
详细解读 Transformer的即插即用模块 | MoE插件让ViT模型更宽、更快、精度更高


本文提出Transformer更宽而不是更深,以实现更高效的参数部署,并将此框架实现为WideNet。首先通过在Transformer块之间共享参数来压缩可训练参数和深度,并用MoE层替换了FFN层。实验表明,WideNet通过较少的可训练参数实现了最佳性能,优于ViT等网络。
作者单位:新加坡国立大学
1简介
Transformer最近在各种任务上取得了令人瞩目的成果。为了进一步提高Transformer的有效性和效率,现有工作中有2种思路:
通过扩展到更多可训练的参数来扩大范围;
通过参数共享或模型压缩随深度变浅。
然而,当可供训练的Token较少时,较大的模型通常无法很好地扩展,而当模型非常大时,则需要更高的并行性。由于表征能力的损失,与原始Transformer模型相比,较小的模型通常会获得较差的性能。
在本文中,为了用更少的可训练参数获得更好的性能,作者提出了一个通过更宽的模型框架来有效地部署可训练参数。特别地,作者通过用MoE替换前馈网络(FFN)来沿模型宽度进行缩放。然后,使用单个层归一化跨Transformer Block共享MoE层。这种部署起到了转换各种语义表征的作用,这使得模型参数更加高效和有效。
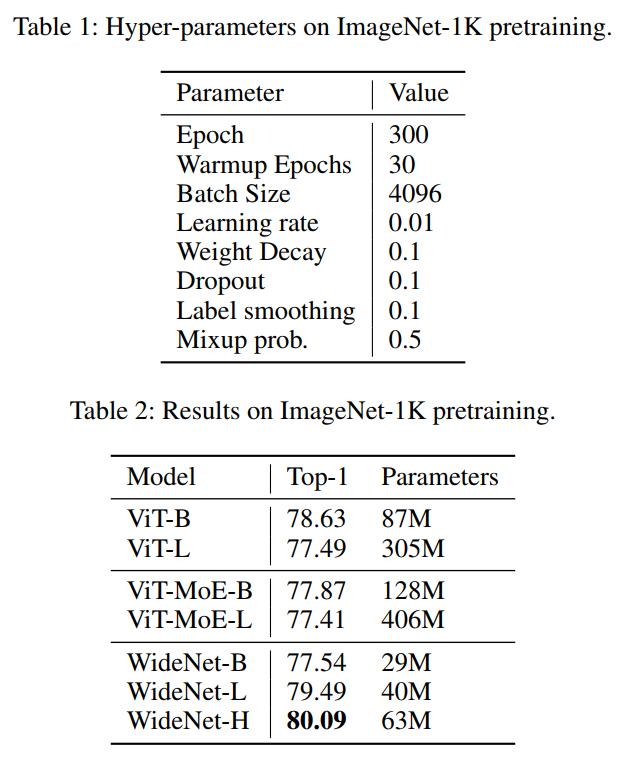
为了评估所提的框架,作者设计了WideNet并在ImageNet-1K上对其进行评估。最好的模型在0.72倍可训练参数下的性能比ViT高1.46%。使用0.46×和0.13×参数的WideNet仍然可以分别超过ViT和ViT-MoE0.83%和2.08%。
本文主要贡献
为了提高参数效率,提出了跨Transformer Block的共享MoE层。MoE层可以在不同的Transformer Block中接收到不同的Token表示,这使得每个MoE都能得到充分的训练;
在Transformer Block之间保持单独的标准化层。单独的层具有少量额外的可训练参数可以将输入隐藏向量转换为其他语义。然后,将不同的输入输入到同一Attention层或更强的MoE层,以建模不同的语义信息。
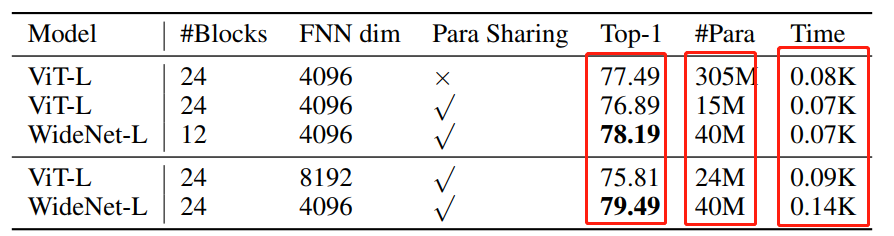
结合以上2种思路,作者提出了更广、更少参数、更有效的框架。然后将用这个框架构建了WideNet,并在ImageNet上对其进行评估。WideNet在可训练参数少得多的情况下,性能大大优于Baseline。
2Methodology
本文研究了一种新的可训练参数部署框架,并在Transformer上实现了该框架。总体结构如图所示。在这个例子中使用Vision Transformer作为Backbone,这意味着在Attention或FFN层之前进行规范化。
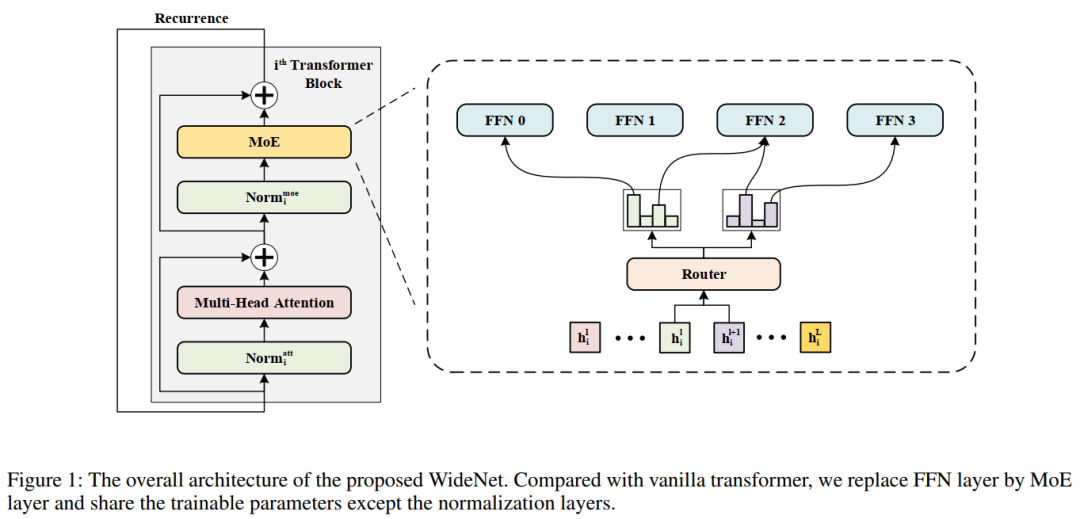
WideNet可以很容易地扩展到其他Transformer模型。在WideNet中用MoE层代替FFN层。采用跨Transformer Block的参数共享,以实现更有效的参数部署。在每个MoE层中有一个路由器来选择K个专家来学习更复杂的表示。请注意,为了更多样化的语义表示,层标准化中的可训练参数不是共享的。
2.1 MoE条件计算
核心理念是沿着宽度部署更多的可训练参数,沿着深度部署更少的可训练参数。为此,作者使用MoE将Transformer缩放到大量的可训练参数。MoE作为一种典型的条件计算模型,只激活少数专家,即网络的子集。对于每个输入只将需要处理的隐藏表示的一部分提供给选定的专家。
根据Shazeer,给定E个可训练专家,输入表示
, MoE模型的输出可以表示为:
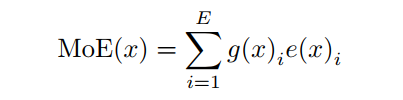
其中
为非线性变换,
为可训练路由器
输出的第
个元素,通常
和
都是由神经网络参数化的。
由上式可知,当
为稀疏向量时,在训练过程中,只有部分专家会被反向传播激活和更新。在本文中,对于普通的MoE和WideNet,每个专家都是一个FFN层。
2.2 Routing
为了保证稀疏Routing
,使用TopK()来选择排名最高的专家。根据Riquelme论文
可表示为:
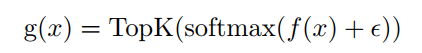
式中
为路由线性变换,
为专家路由的高斯噪声。在
之后使用softmax,以获得更好的性能和更稀疏的专家。当K<<E时,
的大部分元素为零,从而实现稀疏条件计算。
2.3 Balanced Loading
在基于MoE的Transformer中将每个Token分派给K个专家。在训练期间,如果MoE模型没有规则,大多数Token可能会被分派给一小部分专家。这种不平衡的分配会降低MoE模型的吞吐量。
此外,更重要的是,大多数附加的可训练参数没有得到充分的训练,使得稀疏条件模型在缩放时无法超越相应的稠密模型。因此,为了平衡加载需要避免2件事:
分配给单个专家的Token太多,
单个专家收到的Token太少。
为了解决第1个问题,需要缓冲容量B。也就是说,对于每个专家,最多只保留B个Token,不管分派给该专家多少Token。如果分配了超过B个Token,那么左边的Token将被丢弃:
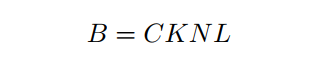
其中C是容量比,这是一个预定义的超参数,用于控制为每个专家保留的Token的比例。通常,
,在没有特别说明的情况下,设C为1.2。K是每个token选择的专家数量。N为每个设备上的batch-size。L是序列的长度。对于计算机视觉任务,L表示每幅图像中patch Token的数量。
缓冲区容量B帮助每个专家去除冗余token以最大化吞吐量,但它不能确保所有专家都能收到足够的token进行训练。换句话说,直到现在,路由仍然是不平衡的。因此,使用可微分的负载均衡损失,而不是在路由器中均衡负载时单独的负载均衡和重要性权重损失。对于每个路由操作,给定E专家和N批带有NL token,在训练时模型总损失中加入以下辅助损失:
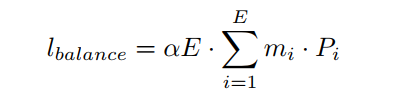
其中
是向量。第
i$的token的比例:
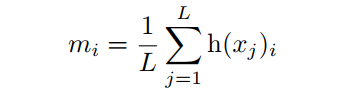
式中
为Eq.2中TopK选取的指标向量。
是
的第
个元素。值得注意的是,与Eq.2中的
不同,
和
是不可微的。然而,需要一个可微分的损失函数来优化端到端的MoE。因此,将式4中的
定义为:
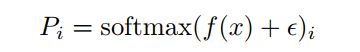
可以看出
是softmax激活函数后路由线性变换的第
个元素,并且
是可微的。
负载均衡损失的目的是实现均衡分配。当最小化
时,可以看到m和P都接近均匀分布。
2.4 Cross Transformer blocks共享MoE
如图1所示,WideNet采用跨Transformer blocks参数共享的方式。使用参数共享有2个原因。首先,在本文中目标是一个更参数有效的框架。其次,由于使用MoE层来获得更强的建模能力,为了克服稀疏条件计算带来的过拟合问题,需要给每个专家提供足够的token。为此,WideNet使用相同的路由器和专家在不同的Transformer blocks。
形式上,给定隐藏表示
作为第1个Transformer blocks的输入,可以将参数共享定义为
,这与现有的基于MoE的模型
不同。
请注意,虽然在包括路由器在内的MoE层共享可训练参数,但对应于同一Token的Token表示在每个Transformer blocks中是不同的。也就是说,
和
可以派给不同的专家。因此,每个专家将接受更多不同的Token的训练,以获得更好的性能。
2.5 Individual Layer Normalization
虽然现有的工作表明不同Transformer blocks的激活是相似的,但余弦距离仍然远远大于零。因此,不同于现有的作品在Transformer blocks之间共享所有权重,为了鼓励不同块更多样化的输入表示,这里只共享multi-head attention layer和FFN(或MoE)层,这意味着层标准化的可训练参数在块之间是不同的。
综上所述,框架中的第
个Transformer blocks可以写成:
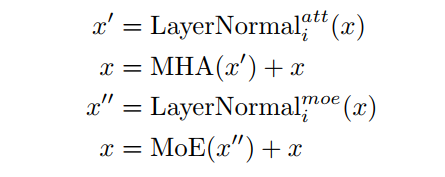
标准化层LayerNormal(·)为:
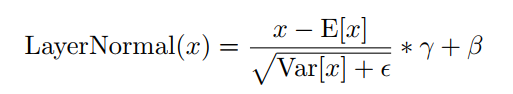
其中
和
是2个可训练的参数。
层归一化只需要这2个小向量,所以单独的归一化只会在框架中添加一些可训练的参数。可以发现共享层标准化和单个标准化之间的差异是输出的平均值和大小。对于共享层归一化,MHA和MoE层的输入在不同的Transformer blocks中更相似。由于共享了可训练矩阵,鼓励更多样化的输入以在不同的Transformer blocks中表示不同的语义。
3Optimization
虽然在每个Transformer block中重用了路由器的可训练参数,但由于输入表示的不同,分配也会不同。因此,给定T次具有相同可训练参数的路由操作,需要优化的损失如下:
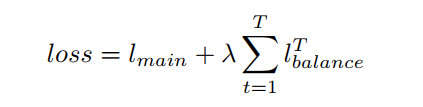
其中λ是一个超参数,以确保平衡分配,将其设置为一个相对较大的数,即在本工作中为0.01。与现有的基于MoE的模型相似,作者发现该模型的性能对λ不敏感。
是Transformer的主要目标。例如,在有监督图像分类中,
是交叉熵损失。
4实验
5参考
[1].Go Wider Instead of Deeper
6推荐阅读

超越MobileNet V3 | 详解SkipNet+Bias Loss=轻量化模型新的里程碑
CSL-YOLO | 超越Tiny-YOLO V4,全新设计轻量化YOLO模型实现边缘实时检测!!!
DA-YOLO |多域自适应DA-YOLO解读,恶劣天气也看得见(附论文)
长按扫描下方二维码添加小助手并加入交流群,群里博士大佬云集,每日讨论话题有目标检测、语义分割、超分辨率、模型部署、数学基础知识、算法面试题分享的等等内容,当然也少不了搬砖人的扯犊子
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
