
超硬核详细学习——深入浅出IO的知识点,值得你学习收藏必备
I/O高级流
昨天我们对高级流中的缓冲流学习,而在IO流的整个大体系中,他还有一些高级流等待着我们来解锁。
所以话不多说,今天我们先来学习其中一种高级流——转换流。
转换流
在上面,我们知道使用字节流读取中文的时候,会出现乱码的问题,为什么会出现乱码呢?编码格式是什么呢。我们在最后使用了字符流进行操作文本,那我们可以做两者之间的转换吗?接下来我们就一起详细的学习这个转换流的由来吧。

可以看图知道字节和字符的转换就是通过一定编码和解码的操作完成的。为什么会出现乱码呢?具体一起来看看吧。
字符编码和解码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本f符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
可以用我们所学习的Java解释为:
String(byte[] bytes, String charsetName): 通过指定的字符集解码字节数组
byte[] getBytes(String charsetName): 使用指定的字符集合把字符串编码为字节数组
复制代码通俗易懂的来说,不知道大家有没有看过孙红雷演过的<潜伏>这部电视剧,就算没看过,大家也都是知道谍战片吧。假如,你和我都是间谍,潜伏在敌营中,然后要互相通信。你会直接说一段话,或者寄信然后里面写着:今晚在天台见面给我吗?我保证,如果有你这样的队友,潜伏行动不出一天,就直接Over,大家一起玩完。所以我们不能这样嘛,我们要用的一定格式规则来进行转换对吧,这样就算是真的有敌人拿到了这封信,也会懵逼,想着这。。。是什么?然后也会不了了之。大不了今晚不见面,至少保证了我们的存活,安全问题。
那这其中,我们不得先有一定的规则,可以让你我进行转换后都能看懂得的表格数据,我们称这规则称为字符编码:就是一套自然语言的字符与二进制数之间的对应规则。
而这表格可以相当于我们参照的转换的规则,称之为字符集(编码表):生活中文字和计算机中二进制的对应规则。
当你写信的时候,这过程就是把你我看得懂的东西,按我们知道的规则,进行转换为谁都看不懂的东西,这过程就是编码。
当我得到你的信的时候,这过程,我不就把这段看不懂的文字进行规则解析,这过程就是解码。
这其中要是你喝酒醉写信给我,不按套路出牌,年轻人不讲武德,按另一种规则来编写,然后我按我们的规则来解析,解析完后,都看不懂就一脸问号,这就可以称之为乱码了。
所以我们现在先来了解下规则即字符集:
字符集
Charset:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有
ASCII字符集、GBK字符集、Unicode字符集等。当我们知道了编码格式后,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。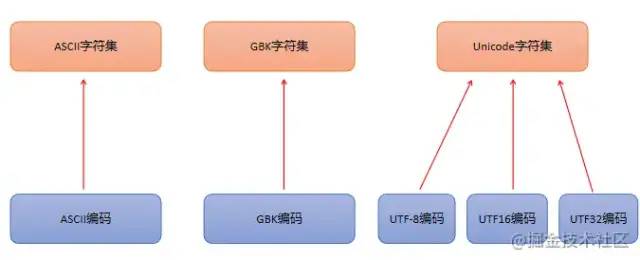
以下字符集是我网上找到相对比较全的,如果还想再多了解的话,可以自行百度。毕竟我们是面向百度编程。嘿嘿。
Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,
UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:GB就是国标的意思,是为了显示中文而设计的一套字符集。
GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在
ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。GBK:最常用的中文码表。是在
GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
ISO-5559-1使用单字节编码,兼容ASCII编码。ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。基本的
ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。ASCII字符集 :
ISO-8859-1字符集:
GBxxx字符集:
Unicode字符集 :
128个
US-ASCII字符,只需一个字节编码。拉丁文等字符,需要二个字节编码。
大部分常用字(含中文),使用三个字节编码。
其他极少使用的
Unicode辅助字符,使用四字节编码。
乱码问题
为什么我们读取文件会出现乱码呢,因为我们的编辑器IDEA默认的编码格式是UTF-8,而如果我们文件格式不是UTF-8格式的话就会读错,一般来说,IDEA创建的文件一般也是UTF-8格式,读取和写入都不会有任何问题,但是呢,如果我们是在Windows下创建文件的话,其默认是ASCII,会跟随系统默认的编码格式,实际就是GBK格式。所以我们文件是GBK格式,而读取的是UTF-8格式,自然就乱码了。
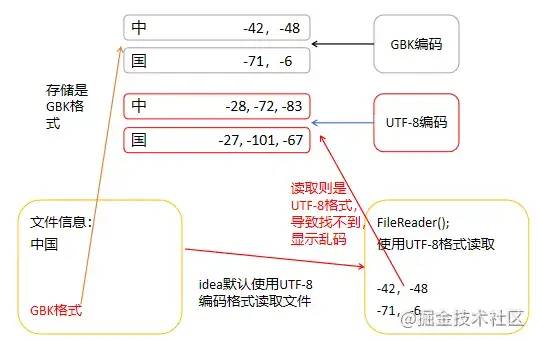
代码演示下乱码:
public class ReaderTest {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("E:\\demo\\China.txt");
int ch;
while((ch = fr.read()) != -1) {
System.out.println((char) ch);
}
fr.close();
}
}
程序执行结果:
�й�
复制代码是不是完全看不出什么东西呢,你说你能看出,我就算你厉害。

那我们要如何解决乱码问题呢,也就是解决编码问题呢?是时候祭出转换流了。让你觉得乱码不是啥问题。
InputStreamReader
InputStreamReader:将字节流以字符流输入,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以是默认字符集即你的编辑器是什么字符集就是什么字符集。
1. 构造方法
public InputStreamReader(InputStream in):创建一个使用默认字符集的字符流。public InputStreamReader(InputStream in, String charsetName):创建一个指定字符集的字符流。演示如下:
public class IpsrTest {
public static void main(String[] args) throws FileNotFoundException, UnsupportedEncodingException {
InputStreamReader isr = new InputStreamReader(new FileInputStream("e:\\demo\\China.txt"));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("e:\\demo\\China.txt"), "GBK");
}
}
复制代码
2. 解决乱码问题
public class ReadTest2 {
public static void main(String[] args) throws IOException {
String fileName = "E:\\demo\\China.txt";
//创建转换流,默认字符集
InputStreamReader isr = new InputStreamReader(new FileInputStream(fileName));
//创建转换流,指定字符集
InputStreamReader isr2 = new InputStreamReader(new FileInputStream(fileName), "GBK");
int ch;
//默认字符集读取
while((ch = isr.read()) != -1) {
System.out.print((char) ch);
}
isr.close();
//指定字符集读取
while((ch = isr2.read()) != -1) {
System.out.print((char) ch);
}
isr2.close();
}
}
程序执行结果:
�й�
中国
复制代码是不是很好的解决乱码问题呢,妈妈再也不担心我看不懂文件啦。有读取的转换流,当然还有写出的转换流啦,一起来看看吧。
OutputStreamWriter
OutputStreamWriter:将字节流以字符流输入,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以是默认字符集即你的编辑器是什么字符集就是什么字符集。
1. 构造方法
public OutputStreamWriter(OutputStream in):创建一个使用默认字符集的字符流。public OutputStreamWriter(OutputStream in, String charsetName):创建一个指定字符集的字符流。演示如下:
public class WriterTest {
public static void main(String[] args) throws FileNotFoundException, UnsupportedEncodingException {
OutputStreamWriter osr = new OutputStreamWriter(new FileOutputStream("e:\\demo\\ChinaOut.txt"));
OutputStreamWriter osr2 = new OutputStreamWriter(new FileOutputStream("e:\\demo\\ChinaOut.txt") , "GBK");
}
}
复制代码
2. 以指定编码写出数据
public class WriterTest2 {
public static void main(String[] args) throws IOException {
// 定义文件路径
String fileName = "E:\\demo\\ChinaOut.txt";
// 创建流对象,默认UTF8编码
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(fileName));
// 写出数据
osw.write("北极星");
osw.close();
String fileName2 = "E:\\demo\\ChinaOut2.txt";
// 创建流对象,指定GBK编码
OutputStreamWriter osw2 = new OutputStreamWriter(new FileOutputStream(fileName2),"GBK");
// 写出数据
osw2.write("叫我了");
osw2.close();
}
}
程序执行后结果:
北极星
叫我啦
复制代码再看记事本格式,可以发现如果存储的是UTF-8,记事本的格式也更改为了UTF-8编码格式了,而指定了GBK字符集,则记事本的格式为ASCII编码格式了。
总结
相信各位看官都对IO流中高级流中的转换流类有了一定了解,期待等待下一章的高级流——打印流教学吧!
当然还有很多流等着下次一起看吧!欢迎期待下一章的到来!
学到这里,今天的世界打烊了,晚安!虽然这篇文章完结了,但是我还在,永不完结。我会努力保持写文章。来日方长,何惧车遥马慢!
感谢各位看到这里!愿你韶华不负,青春无悔!
注: 如果文章有任何错误和建议,请各位大佬尽情留言!如果这篇文章对你也有所帮助,希望可爱亲切的您给个三连关注下,非常感谢啦!

作者:太子爷哪吒
链接:https://juejin.cn/post/6995147286112108551
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。