
Python 操作 PDF,这两个库必须会!

Python在自动化办公方面有很多实用的第三方库,可以很方便的处理word、excel、ppt、pdf文件
今天我们就学习一下Python处理PDF文档的两个常用库「pdfplumber」、「pypdf2」
pdfplumber库按页处理 pdf ,获取页面文字,提取表格等操作
文档:https://github.com/jsvine/pdfplumber
PyPDF2 是一个纯 Python PDF 库,可以读取文档信息(标题,作者等)、写入、分割、合并PDF文档,它还可以对pdf文档进行添加水印、加密解密等
文档:https://pythonhosted.org/PyPDF2
安装:
pip install pypdf2
pip install pdfplumber
pdfplumber
提取PDF文字
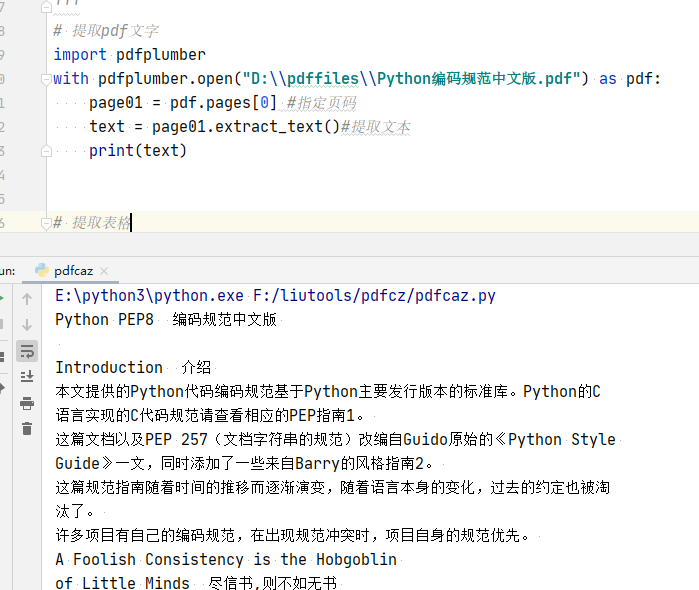
「提取单页pdf文字」
# 提取pdf文字
import pdfplumber
with pdfplumber.open("D:\\pdffiles\\Python编码规范中文版.pdf") as pdf:
page01 = pdf.pages[0] #指定页码
text = page01.extract_text()#提取文本
print(text)
「提取所有页pdf文字」
import pdfplumber
with pdfplumber.open("D:\\pdffiles\\Python编码规范中文版.pdf") as pdf:
for page in pdf.pages:
text = page.extract_text()#提取文本
print(text)
「提取所有pdf文字并写入文本中」
import pdfplumber
with pdfplumber.open("D:\\pdffiles\\Python编码规范中文版.pdf") as pdf:
for page in pdf.pages:
text = page.extract_text()#提取文本
txt_file = open("D:\\pdffiles\\Python编码规范中文版.txt",mode='a',encoding='utf-8')
txt_file.write(text)

提取PDF表格
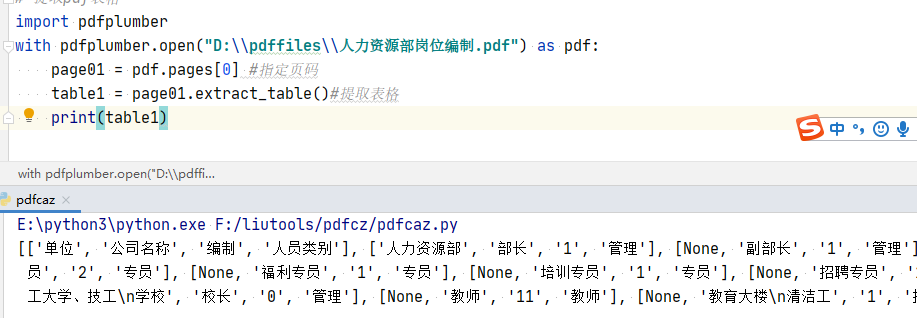
「提取表格」
# 提取pdf表格
import pdfplumber
with pdfplumber.open("D:\\pdffiles\\人力资源部岗位编制.pdf") as pdf:
page01 = pdf.pages[0] #指定页码
table1 = page01.extract_table()#提取单个表格
# table2 = page01.extract_tables()#提取多个表格
print(table1)
「提取表格,保存为excel文件」
import pdfplumber
from openpyxl import Workbook #保存表格,需要安装openpyxl
with pdfplumber.open("D:\\pdffiles\\人力资源部岗位编制.pdf") as pdf:
page01 = pdf.pages[0]
table = page01.extract_table()
workbook = Workbook()
sheet = workbook.active
for row in table:
sheet.append(row)
workbook.save(filename="D:\\pdffiles\\人力资源部岗位编制.xlsx")

PyPDF2
PyPDF2 中有两个最常用的类:PdfFileReader和PdfFileWriter,分别用于读取 PDF 和写入 PDF。其中PdfFileReader传入参数可以是一个打开的文件对象,也可以是表示文件路径的字符串。而PdfFileWriter则必须传入一个以写方式打开的文件对象。
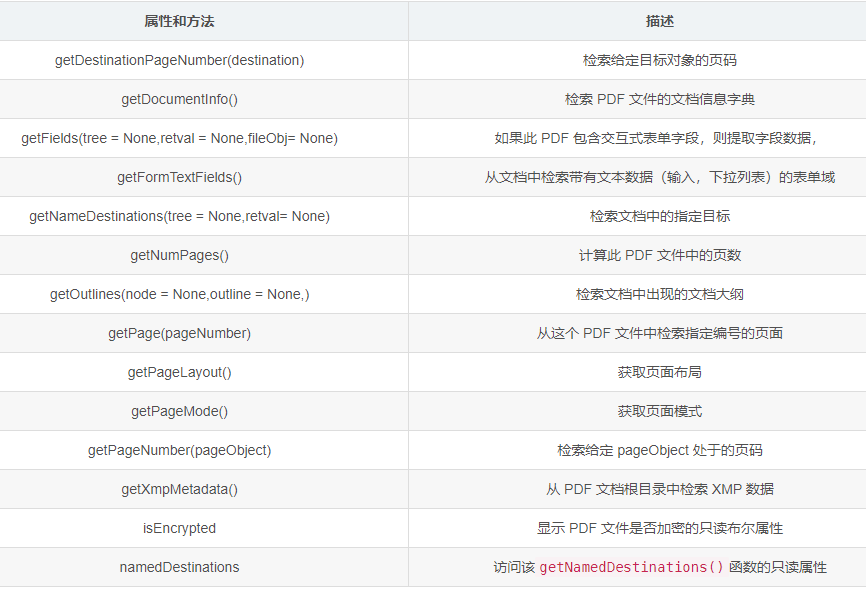
「PdfFileReader 对象的属性和方法」
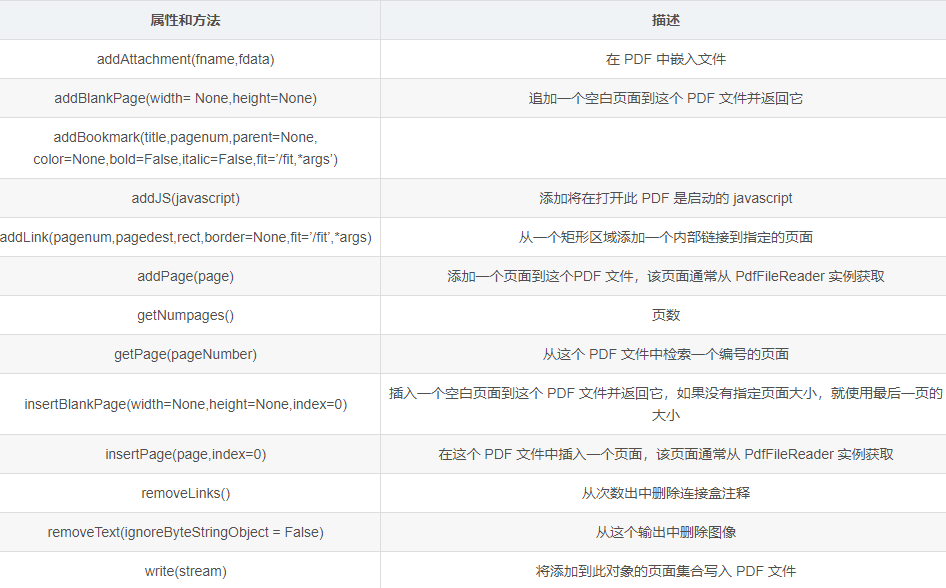
「PdfFileWriter 对象的属性和方法」
分割PDF
from PyPDF2 import PdfFileReader, PdfFileWriter
file_reader = PdfFileReader("D:\\pdffiles\\Python编码规范中文版.pdf")
# getNumPages() 获取总页数
for page in range(file_reader.getNumPages()):
# 实例化对象
file_writer = PdfFileWriter()
# 将遍历的每一页添加到实例化对象中
file_writer.addPage(file_reader.getPage(page))
with open("D:\\pdffiles\\{}.pdf".format(page),'wb') as out:
file_writer.write(out)
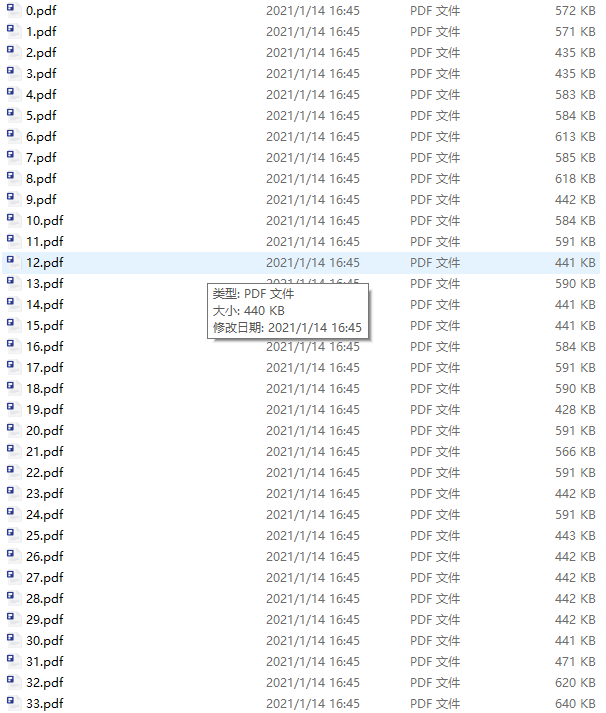
合并PDF
将上述分割的pdf合并成一个文件
「示例代码」
from PyPDF2 import PdfFileReader, PdfFileWriter
file_writer = PdfFileWriter()
for page in range(34):
# 循环读取需要合并pdf文件
file_reader = PdfFileReader("D:\\pdffiles\\{}.pdf".format(page))
# 遍历每个pdf的每一页
for page in range(file_reader.getNumPages()):
# 写入实例化对象中
file_writer.addPage(file_reader.getPage(page))
with open("D:\\pdffiles\\合并.pdf",'wb') as out:
file_writer.write(out)
PDF旋转
# 旋转pdf,只能按照90度的倍数旋转
from PyPDF2 import PdfFileReader, PdfFileWriter
file_reader = PdfFileReader("D:\\pdffiles\\Python编码规范中文版.pdf")
file_writer = PdfFileWriter()
page = file_reader.getPage(0).rotateClockwise(90) # 第1页顺时针旋转90度
file_writer.addPage(page) # 写入
page = file_reader.getPage(1).rotateCounterClockwise(90) # 第2页逆时针旋转90度
file_writer.addPage(page) # 写入
with open("D:\\pdffiles\\旋转.pdf",'wb') as out:
file_writer.write(out)
PDF加密解密
「添加密码」
from PyPDF2 import PdfFileReader, PdfFileWriter
file_reader = PdfFileReader("D:\\pdffiles\\Python编码规范中文版.pdf")
file_writer = PdfFileWriter()
for page in range(file_reader.getNumPages()):
file_writer.addPage(file_reader.getPage(page))
file_writer.encrypt('123456') # 设置密码
with open("D:\\pdffiles\\加密后.pdf",'wb') as out:
file_writer.write(out)
打开文件,提示输入密码
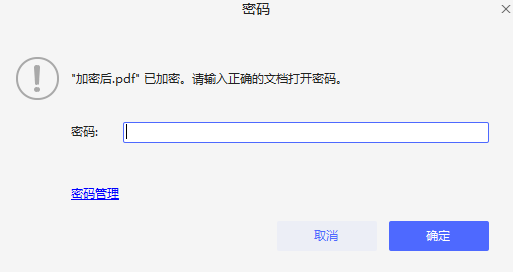
「解除密码」
from PyPDF2 import PdfFileReader, PdfFileWriter
file_reader = PdfFileReader("D:\\pdffiles\\加密后.pdf")
file_reader.decrypt('123456')
file_writer = PdfFileWriter()
for page in range(file_reader.getNumPages()):
file_writer.addPage(file_reader.getPage(page))
with open("D:\\pdffiles\\解密后.pdf",'wb') as out:
file_writer.write(out)
PDF添加水印
首先准备一个水印文档,可以用空白word添加图片或者文字转成pdf文件。

「示例代码」
# 添加水印
from PyPDF2 import PdfFileReader, PdfFileWriter
from copy import copy
sy = PdfFileReader("D:\\pdffiles\\水印.pdf")
mark_page = sy.getPage(0) # 水印所在的页数
# 读取添加水印的文件
file_reader = PdfFileReader("D:\\pdffiles\\Python编码规范中文版.pdf")
file_writer = PdfFileWriter()
for page in range(file_reader.getNumPages()):
# 读取需要添加水印每一页pdf
source_page = file_reader.getPage(page)
new_page = copy(mark_page) #
new_page.mergePage(source_page) # new_page(水印)在下面,source_page原文在上面
file_writer.addPage(new_page)
with open("D:\\pdffiles\\添加水印后.pdf",'wb') as out:
file_writer.write(out)
添加水印后的文档:


评论