
目标检测最少训练数据量及类别不平衡的实战研究
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
作者:Changsin Lee
编辑:Happy
链接:Changsin Lee@Medium
导读
本文采用Yolov5进行测试,从实验中得出训练时所需图像数据的最少数据量,数据不平衡问题的解决方式,以及模型更新的最优方法。
达成最大性能增益的最小数据集是多大? 如何处理类别不平衡问题? 采用新数据更新预训练模型的最佳姿势是哪个?

1YOLOv5

2Korean Sidewalk
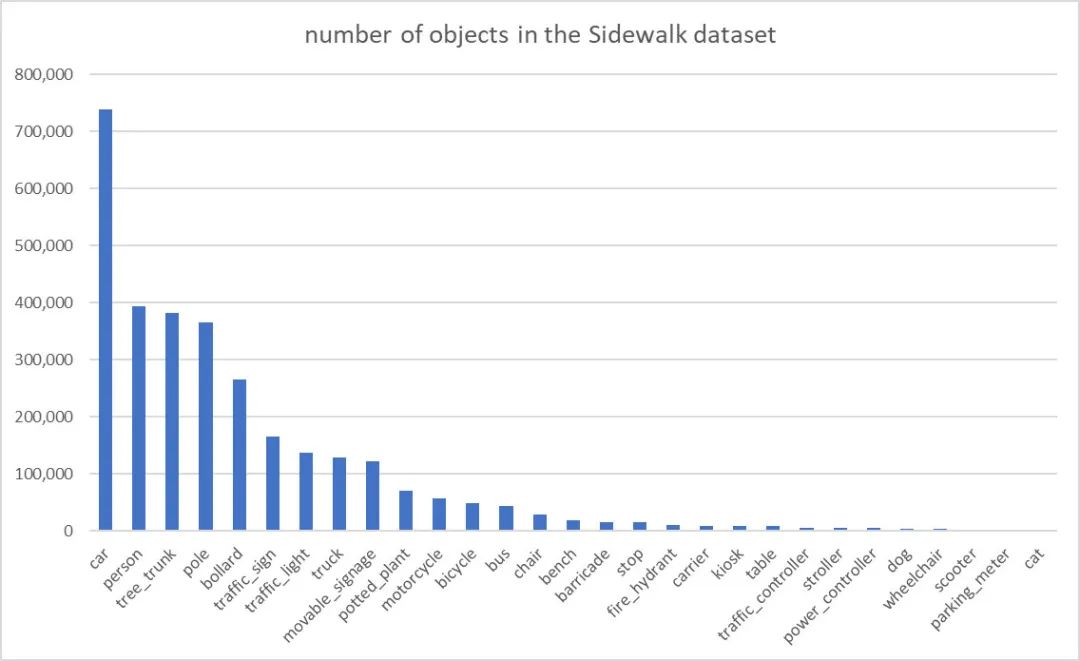
类别不平衡:该数据集存在严重类别不平衡问题,top5占据了70%左右,top15占据了90+%,最常见的类别car在整个数据集中的比例高达24%(可参考上图)。 同一图像存在多实例:在每个图像中,存在多个同类别目标。比如,每个图像中包含3-4个car目标(这个很容易理解,因为数据就是人行道拍摄图像)。 De-identified:人行道图像包含一些私人信息,如人脸、车牌。为保护信息,这个带有私人信息的图像在标注与发布之前进行了特殊处理,可参考下图的车牌。

3Minimum Dataset Size
Top5:car、person、tree、pole、bollard Top10:traffic_sign、traffic_light、truck、moveable_ginage、potted_plant Top15:motor_cycle、bicycle、bus、chair、bench
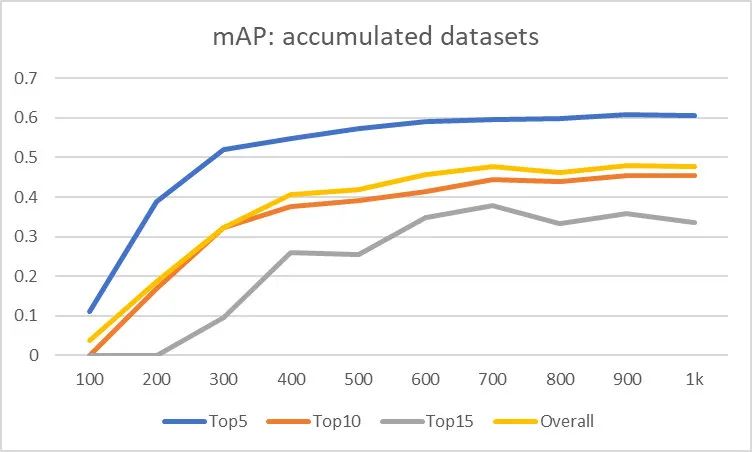
Top5的性能拐点在300左右,这是因为每个图像中有多个实例; 150-500看起来是影响检测性能的一个比较可靠的拐点; Top15的性能同样服从类似的趋势,但因为存在低频目标导致拐点更出现的更晚。
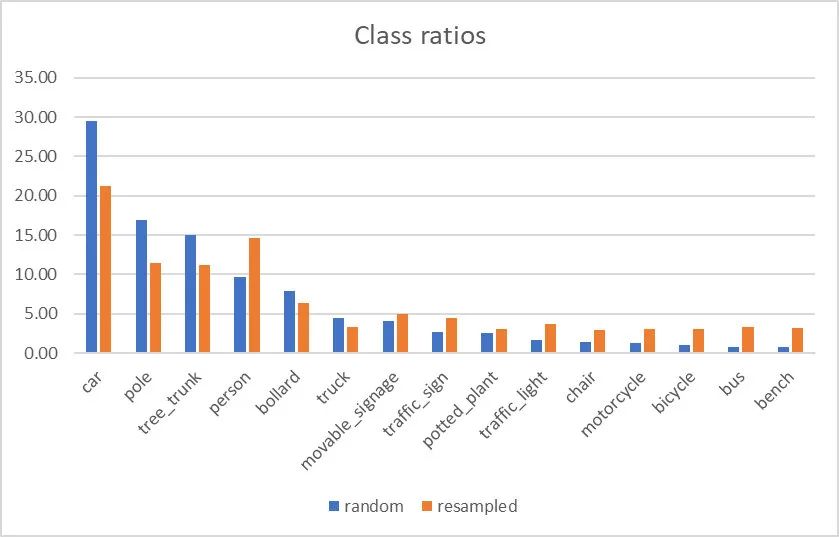
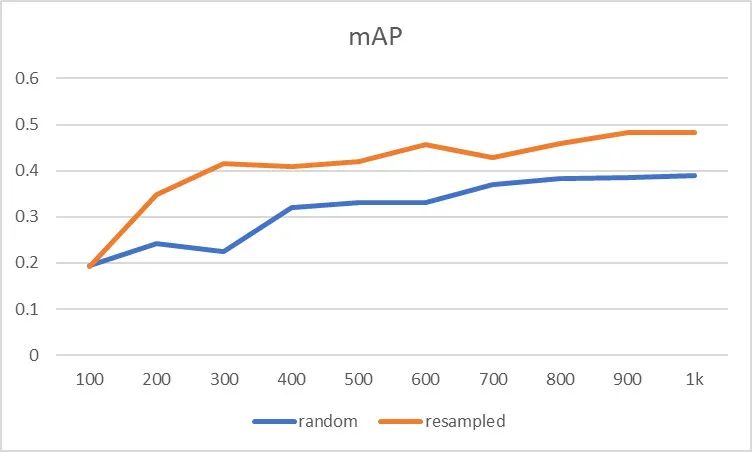
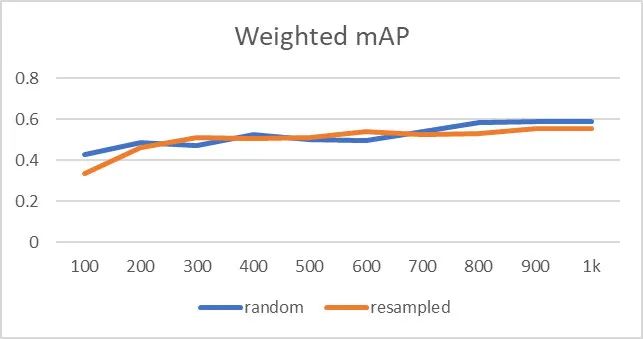
4Countering the Class Imbalance
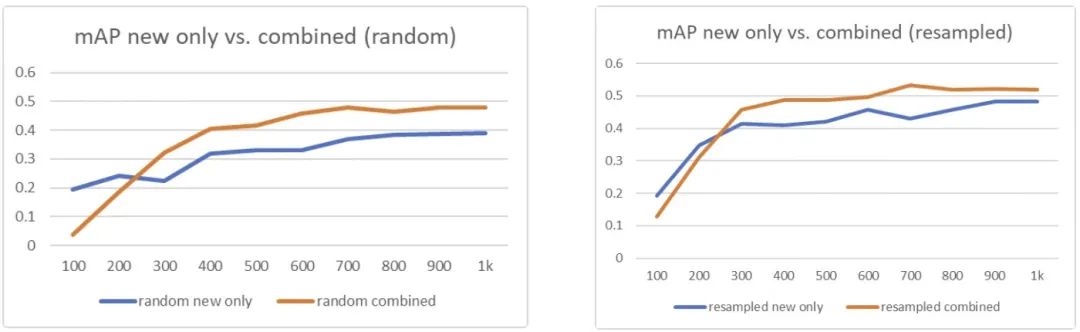
5How to Update the Model
仅使用新数据; 采用新+旧数据组合。
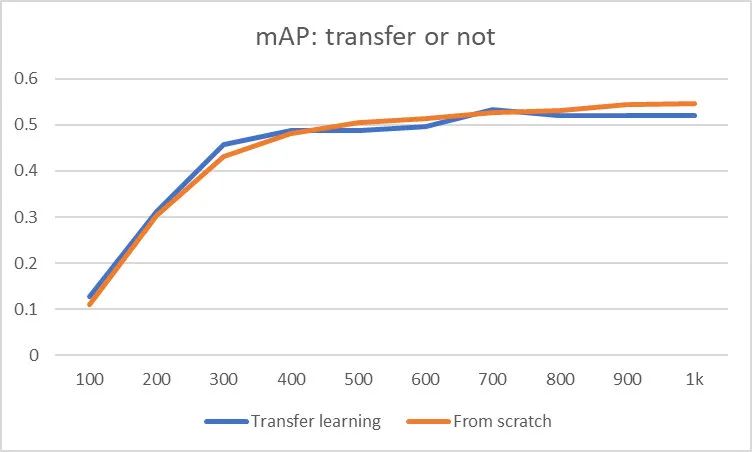
6Conclusion
用于训练的最少图像数据量在150-500; 采用过采样与欠采样补偿类别不平衡问题,但需要对重平衡的数据分布非常谨慎; 模型的更新建议在新+旧组合数据集上进行迁移学习。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、NeRF、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文

评论