单像素成像图像智能处理算法
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达


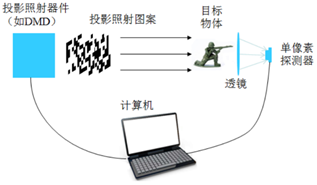


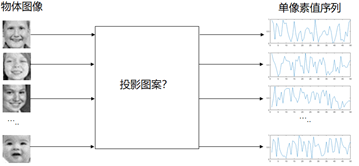

焦述铭,深圳大学纳米光子学研究中心副研究员,香港城市大学博士毕业。主要从事单像素成像,全息成像及显示,图像处理等方面研究。以第一作者发表期刊论文20余篇,曾入选Hong Kong PhD Fellowship Scheme和广东省“珠江人才计划”博士后资助项目。
本文仅做学术分享,如有侵权,请联系删文。
评论
 下载APP
下载APP点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
焦述铭,深圳大学纳米光子学研究中心副研究员,香港城市大学博士毕业。主要从事单像素成像,全息成像及显示,图像处理等方面研究。以第一作者发表期刊论文20余篇,曾入选Hong Kong PhD Fellowship Scheme和广东省“珠江人才计划”博士后资助项目。
本文仅做学术分享,如有侵权,请联系删文。