
火爆全球的《鱿鱼游戏》,尝试用Python做一波分析
大家好,欢迎来到 Crossin的编程教室 !
之前趁着国庆长假,把最近很火的一个韩剧《鱿鱼游戏》刷了下,这部剧整体剧情来说还是非常不错的,很值得一看。
作为一个技术博主,当然不能在这儿介绍这部剧的影评,毕竟自己在这方面不是专业的,也不擅长啊。
本文呢,主要是爬取《鱿鱼游戏》在豆瓣上的一些影评,对数据做一些简单的分析,用数据的角度重新审视下这部剧。
技术工具
在正文开始之前,先介绍下本篇文章中用到的技术栈和工具。
本文用到的技术栈和工具如下,归结为四个方面:
语言:Python,Vue,javascript
存储:MongoDB
库:echarts,Pymongo,WordArt...
软件:Photoshop
数据采集
本次数据采集的目标网站为 豆瓣,但自己的账号之前被封,所以只能采集到大概二百来条数据,豆瓣有相应的反爬机制,浏览10页以上的评论需要用户登录才能进行下一步操作。
至于为啥账号被封,是因为之前自己学爬虫时不知道在哪里搞的【豆瓣模拟登录】代码,当时不知道代码有没有问题,愣头青直接用自己的号试了下,谁知道刚试完就被封了,而且还是永久的那种。
在这里也给大家提个醒在以后做爬虫时,模拟登录时尽量用一些测试账号,能不用自己的号就别用。
这次数据采集也比较简单,就是更改图2 中 url 上的 start 参数,以 offset 为 20 的规则作为下一页 url 的拼接:

拿到请求连接之后,用 requests 的 get 请求,再对获取到的 html 数据做个解析,就能获取到我们需要的数据了。采集核心代码贴在下方:
for offset in range(0,220,20):
url = "https://movie.douban.com/subject/34812928/comments?start={}&limit=20&status=P&sort=new_score".format(offset)
res = requests.get(url,headers= headers)
# print(res.text)
soup = BeautifulSoup(res.text,'lxml')
time.sleep(2)
for comment_item in soup.select("#comments > .comment-item"):
try:
data_item = []
avatar = comment_item.select(".avatar a img")[0].get("src")
name = comment_item.select(".comment h3 .comment-info a")[0]
rate = comment_item.select(".comment h3 .comment-info span:nth-child(3)")[0]
date = comment_item.select(".comment h3 .comment-info span:nth-child(4)")[0]
comment = comment_item.select(".comment .comment-content span")[0]
# comment_item.get("div img").ge
data_item.append(avatar)
data_item.append(str(name.string).strip("\t"))
data_item.append(str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"))
data_item.append(str(date.string).replace('\n','').strip('\t'))
data_item.append(str(comment.string).strip("\t").strip("\n"))
data_json ={
'avatar':avatar,
'name': str(name.string).strip("\t"),
'rate': str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"),
'date' : str(date.string).replace('\n','').replace('\t','').strip(' '),
'comment': str(comment.string).strip("\t").strip("\n")
}
if not (collection.find_one({'avatar':avatar})):
print("data _json is {}".format(data_json))
collection.insert_one(data_json)
f.write('\t'.join(data_item))
f.write("\n")
except Exception as e:
print(e)
continue
豆瓣爬取时需要记得加上 cookie 和 User-Agent,否则会有数据为空,
为了后面数据可视化提取方便,本文用的是 Mongodb 作为数据存储,共有211 条数据,主要采集的数据字段为 avatar,name、rate、date、comment,分别表示用户头像、用户名字、星级、日期,评论。结果见图3:
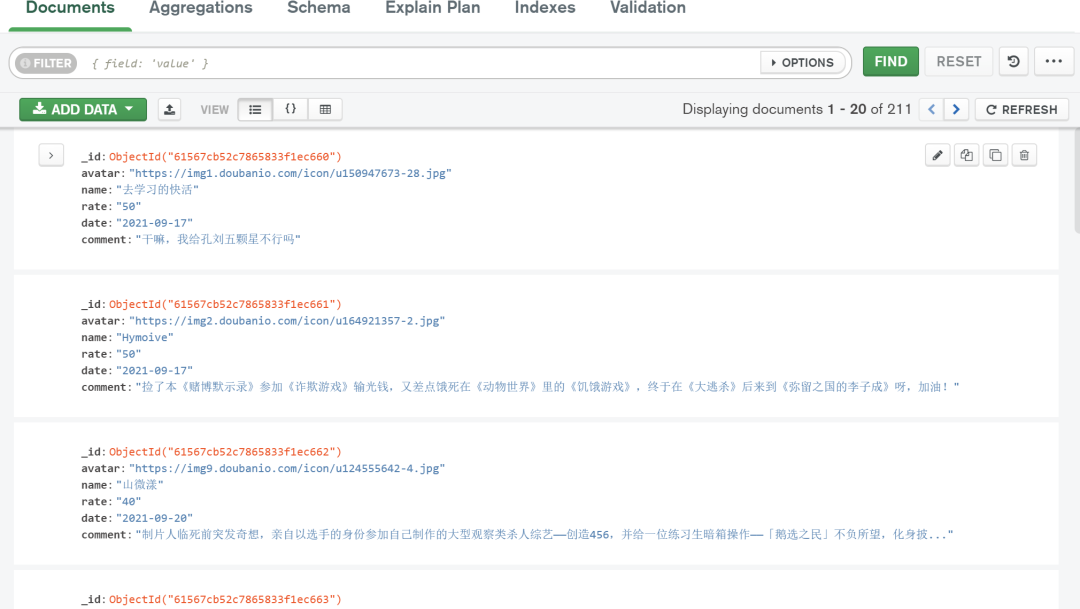
这里如果你不熟悉,MongoDB,用csv文件或其他方式作为数据存储也是可以的。
数据可视化
可视化部分之前打算用 Python + Pyecharts 来实现,但 Python 图表中的交互效果不是很好,索性就直接用原生 Echarts + Vue 组合来实现,而且这样的话,将所有图表放在一个网页中也比较方便。
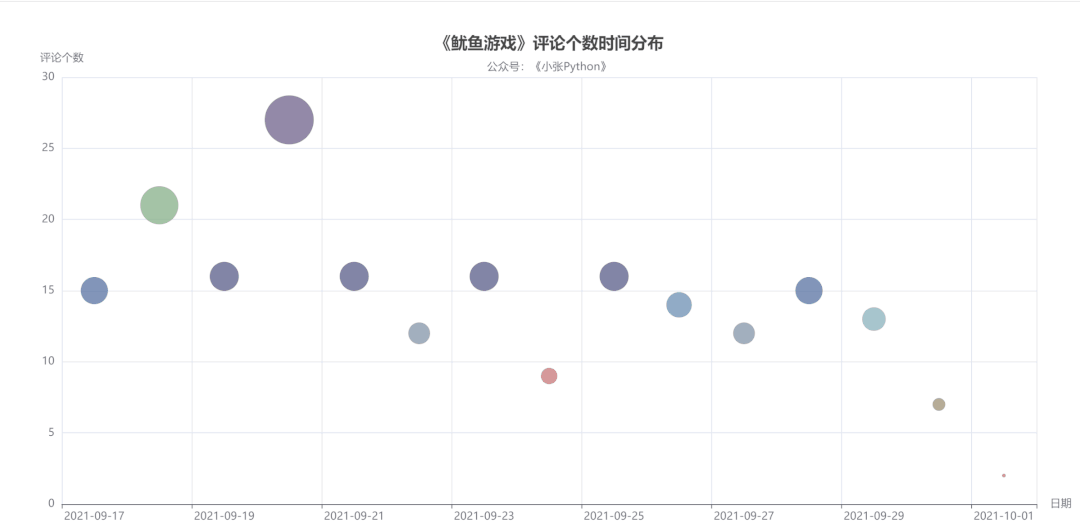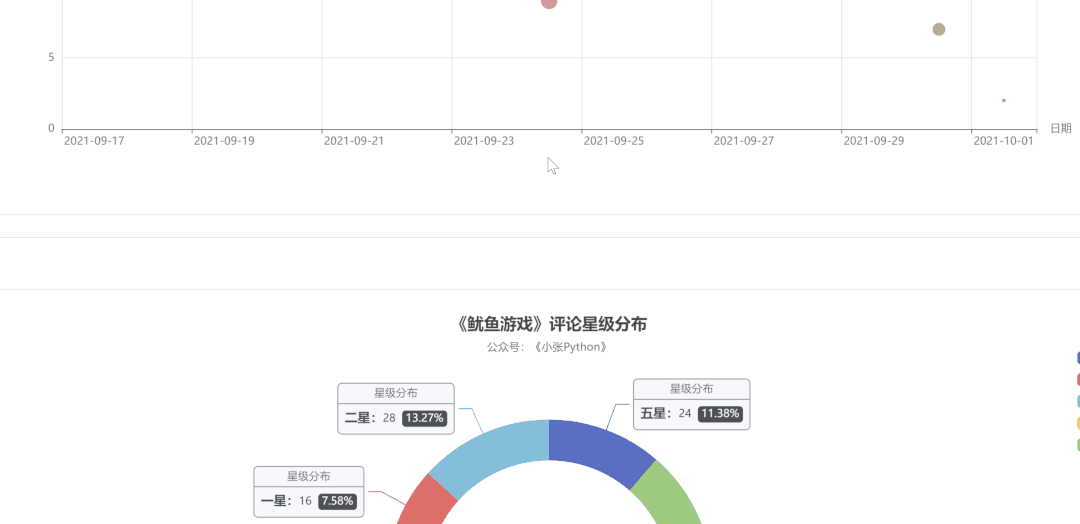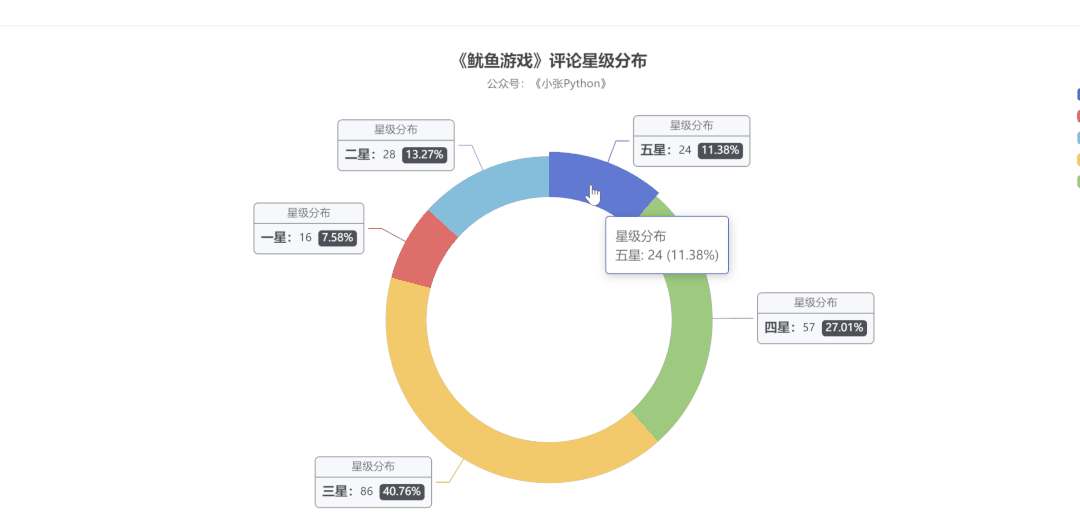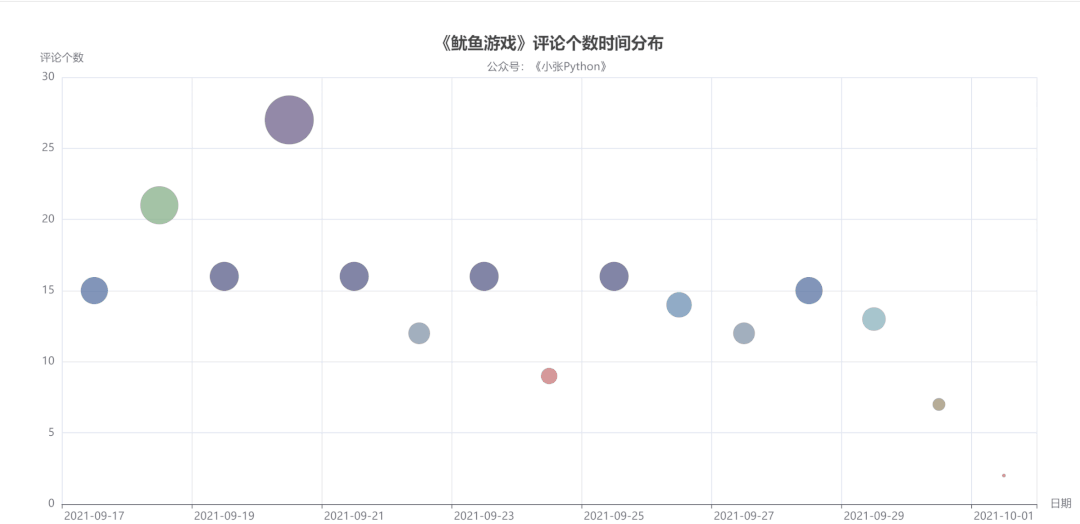
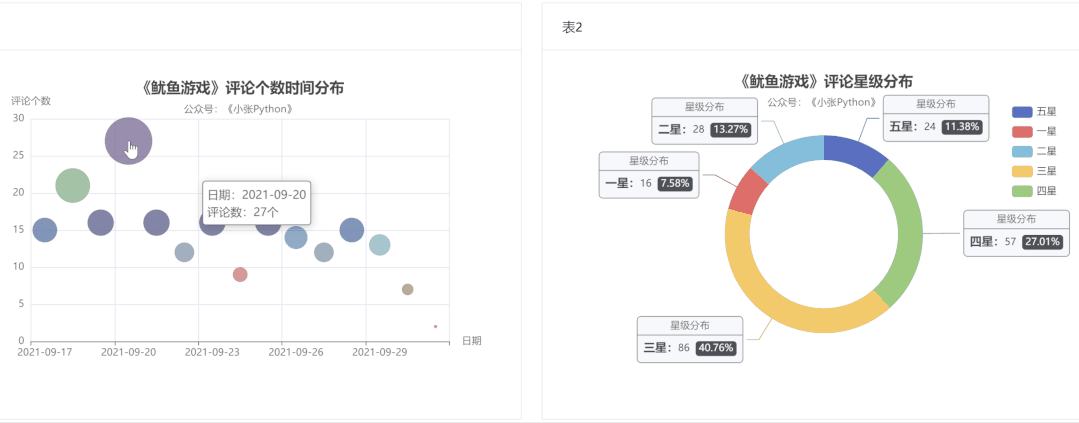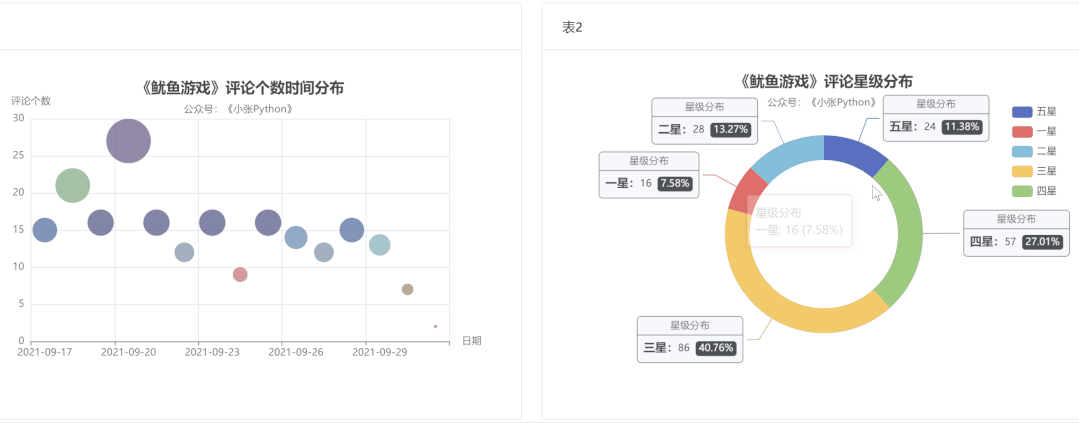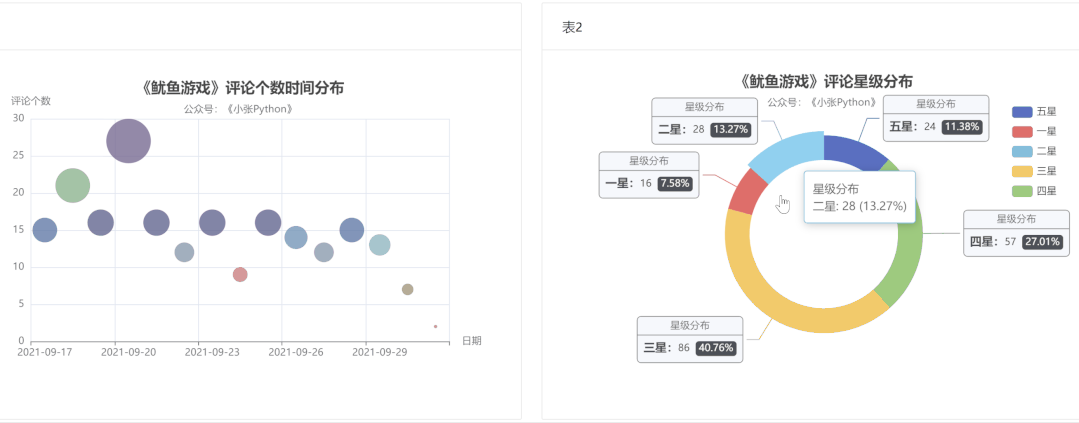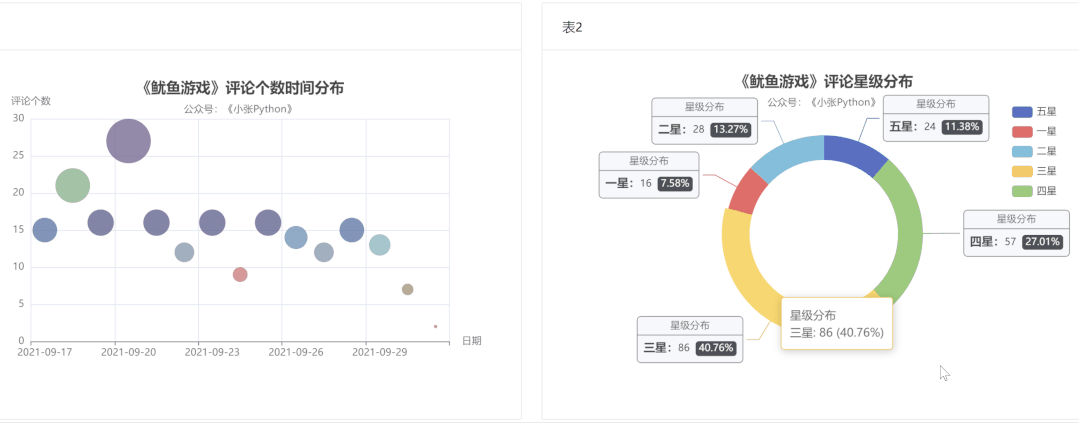
首先是对评论时间与评论数量做了一个图表预览,根据这些数据的评论时间作为一个散点图分布,看一下用户评论主要的时间分布:
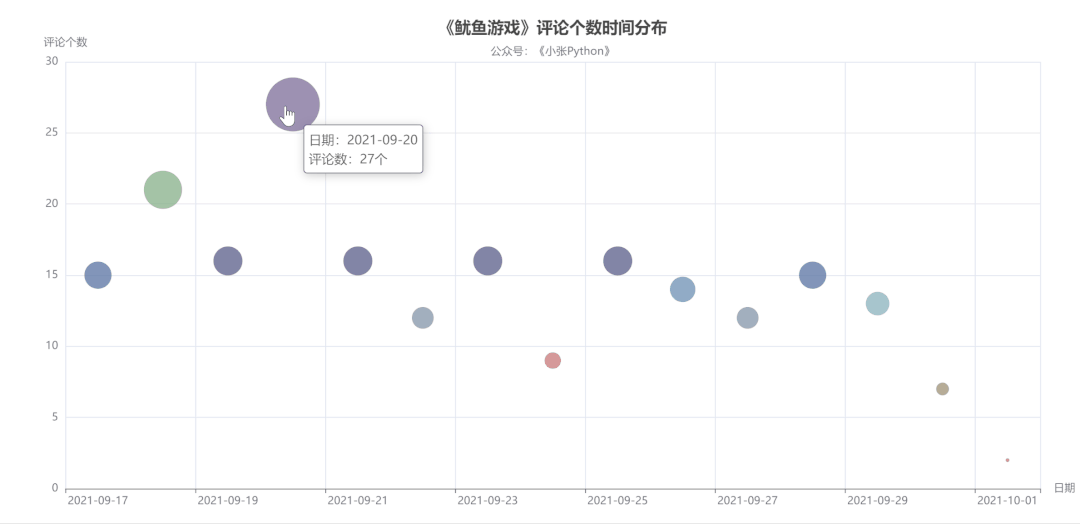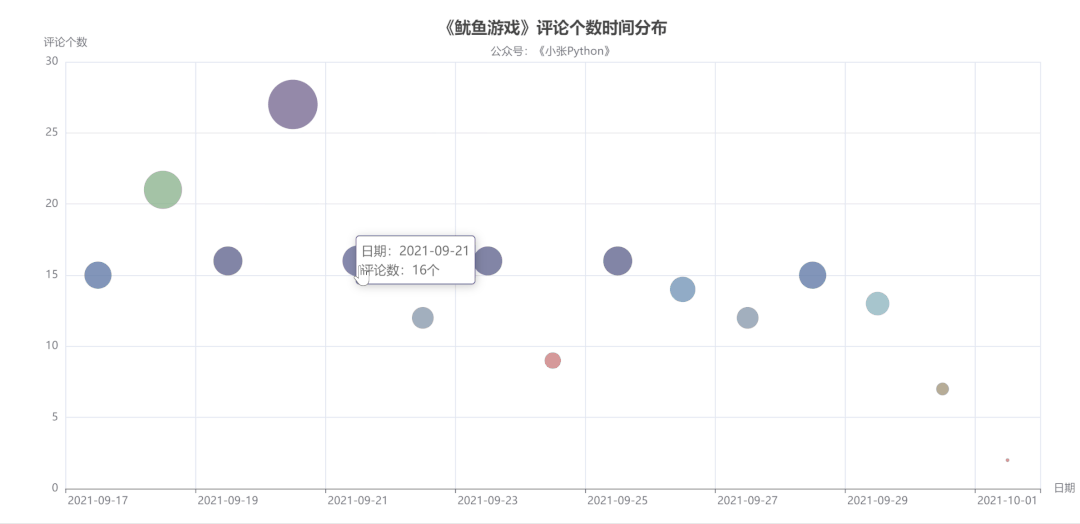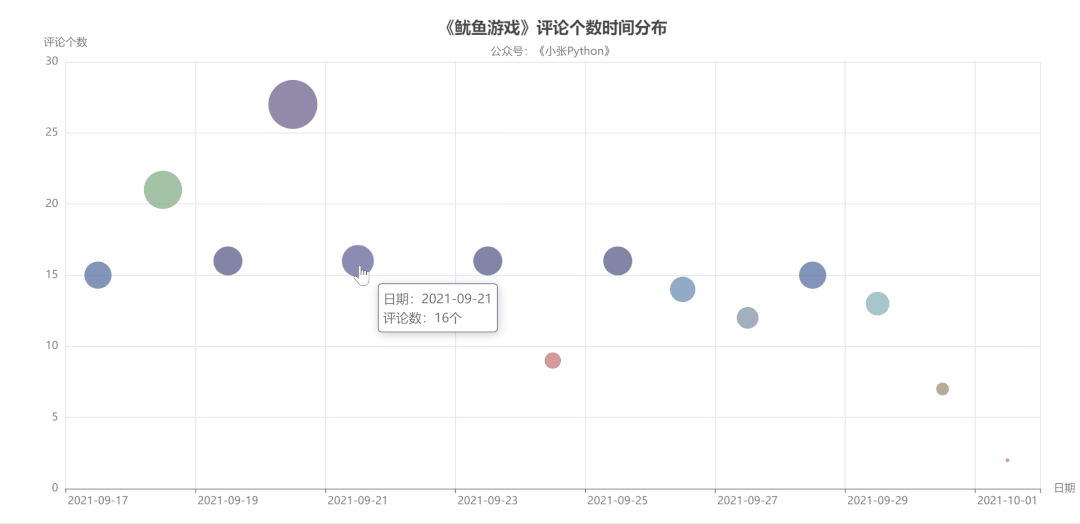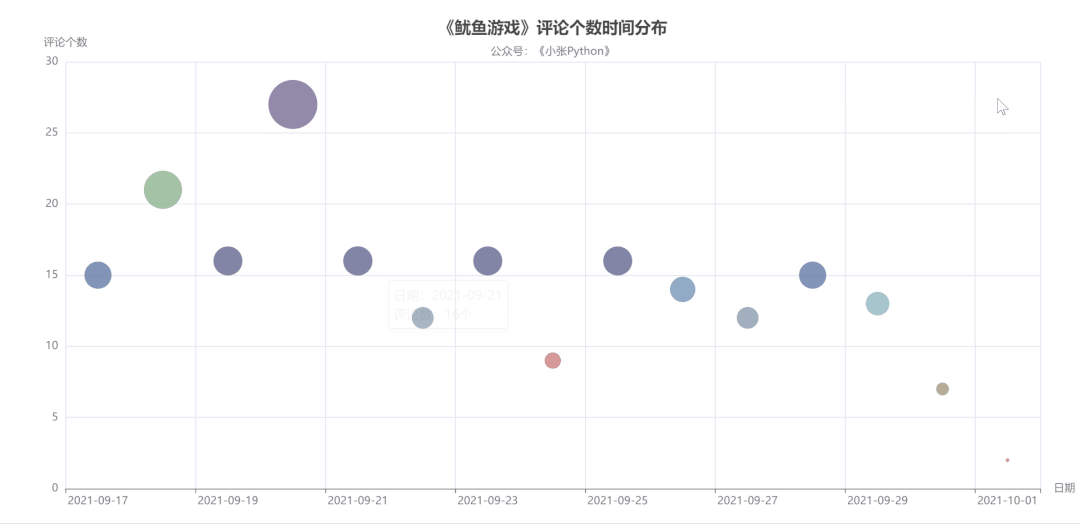
图4中点的大小和颜色代表当天评论数量,而评论数量也可以侧面反应该剧当天的热度。
可以了解到,《鱿鱼游戏》影评从 9 月17 日开始增长,在 20 号数量达到顶峰,21 日回落,在 21日-29日评论数量来回震荡,相差不大。
直到国庆 10月1日最少,猜测可能是一方面是国庆假期大家都出去玩的缘故,另一方面是随着时间推移,这个剧的热度也就降下来了
为了了解大家对《鱿鱼游戏》的评价,我对这二百条数据对这个剧的【评分星级】绘制了一个饼图,最终效果见 图5:
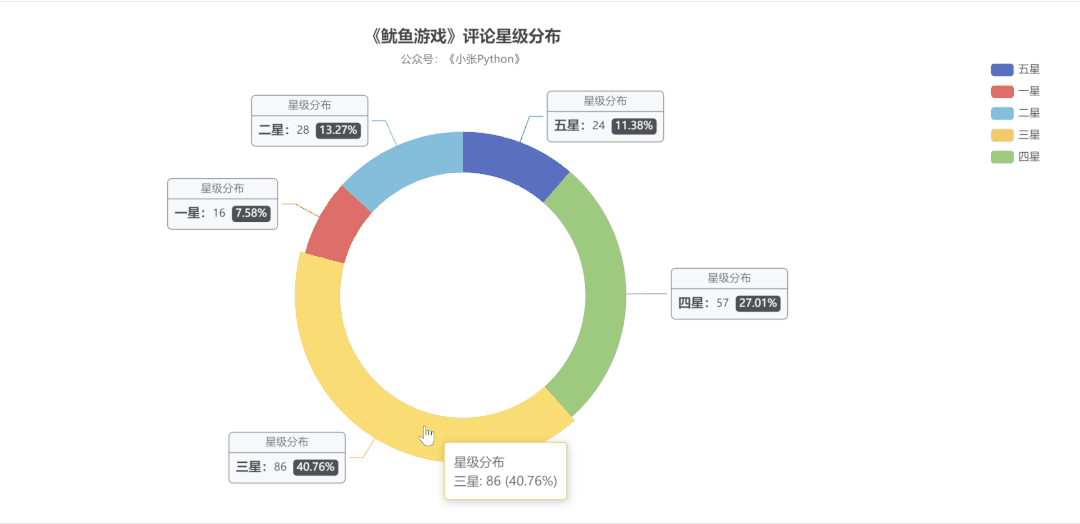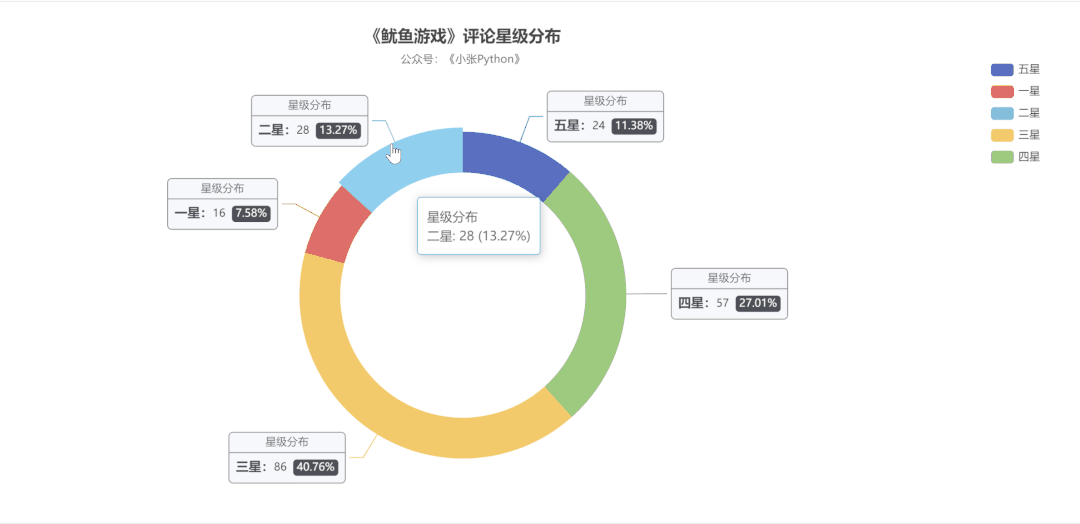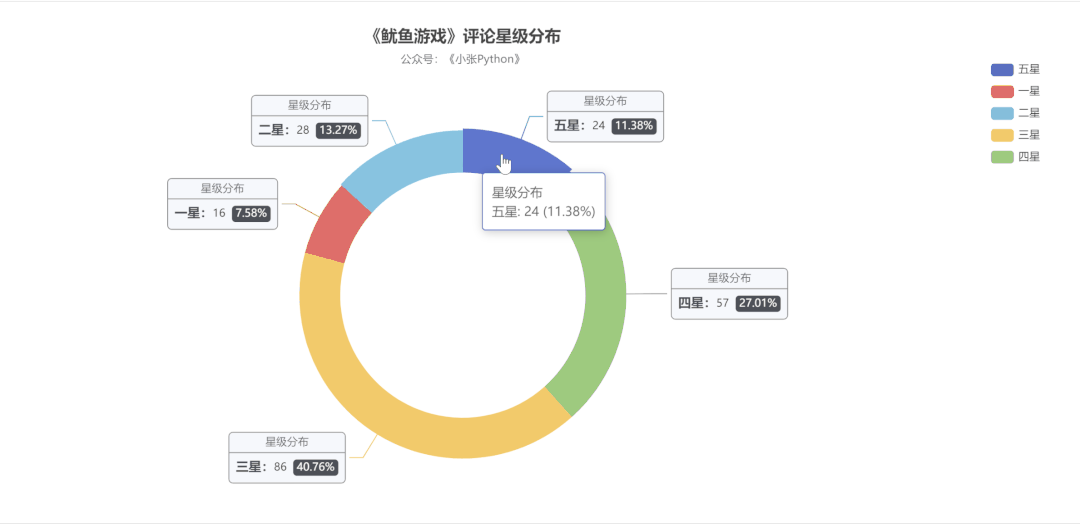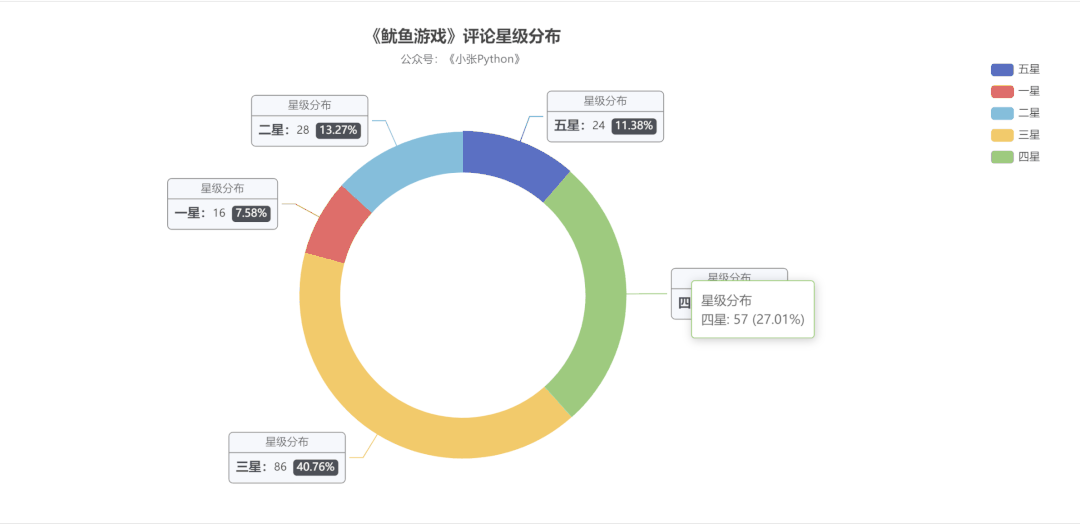
说实话图5 的结果让我有些意外,至少对于我而言这部剧质量说实话还是蛮高的,绘图之前以为【五星】的占比应该是最大的,其次是【四星】,再然后是【三星】。
现在【三星】和【五星】的占比恰恰相反,猜测可能是这部剧的情节比较残忍,会引起人的不适,所以高分占比不高。
为了方便,最后我将上面两张图表放置在一个网页上,效果见图6 和 图7 两种不同布局
垂直布局
水平布局
词云可视化
本次采集的数据信息有限,能分析的数据维度不多,关于数据图表方面的分析基本就到这里了。下面是对采集到的评论做了几张词云图:

从图8来看,去除现实中常用到的还是、就是等口头语,人性 是影评中频率最高的一个词,而这个词确实符合《鱿鱼游戏》这部剧的主题,从第一集开始到结束都是在剖析人性,赌徒们的“贪婪、赌性成瘾”,贵宾们的“弱肉强食”
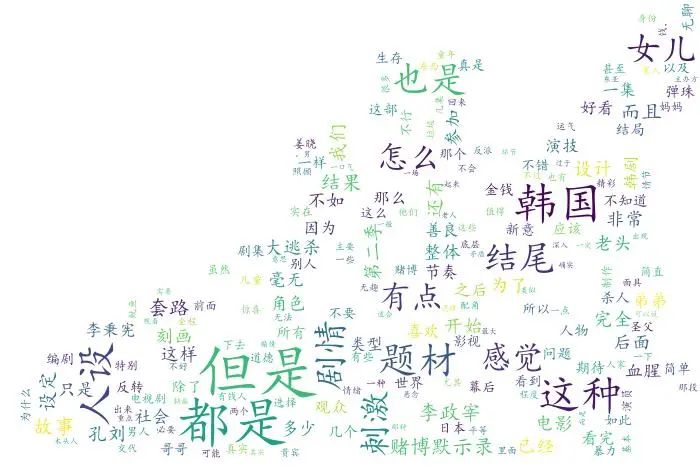
对比上张词云图,图9凸显的信息相对就多了些,例如韩国、人设、刺激、剧情、赌博默示录、题材等都与剧情有关,除了这几个信息之外,李政宰、孔刘、李秉宪 等几个主演也被提到。
最后,以两张照片墙作为文章的结尾:


图10,图11 照片墙的轮廓采用的是剧中的两个人物截图,一个是123木头人 ,另外一个是男一在玩游戏二的一个镜头:

关于照片墙制作方法,可参考旧文中的方法:用Python写一份独特的元宵节祝福
小结
以上就是本篇文章的全部内容了,本文主要是介绍了 Python 在数据采集和可视化方面的一些应用。
获取本文相关代码,请在公众号 Crossin的编程教室 后台回复关键字 鱿鱼
如果文章对你有帮助,欢迎转发/点赞/收藏~
作者:zeroingi
_往期文章推荐_