
使用Python+OpenCV+FaceNet 实现亚马逊门铃系统上的人脸识别
点击下面卡片关注“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

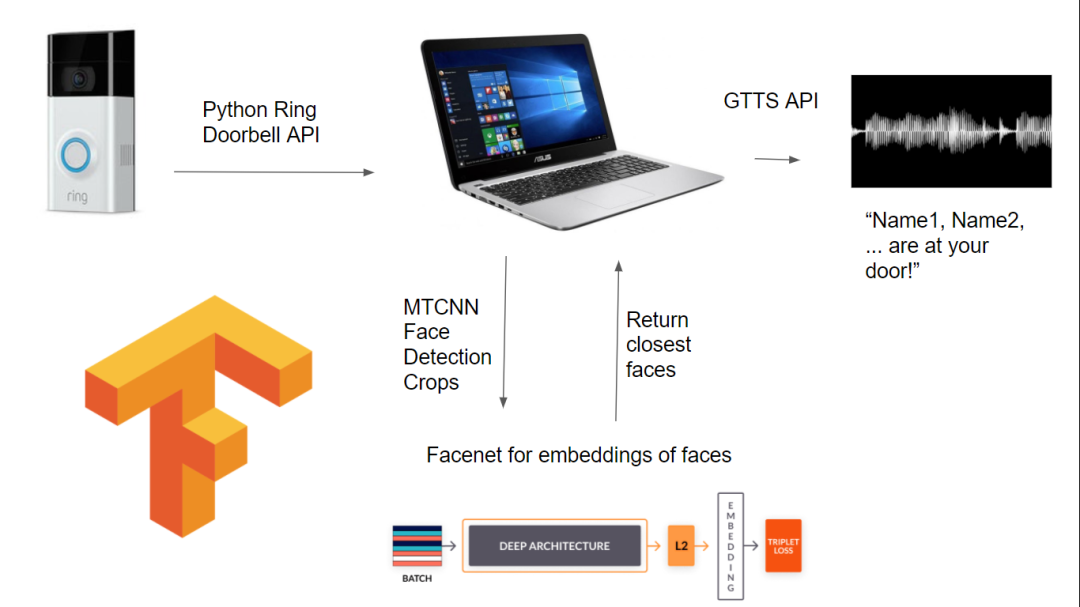
https://github.com/dude123studios/SmarterRingV2
tensorflow==2.4.1
opencv-python==4.5.1.48
mtcnn==0.1.0
ring_doorbell==0.7.0
oauthlib~=3.1.0
numpy~=1.19.5
scipy~=1.6.1
scikit-learn==0.24.1
gtts==2.2.2
playsound~=1.2.2
import os
import json
from pathlib import Path
from ring_doorbell import Ring, Auth
from oauthlib.oauth2 import MissingTokenError
cache_file = Path("test_token.cache")
def token_updated(token):
cache_file.write_text(json.dumps(token))
def otp_callback():
auth_code = input("[INPUT] 2FA code: ")
return auth_code
def main(download_only=False):
if cache_file.is_file():
auth = Auth("MyProject/1.0", json.loads(cache_file.read_text()), token_updated)
else:
username = os.environ.get('USERNAME')
password = os.environ.get('PASSWORD')
auth = Auth("MyProject/1.0", None, token_updated)
try:
auth.fetch_token(username, password)
except MissingTokenError:
auth.fetch_token(username, password, otp_callback())
ring = Ring(auth)
ring.update_data()
wait_for_update(ring, download_only=download_only)
import time
def wait_for_update(ring, download_only=False):
id = -1
start = time.time()
while True:
try:
ring.update_data()
except:
time.sleep(1)
continue
doorbell = ring.devices()['authorized_doorbots'][0]
for event in doorbell.history(limit=20, kind='ding'):
current_id = event['id']
break
if current_id != id:
id = current_id
print('[INFO] finished search in:', str(time.time() - start))
start = time.time()
if download_only:
handle_video(ring, True)
return
handle = handle_video(ring)
if handle:
text_to_speech(handle)
else:
text_to_speech('The person at the door is not very clear')
time.sleep(1)
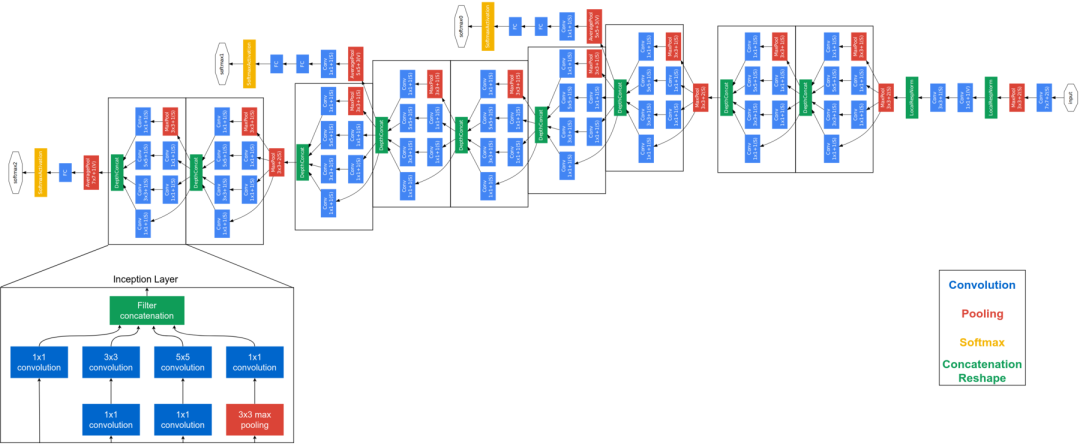
FaceNet
FaceNet架构
from tensorflow.keras.models import load_model
model = load_model('model/facenet_keras.h5')
import cv2
def normalize(img):
mean, std = img.mean(), img.std()
return (img - mean) / (std + 1e-7)
def preprocess(cv2_img):
cv2_img = normalize(cv2_img)
cv2_img = cv2.resize(cv2_img, (160, 160))
return cv2_img
def get_specific_frames(video_path, times):
vidcap = cv2.VideoCapture(video_path)
frames = []
for time in times:
vidcap.set(1, time * 15)
success, image = vidcap.read()
if success:
frames.append(image)
return frames
import os
from utils import preprocess
import cv2
import numpy as np
from sklearn.preprocessing import Normalizer
import face_recognition
import pickle
encoding_dict = {}
l2_normalizer = Normalizer('l2')
for face_names in os.listdir('data/faces/'):
person_dir = os.path.join('data/faces/', face_names)
encodes = []
for image_name in os.listdir(person_dir):
image_path = os.path.join(person_dir, image_name)
face = cv2.imread(image_path)
face = preprocess(face)
encoding = face_recognition.encode(face)
encodes.append(encoding)
if encodes:
encoding = np.sum(encodes, axis=0)
encoding = l2_normalizer.transform(np.expand_dims(encoding, axis=0))[0]
encoding_dict[face_names] = encoding
path = 'data/encodings/encoding.pkl'
with open(path, 'wb') as file:
pickle.dump(encoding_dict, file)
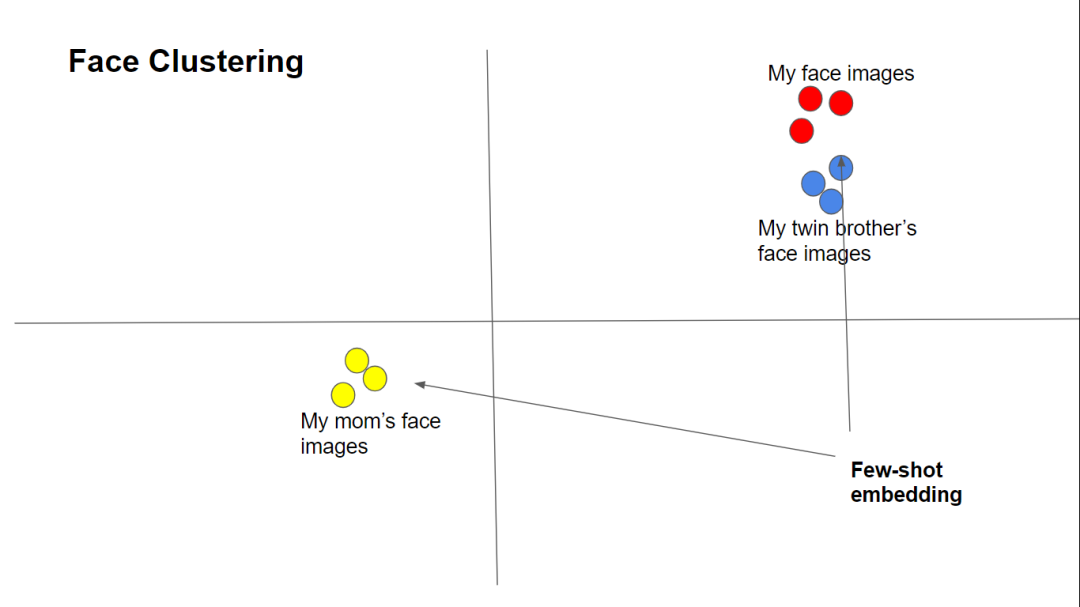
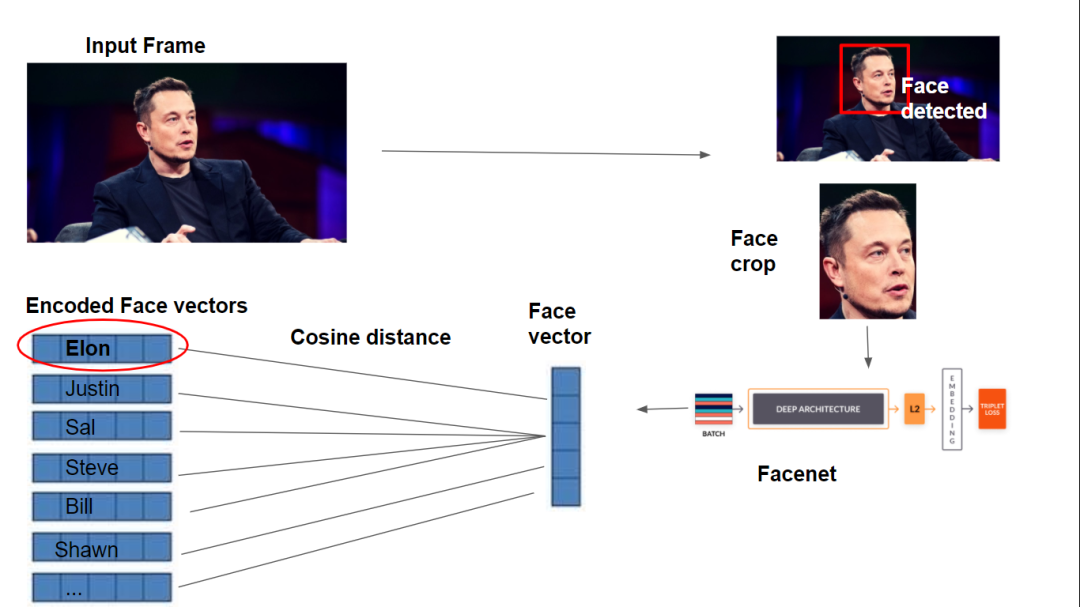
实时人脸识别
import cv2
import mtcnn
face_detector = mtcnn.MTCNN()
conf_t = 0.99
def detect_faces(cv2_img):
img_rgb = cv2.cvtColor(cv2_img, cv2.COLOR_BGR2RGB)
results = face_detector.detect_faces(img_rgb)
faces = []
for res in results:
x1, y1, width, height = res['box']
x1, y1 = abs(x1), abs(y1)
x2, y2 = x1 + width, y1 + height
confidence = res['confidence']
if confidence < conf_t:
continue
faces.append(cv2_img[y1:y2, x1:x2])
return faces
def detect_face(cv2_img):
img_rgb = cv2.cvtColor(cv2_img, cv2.COLOR_BGR2RGB)
results = face_detector.detect_faces(img_rgb)
x1, y1, width, height = results[0]['box']
cv2.waitKey(1)
x1, y1 = abs(x1), abs(y1)
x2, y2 = x1 + width, y1 + height
confidence = results[0]['confidence']
if confidence < conf_t:
return None
return cv2_img[y1:y2, x1:x2]
from utils import preprocess
from model.facenet_loader import model
import numpy as np
from scipy.spatial.distance import cosine
import pickle
from sklearn.preprocessing import Normalizer
l2_normalizer = Normalizer('l2')
def encode(img):
img = np.expand_dims(img, axis=0)
out = model.predict(img)[0]
return out
def load_database():
with open('data/encodings/encoding.pkl', 'rb') as f:
database = pickle.load(f)
return database
recog_t = 0.35
def recognize(img):
people = detect_faces(img)
if len(people) == 0:
return None
best_people = []
people = [preprocess(person) for person in people]
encoded = [encode(person) for person in people]
encoded = [l2_normalizer.transform(encoding.reshape(1, -1))[0]
for encoding in encoded]
database = load_database()
for person in encoded:
best = 1
best_name = ''
for k, v in database.items():
dist = cosine(person, v)
if dist < best:
best = dist
best_name = k
if best > recog_t:
best_name = 'UNKNOWN'
best_people.append(best_name)
return best_people
语音合成
https://www.youtube.com/watch?v=le1LH4nPfmE&ab_channel=CodeEmporium
from gtts import gTTS
from playsound import playsound
language = 'en'
slow_audio_speed = False
filename = 'tts_file.mp3'
def text_to_speech(text):
audio_created = gTTS(text=text, lang=language,
slow=slow_audio_speed)
audio_created.save(filename)
playsound(filename)
总结和Git存储库
https://github.com/dude123studios/SmarterRingV2
进一步的探索和问题
参考文献
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看
评论