
OpenCV4+OpenVINO实现图像的超像素
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:opencv学
传统方式的图像超像素常见的方式就是基于立方插值跟金字塔重建。OpenCV中对这两种方式均有实现,低像素图像在纹理细节方面很难恢复,从低像素图像到高像素图像是典型的一对多映射,如果找到一种好的映射关系可以尽可能多的恢复或者保留图像纹理细节是图像超像素重建的难点之一,传统方式多数都是基于可推导的模型实现。而基于深度学习的超像素重新方式过程未知但是结果优于传统方式。在深度学习方式的超像素重建中,对低像素图像采样大感受野来获取更多的纹理特征信息。OpenVINO中提供的单张图像超像素网络参考了下面这篇文章
https://arxiv.org/pdf/1807.06779.pdf该网络模型主要分为两个部分
特征重建网络,实现从低分辨率到高分辨率的像素重建
注意力生成网络,主要实现图像中高频信息的修复
通过两个网络的的输出相乘,还可以得到高分辨率图像的残差。特征重建网络主要包括三个部分。卷积层实现特征提取,卷积层采样大感受野来得到更多纹理细节;多个DenseRes 叠加模块,级联DenseRes可以让网络更深,效果更好;一个亚像素卷积层作为上采样模块。注意力生成网络部分,用来恢复小的纹理细节,如图像的边缘与形状,网络可以准确定位到细节特征,然后进行相对提升,注意力特征网络设计受到UNet网络架构的启发。完整的模型结构如下:
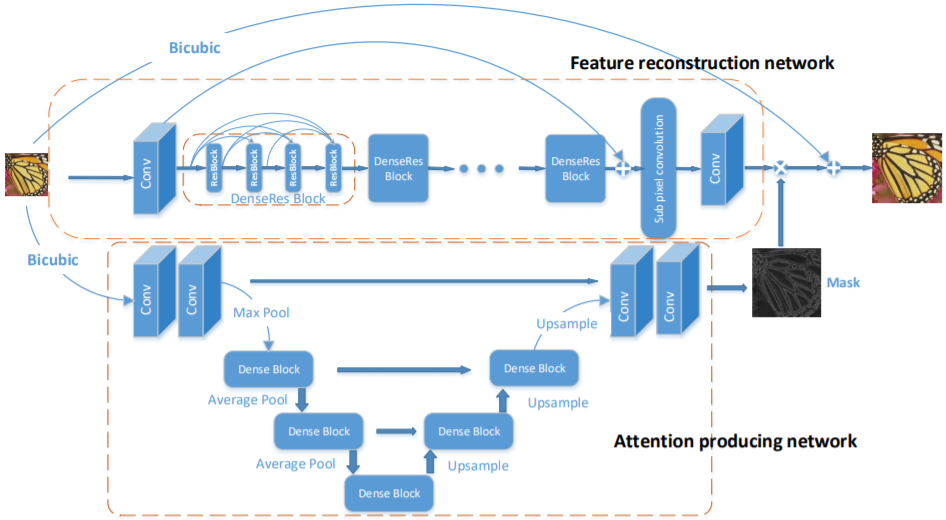
一个更简介的网络结构如下:
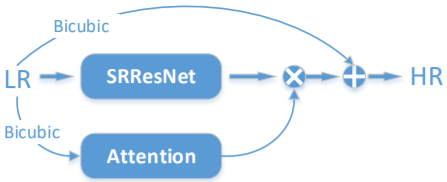
其中LR表示低分辨率图像、HR表示高分辨率图像,Bicubic表示双立方插值上采样。
OpenVINO提供的模型是在这个模型基础上进行简化,计算量更低,速度更快。从上面的模型结构知道,模型有两个输入部分,分别是输入的低分辨率图像与双立方上采样的图像
LR的输入:[1x3x270x480]双立方采样:[1x3x1080x1920]三通道顺序是:BGR
模型的输出
输出层是一个blob对象,格式为[1x3x1080x1920]首先需要加载网络模型,获取可执行网络,然后设置输入与输出的数据格式与数据精度,这部分的代码如下:
// 加载检测模型
CNNNetReader network_reader;
network_reader.ReadNetwork(model_xml);
network_reader.ReadWeights(model_bin);
// 请求网络输入与输出信息
auto network = network_reader.getNetwork();
InferenceEngine::InputsDataMap input_info(network.getInputsInfo());
InferenceEngine::OutputsDataMap output_info(network.getOutputsInfo());
// 设置输入格式
for (auto &item : input_info) {
auto input_data = item.second;
input_data->setPrecision(Precision::U8);
input_data->setLayout(Layout::NCHW);
input_data->getPreProcess().setResizeAlgorithm(RESIZE_BILINEAR);
input_data->getPreProcess().setColorFormat(ColorFormat::BGR);
}
printf("get it \n");
// 设置输出格式
for (auto &item : output_info) {
auto output_data = item.second;
output_data->setPrecision(Precision::FP32);
}
// 创建可执行网络对象
auto executable_network = ie.LoadNetwork(network, "CPU");
// 请求推断图
auto infer_request = executable_network.CreateInferRequest();代码演示步骤中有两个输入,对输入的设置可以使用下面的代码
/** Iterating over all input blobs **/
for (auto & item : input_info) {
auto input_name = item.first;
printf("input_name : %s \n", input_name.c_str());
/** Getting input blob **/
auto input = infer_request.GetBlob(input_name);
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h*w;
Mat blob_image;
resize(src, blob_image, Size(w, h));
printf("input channel : %d, height : %d, width : %d \n", num_channels, h, w);
// NCHW
unsigned char* data = static_cast<unsigned char*>(input->buffer());
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
for (size_t ch = 0; ch < num_channels; ch++) {
data[image_size*ch + row*w + col] = blob_image.at<Vec3b>(row, col)[ch];
}
}
}
}最后执行推理,完成对输出的解析,在解析输出的时候其实输的是[NCHW] = [1x3x1080x1920]的浮点数矩阵,需要转换为Mat类型为[HWC] =[1080x1920x3],采用的是循环方式,是不是有更好的数据处理方法可以转换这个,值得研究。解析部分的代码如下
// 执行预测
infer_request.Infer();
// 处理输出结果
for (auto &item : output_info) {
auto output_name = item.first;
// 获取输出数据
auto output = infer_request.GetBlob(output_name);
float* buff = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());
const int c = output->getTensorDesc().getDims()[1];
const int h = output->getTensorDesc().getDims()[2];
const int w = output->getTensorDesc().getDims()[3];
// 获得输出的超像素图像
Mat result = Mat::zeros(Size(w, h), CV_32FC3);
for (int ch = 0; ch < c; ch++) {
for (int row = 0; row < h; row++) {
for (int col = 0; col < w; col++) {
result.at<Vec3f>(row, col)[ch] = buff[ch*w*h+ row*w + col];
}
}
}
printf("channel : %d, height : %d, width : %d \n", c, h, w);
normalize(result, result, 0, 255.0, NORM_MINMAX);
result.convertTo(result, CV_8U);
imshow("High-Resolution Demo", result);
imwrite("D:/result.png", result);
}
测试结果分别如下:(原图)

超分辨输出:(1920x1080)

总结一下:也许模型被简化的太厉害了,速度是很快了,单身效果感觉比双立方好那么一点点而已!所谓鱼跟熊掌不可兼得!
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~