发表、点赞、评论、转发等,作为“辅助”,这些行为不一定能直接带来收入,但是可能拼成“藏宝图”,通过对这些行为的分析能发现潜在价值高、成长空间大的用户。另外,需要注意的是,不同的业务形态,关注的用户行为是有较大差异的。 用户行为的质量,比如那些行为指标数值越大越好(e.g.页面访问深度、停留时长、转化率等),或者反之越小越好的(e.g.页面跳出、访问时间间隔),此外,在某些业务场景下,用户有较好的行为周期也是行为质量高的表现,e.g.每天访问app,每隔一段时间就到平台上来买米面粮油等; 用户行为的偏好,这里是指业务上的行为,用户可以在产品定义的范围内执行的行为可以看做一个集合,每个特定的行为相当于其中的元素,不同用户的行为偏好会有差异e.g. 读到好文章,有的用户倾向“点赞”,有的用户则是“收藏”或“转发”; 行为对象的偏好,“行为对象”就是用户行为的指向物,比如购买的商品(包括商品的品类、品牌、价格、优惠等)、浏览的内容(包括类型、风格、作者、排版等),e.g. 我买书的时候基本只看当当或京东,日用百货就去京东,购买服饰类就去唯品会;e.g. 大家都在同一平台上看视频,有的用户主要看电影、有的是看动漫,其他一些用户则是来追电视剧; 用户行为的变化,e.g. 曾经买买买,如今则只逛不买,用户行为的变化和业务指标的波动高度关联,指标波动归因是数据分析任务中的常见场景,所以做好对用户行为变化的监控,是非常基础的工作。用户行为的变化分可以按空间和时间上去划分: 空间上关注具体的用户群以及业务场景; 时间上则关注用户群体行为变化的时间点,看是“临时突变”,还是“持续变化”; 行为背后的认知,可能除了用户调研、产品反馈、客服投诉这3类渠道外,用户很难亲口说出自己的需求,大部分时候需要从用户的行为数据中去揭示更深层的用户认知。e.g. 品牌忠诚、价格敏感、容易投诉、冲动消费。
用户价值
用户价值的高低和用户属性以及用户行为都有高度的关联,所以对用户的价值的评估可以看做是多个维度的综合指标。
用户价值的考量基础是这个用户能为平台带来多大收益(潜在收益),换句话说我们能通过这个用户获得多少收入。
对于用户带来的收入而言包含以下含义:
对于每个用户而言,从对方进入平台到流失这个过程获得收入的期望值是多少,这个值也就是用户生命周期价值(Customer Lifetime Value, CLV); 考量用户价值时,除了其潜在的收入有多少外,还会考虑获得收入的可能性,也就是“从哪些用户那里更容易获得收入(或者获得收入的概率更高)”; 通过用户获得的收入不一定是用户付费,要看具体的商业模式,对于很大一部分产品而言,广告才是收入的大头,除了向用户兜售商品、服务或功能外,用户的注意力也可以被卖钱;
生命周期
用户的生命周期是理论上的一个从新客到老客再到过客的完整流程。
用户生命周期的划分需要注意的是:
处于不同生命周期在用户行为上会有什么表现? 生命周期在不同的用户身上表现是有差异的,有的用户在平台待的时间可能很长,有的就比较短,有的用户并没有经历完整的生命周期就流失掉了。
其他补充
如何选择维度?
首先要看你要解决的问题是什么?或者你的业务目标是什么? 选择的维度要和业务目标高度关联; 维度不一定要很多,达到一定的效度就可以,太复杂反而不利于操作;
分群的注意事项
厘清分群的目的 可以是简单地对用户特征进行描述,以便于了解用户; 可以是对用户的价值判断然后分群排序(分层),便于资源的倾斜和分配,e.g.有人吐槽“RFM模型”没啥价值,这个模型用来确定群体优先级还是很好用的,此外,如果跨时间周期对比RFM矩阵中的变化,也可以检查业务是否健康; 也可以是基于产品、运营活动的前提,要对不同的用户群进行不同的操作,那么分群应该能指明操作的方向,比如促销选择那些人群?如何配置优惠力度?选择哪些商品?等等 既然是分组,就要保证组间的差异足够显著,这个涉及到分组的规则,要看具体业务场景。