
冠军方案解读:1秒钟打造智能化视频内容生产利器

极市导读
本文精选了Media AI 阿里巴巴文娱算法挑战赛中优酷人工智能算法团队提出的冠军方案,他们以 STM(Video Object Segmentation using Space-Time Memory Networks)为基础,进行了彻底的模型复现和以及算法改进。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
视频目标分割是目前视频算法领域的前沿话题,越来越多的应用在了各个行业场景里,尤其在智能化视频生产中,算法的加持让视频内容生产的效率大大提升,并且由此衍生了众多自动化工具和解决方案。本次由英特尔与阿里云联合举办、与优酷战略合作的“新内容 新交互“全球视频云创新挑战赛算法赛道,也将目光聚焦于这一个领域。大赛自开赛以来,已经吸引了 2000 多支队伍参赛,汇聚了全球算法精英。
视频场景内容丰富多样:要求算法在复杂背景干扰下正确发掘场景显著主角;
复杂衣着 / 手持 / 附属物:要求算法充分描述目标丰富和复杂的外观语义;
目标人物快速剧烈动作:要求算法解决运动模糊、剧烈形变带来的误分割、漏分割。
冠军方案算法详解
在初赛阶段,优酷人工智能部算法团队以 STM(Video Object Segmentation using Space-Time Memory Networks)为基础,进行了彻底的模型复现和以及算法改进。在复赛阶段,以初赛半监督模型为骨干,配合以目标检测、显著性判别、关键帧选择等模块,实现高精度无监督视频分割链路。
1.半监督视频人物分割
半监督 VOS 的任务目标是在给定第一帧物体掩码的前提下,将该物体在后续帧中连续分割出来。
1.1基本框架
提出 Spatial Constrained Memory Reader 以解决 STM 空间连续性不足问题。
首先 STM 在像素匹配时是基于外观的匹配,没有考虑物体在相邻两帧之间空间上的连续性。换言之,STM 会寻找与前面帧中外观相似的物体,但对该物体出现在何位置不敏感。因此,当一帧中出现多个外观相似物体时,STM 的分割结果就有可能产生错误。
针对这个问题,DAVIS2020 半监督第一名方案的解决方法是将前一帧的物体 mask 结合到 encode 之后的 feature 中,降低离前一帧物体位置较远像素的权重(如图 1 所示)。实际尝试后发现增益不大。我们认为原因在于训练过程中给与模型过强的位置先验,导致模型分割过分依赖于前一帧的物体位置信息,约束了 non-local 的长距离匹配能力。一旦出现前一帧物体被遮挡,或者前一帧物体分割错误的情况,整段视频的分割结果将出现不稳定性偏移。

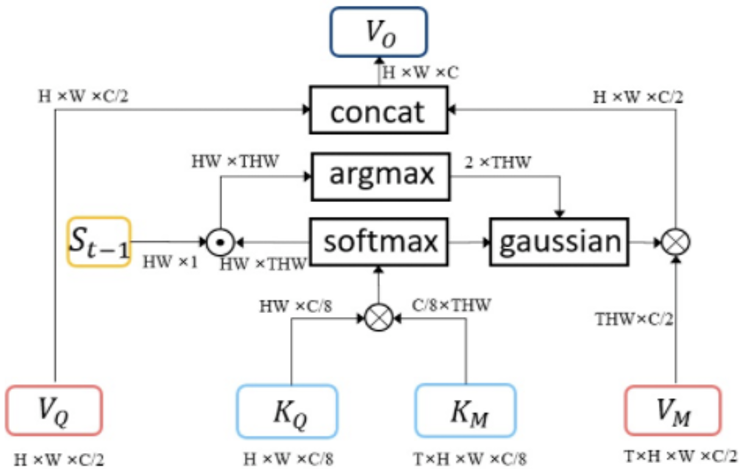
DAVIS2020 半监督第三名方案对此的解决方案是 kernelized memory reader(如图 2 所示),这种方法能保证 memory 中的点会匹配到 query 中最相似的一个区域,可以避免出现一对多匹配的问题。但是不能保证空间上的连续,容易出现不可逆的误差累积。
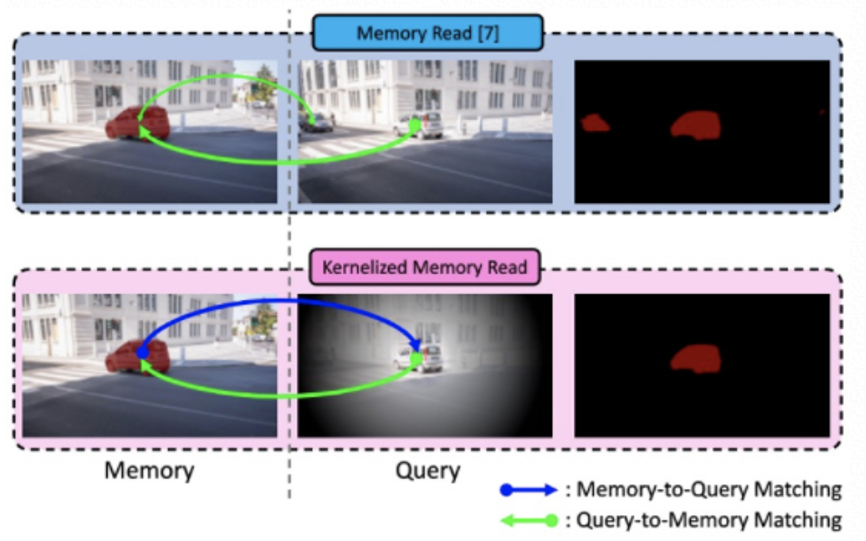
综合考虑上述两种方法,我们提出了一种既能考虑前一帧物体位置信息,又不影响原始匹配训练过程的方法。如图 3 所示,利用前一帧的物体 mask 生成位置大小相关的高斯核,通过这个高斯核来修正 memory 中像素的最优匹配位置。之后流程和图 2 相似,利用每个像素的最优匹配位置对原始匹配进行修正。如此一来,既没有影响训练过程,导致 non-local 部分匹配能力降低,又引入了 spatial prior,保证了物体 mask 的空间连续性。
增加 ASPP & HRNet post-refinement 以解决 STM 解码器对多尺度目标分割精细度较差问题。
通过 ASPP 增加多尺度信息的捕获能力,利用 HRnet 对 STM 的初始分割结果进行 refine,优化物体细节的分割效果。
1.2训练策略
在比赛中采用了两阶段训练的方法。第一个阶段,采用 MS-COCO 静态图像库成视频序列进行预训练。第二个阶段,将公开数据库(DAVIS,Youtube-vos)和比赛训练集进行合并训练,来保证有足够的数据量。具体训练细节如下:
Crop 相邻 3 帧图像 patch 进行训练,尽可能增加 augmentation。crop 时需要注意一定要保证在第 2 和第 3 帧出现的物体都在第一帧出现了,否则应该过滤;
将 DAVIS,Youtube-vos 和比赛训练集以一定比例融合效果最好;
训练过程指标波动较大,采用 poly 学习率策略可缓解;
训练比较吃显存,batch size 比较小的话要 fix 所有的 bn 层。
1.3其他
Backbone:更换 resnest101;
测试策略:使用 Multi-scale/flip inference。
1.4结果
优酷算法团队的模型,在测试集上取得了 95.5 的成绩,相比原始 STM 提高将近 5 个点。
2.无监督视频人物分割
无监督 VOS 的任务目标是在不给定任何标注信息的前提下,自主发掘前景目标并进行连续的分割。无监督 VOS 方法链路较为复杂,通常不是由单一模型解决,其中涉及到目标检测、数据关联、语义分割、实例分割等模块。
2.1算法框架
我们复赛所采用的算法流程具体分为如下四步:
a. 逐帧做实例分割
采用 DetectoRS 作为检测器,为保证泛化能力,没有在比赛训练集上 finetune 模型,而是直接使用在 MS COCO 数据集进行训练。此阶段只保留 person 类别。阈值设为 0.1,目的是尽可能多地保留 proposal。
b. 对实例分割的 mask 进行后处理
如下左图所示,现有 instance segmentation 的方法产生的 mask 分辨率低,边缘粗糙。我们采用语义分割模型对 DetectoRS 产生的结果进行 refine(image+mask ->HRnet -> refined mask), 结果如下图。可以看出掩码图中的物体边缘以及细节都有了明显的改善。

c.帧间进行数据关联,得到初步结果
利用 STM 将 t-1 帧的 mask warp 到 t 帧,这样就可以利用 warp 后的 mask 和第 t 帧的分割结果进行匹配。通过这个过程,补偿了运动等问题产生的影响,稳定性更高。具体的,对于首帧物体,我们保留置信度大于 0.8 的 proposal。对第 t-1 帧和第 t 帧做数据关联时,首先利用 STM 将第 t-1 帧的结果 warp 到第 t 帧。然后用匈牙利算法对 warp 后的 mask 和第 t 帧由 DetectRS 生成的 proposal 进行二部图匹配。
d.筛选分割结果较好的帧作为 key frames 进行迭代优化
经上述数据关联以后,我们已经得到了初步的无监督 VOS 结果,其中每帧的 mask 是由 DetectRS 生成,id 是由数据关联决定。但是这个结果存在很多问题,还可以进一步优化。比如说视频开始处出现的漏检无法被补上。如下图所示,左侧的人在视频开始处不易被检测,直到第 10 帧才被检测出来。另外,视频中人体交叠严重处分割质量要远低于人体距离较大处。

因此,我们可以根据物体数量,bbox 的交叠程度等信息筛选出一些可能分割较好的帧作为下一轮优化的 reference。具体的,我们可以利用筛选出来的 key frames 作为初始 memory,用 STM 进行双向预测。首先双向预测可以解决视频开始处的漏检,其次 STM 对于遮挡等问题的处理也要好过单帧的实例分割。经实验验证,每迭代一次 STM 双向预测,指标都有小幅度提升。

视频目标(人物)分割(Video Object Segmentation,简称为 VOS)算法是业界公认的技术重点难点,同时又有着最为广泛的落地场景和应用需求。相信参与本届 “新内容 新交互 “全球视频云创新挑战赛算法赛道的选手,将以视频目标分割为起点,利用计算机视觉算法领域的诸多技术,为行业和大众打造更加智能化、便捷化、趣味化的视频服务。
推荐阅读
2021-01-17

2021-01-12

2020-12-25

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
