
GPU现在 vs. ASIC未来
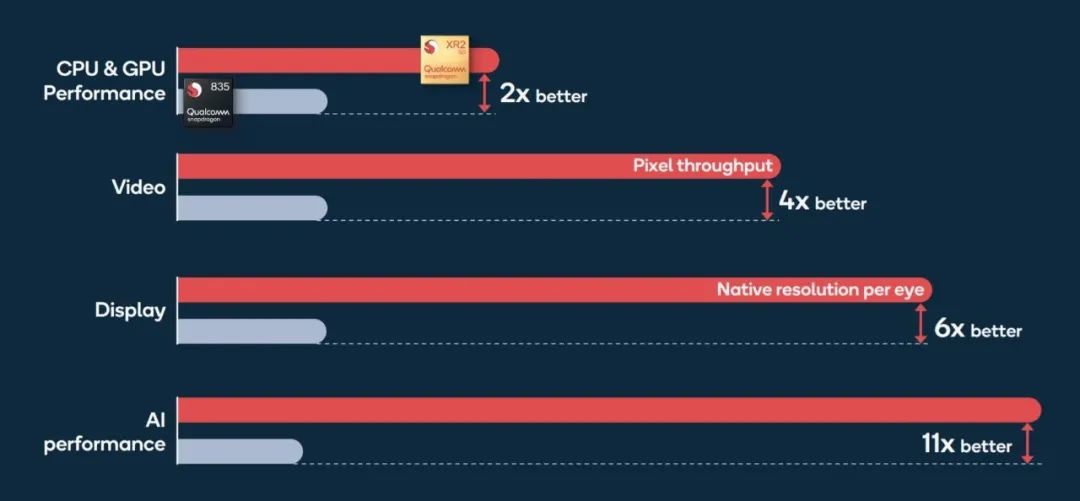

本文内容参考自动驾驶系列报告“自动驾驶系列报告:自动驾驶芯片GPU的现在和ASIC的未来(车载芯片)”,梳理车载芯片的发展历程,探讨未来发展方向。自动驾驶专题系列下载方式如下:
来源:全球政企解决方案
系列报告一:综合篇:自动驾驶的时代已经开始到来
系列报告二:决策层篇:自动驾驶系统量产导向还是性能导向
系列报告三:车载芯片篇,自动驾驶芯片GPU的现在和ASIC的未来
系列报告四:传感器篇,多传感器融合
系列报告五:控制执行篇,转向制动电子化,自动驾驶的必由之路
过去汽车电子芯片以与传感器一一对应的电子控制单元(ECU)为主,主要分布与发动机等核心部件上。随着汽车智能化的发展,汽车传感器越来越多,传统的分布式架构逐渐落后,由中心化架构 DCU、MDC 逐步替代。
随着人工智能发展,汽车智能化形成趋势,目前辅助驾驶功能渗透率越来越高,这些功能的实现需借助于摄像头、雷达等新增的传感器数据,其中视频(多帧图像)的处理需要大量并行计算,传统 CPU 算力不足,这方面性能强大的 GPU 替代了 CPU。再加上辅助驾驶算法需要的训练过程,GPU+FPGA 成为目前主流的解决方案。
着眼未来,自动驾驶也将逐步完善,届时会加入激光雷达的点云(三维位置数据)数据以更多的摄像头和雷达传感器,GPU 也难以胜任,ASIC 性能、能耗和大规模量产成本均显著优于 GPU 和 FPGA,定制化的ASIC 芯片可在相对低水平的能耗下,将车载信息的数据处理速度提升更快,随着自动驾驶的定制化需求提升,ASIC 专用芯片将成为主流。本文以如上顺序梳理车载芯片发展历程,探讨未来发展方向。
ECU(Electronic Control Unit)是电子控制单元,也称“行车电脑”,是汽车专用微机控制器。一般 ECU 由 CPU、存储器(ROM、RAM)、输入/输出接口(I/O)、模数转换器(A/D)以及整形、驱动等大规模集成电路组成。
ECU 的工作过程就是 CPU 接收到各个传感器的信号后转化为数据,并由Program 区域的程序对 Data 区域的数据图表调用来进行数据处理,从而得出具体驱动数据,并通过 CPU针脚传送到相关驱动芯片,驱动芯片再通过相应的周边电路产生驱动信号,用来驱动驱动器。即传感器信号——传感器数据——驱动数据——驱动信号这样一个完整工作流程。
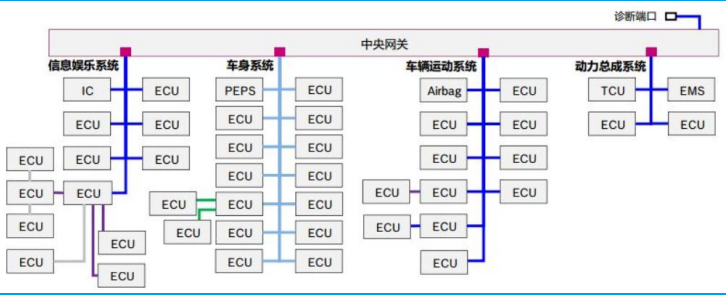
随着汽车电子化的发展,车载传感器数量越来越多,传感器与 ECU 一一对应使得车辆整体性下降,线路复杂性也急剧增加,此时 DCU(域控制器)和 MDC(多域控制器)等更强大的中心化架构逐步替代了分布式架构。
人工智能的发展也带动了汽车智能化发展,过去的以 CPU 为核心的处理器越来越难以满足处理视频、图片等非结构化数据的需求,同时处理器也需要整合雷达、视频等多路数据,这些都对车载处理器的并行计算效率提出更高要求,而 GPU 同时处理大量简单计算任务的特性在自动驾驶领域取代CPU成为了主流方案。
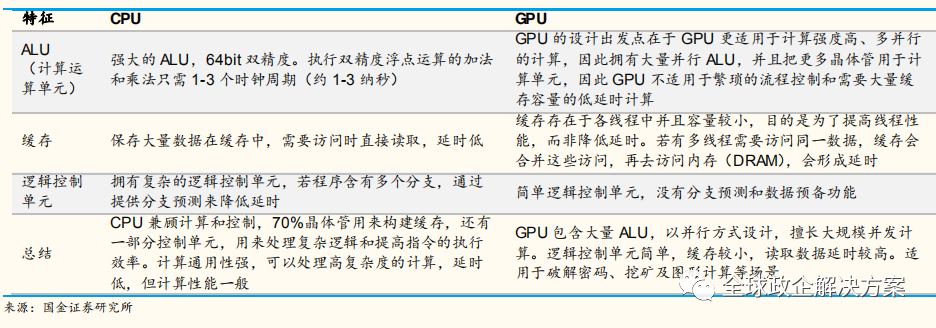
CPU 的核心数量只有几个(不超过两位数),每个核都有足够大的缓存和足够多的数字和逻辑运算单元,并辅助很多复杂的计算分支。而 GPU 的运算核心数量则可以多达上百个(流处理器),每个核拥有的缓存大小相对小,数字逻辑运算单元也少而简单。
CPU和 GPU 最大的区别是设计结构不同结构形成的不同功能。CPU的逻辑控制功能强,可以进行复杂的逻辑运算,并且延时低,可以高效处理复杂的运算任务。而 GPU逻辑控制和缓存较少,使得每单个运算单元执行的逻辑运算复杂程度有限,但并列大量的计算单元,可以同时进行大量较简单的运算任务。

GPU 占据现阶段自动驾驶芯片主导地位,相比于消费电子产品的芯片,车载的智能驾驶芯片对性能和寿命要求都比较高,主要体现在以下几方面:
1、耗电每瓦提供的性能;
2、生态系统的构建,如用户群、易用性等;
3、满足车规级寿命要求,至少 1 万小时稳定使用。
目前无论是尚未商业化生产的自动驾驶 AI 芯片还是已经可以量产使用的辅助驾驶芯片,由于自动驾驶算法还在快速更新迭代,对云端“训练”部分提出很高要求,既需要大规模的并行计算,需要大数据的多线程计算,因此以 GPU+FPGA 解决方案为核心;在终端的“推理”部分,核心需求是大量并行计算,从而以 GPU为核心。
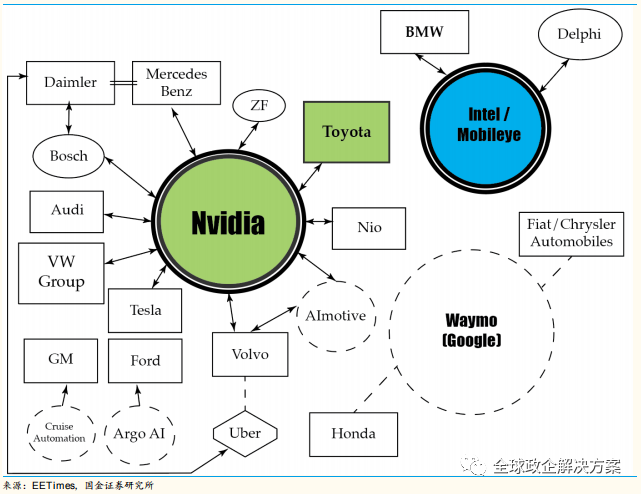
NVIDIA 在自动驾驶领域的成就正是得益于他们在 GPU 领域内的深耕,NVIDIA GPU 专为并行计算而设计,适合深度学习任务,并且能够处理在深度学习中普遍存在的向量和矩阵操作。相对于 Mobileye 专注于视觉处理,NVIDIA 的方案重点在于融合不同传感器。
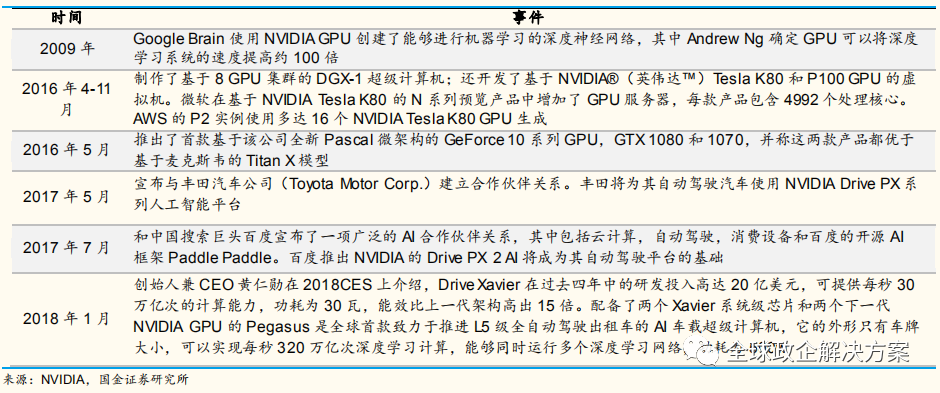
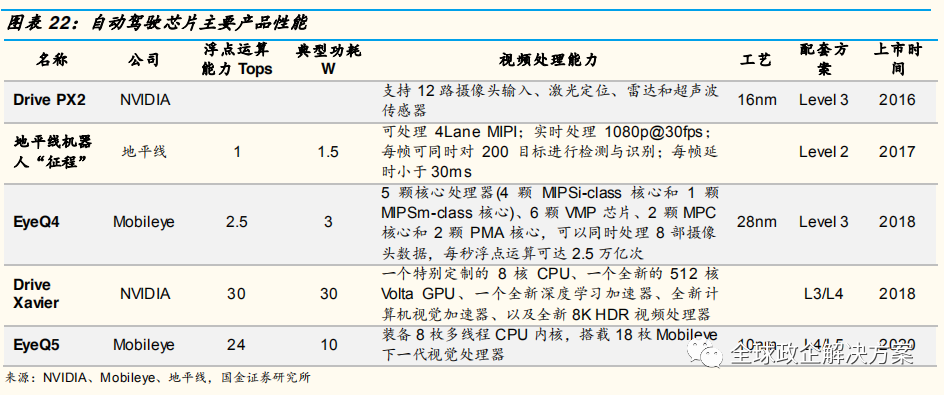
2016 年,英伟达在 Drive PX 2 平台上推出了三款产品,分别是配备单GPU 和单摄像头及雷达输入端口的 Drive PX2 Autocruise(自动巡航)芯片(下图左上)、配备双 GPU 及多个摄像头及雷达输入端口的 Drive PX2 AutoChauffeur(自动私人司机)芯片(右上)、配备多个 GPU 多个摄像头及雷达输入端口的 Drive PX2 Fully Autonomous Driving(全自动驾驶)芯片。
以目前的销售情况,Drive PX 2 搭载上一代 Pascal 架构 GPU 已经实现量产,并且已经搭载在 Tesla 的量产车型 Model S 以及Model X 上。目前PX 2 仍然是 NVIDIA 自动驾驶平台出货的主力,Tesla,Audi 和 ZF 等对外公布 Drive PX 2 应用在量产车上。
Xavier 是 Drive PX 2 的进化版本,搭配了最新一代的 Volta 架构 GPU, 相较于 Drive PX 2 性能将提升近一倍,2017 年年底量产。由于多家主机厂L3 级别以上自动驾驶量产车的计划在 2020 年左右,而 Xavier 的量产计划将能和自动驾驶车的研发周期相互配合(一般 3 年左右),因此 Xavier 的合作都是有量产车落地计划的。
而对于较早与 NVIDIA 达成合作的车厂来说,他们在小批量测试、量产的优先级别以及可定制化空间等方面都能获得一定的优势。
目前,L4 及以上的市场基本上被 NVIDIA 垄断,CEO 黄仁勋称全球有 300余家自动驾驶研发机构使用 Drive PX2。Drive PX 2 单价为 1.6 万美金,功耗达 425 瓦,但目前没有达到车规,按功耗和成本看,只能小规模测试阶段使用。
四维图新国内地图行业龙头,向 ADAS 和自动驾驶进军。公司成立于 2002 年,是国内首家获导航地图制作资质的企业(目前仅 13 家),为领先的数字地图内容、车联网与动态交通信息服务、基于位置的大数据垂直应用服务的提供商之一。其拳头业务——地图业务,以国内 60%的份额稳居垄断地位。2017 年以来,公司收购杰发科技、入股中寰卫星与禾多科技,“高精度地图+芯片+算法+软件”的自动驾驶产业链全方位布局雏形已现。
收购杰发科技布局汽车芯片。杰发科技(2017 年 3 月完成收购)脱胎于联发科,主攻车载信息娱乐系统芯片。现阶段在国内后装市场市占率超 70%,前装超 30%(主要为吉利、丰田等车企),其车规级 IVI 芯片被多家国际主流零部件厂商采用,并计划推出 AMP、MCU 及TPMS(胎压监测)芯片等新一代产品。公司通过收购杰发科技,具备了为车厂提供高性能汽车电子芯片的能力,打通从软件到硬件的关键性关卡,并与蔚来、威马、爱驰亿维等造车新势力公司达成了合作。
该芯片采用 64 位 Quad A53 架构,内置硬件图像加速引擎,支持双路高清视频输出,和四路高清视频输入,能同时支持高级车载影音娱乐系统全部功能和丰富的 ADAS 功能。功能包括:360°全景泊车系统、车道偏移警示系统 LDW、前方碰撞警示系统 FCW、行人碰撞警示系统 PCW、交通标志识别系统 TSR、车辆盲区侦测系统 BSD、驾驶员疲劳探测系统 DFM 和后方碰撞预警系统 RCW 等。
GPU适用于单一指令的并行计算,而 FPGA 与之相反,适用于多指令,单数据流,常用于云端的“训练”阶段。此外与 GPU对比,FPGA 没有存取功能,因此速度更快,功耗低,但同时运算量不大。结合两者优势,形成GPU+FPGA 的解决方案。
FPGA 和 ASIC 的区别主要在是否可以编程。FPGA 客户可根据需求编程,改变用途,但量产成本较高,适用于应用场景较多的企业、军事等用户;而 ASIC 已经制作完成并且只搭载一种算法和形成一种用途,首次“开模”成本高,但量产成本低,适用于场景单一的消费电子、“挖矿”等客户。目前自动驾驶算法仍在快速更迭和进化,因此大多自动驾驶芯片使用GPU+FPGA 的解决方案。未来算法稳定后,ASIC 将成为主流。
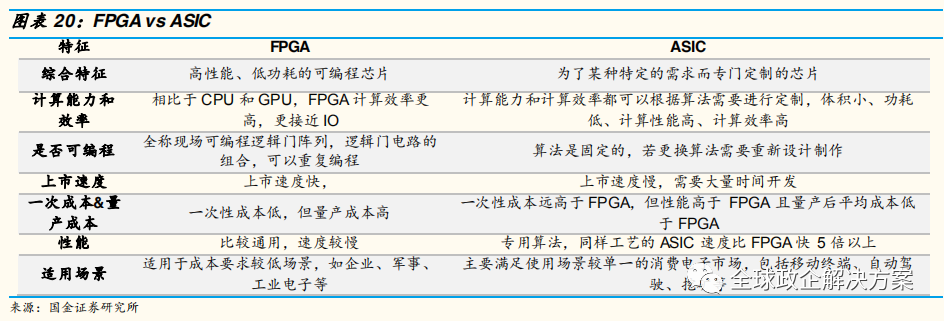
计算能耗比,ASIC > FPGA > GPU > CPU,究其原因,ASIC 和 FPGA 更接近底层 IO,同时 FPGA 有冗余晶体管和连线用于编程,而 ASIC 是固定算法最优化设计,因此 ASIC 能耗比最高。相比前两者,GPU 和 CPU 屏蔽底层 IO,降低了数据的迁移和运算效率,能耗比较高。同时 GPU 的逻辑和缓存功能简单,以并行计算为主,因此 GPU能耗比又高于 CPU。
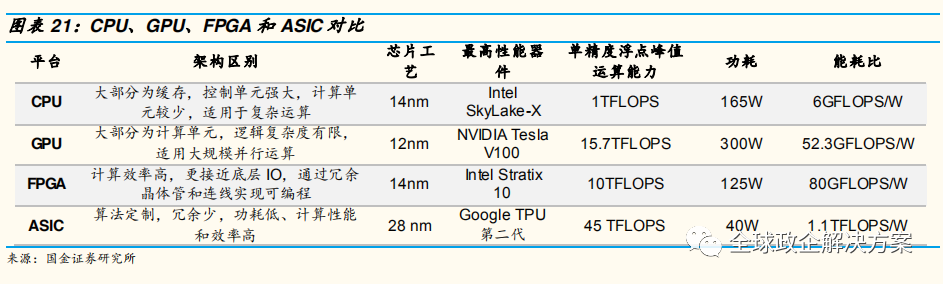
ASIC 是未来自动驾驶芯片的核心和趋势 。结合 ASIC 的优势,我们认为长远看自动驾驶的 AI 芯片会以 ASIC 为解决方案,主要有以下几个原因:

综上 ASIC 专用芯片几乎是自动驾驶量产芯片唯一的解决方案。由于这种芯片仅支持单一算法,对芯片设计者在算法、IC 设计上都提出很高要求。
以上并非下定论目前 ASIC 为核心的芯片一定比 GPU+FPGA 的芯片强,由于目前自动驾驶算法还在快速迭代和升级过程中,过早以固有算法生产ASIC 芯片长期来看不一定是最优选择。
Intel 在 ADAS 处理器上的布局已经完善,包括 Mobileye 的 ADAS 视觉处理,利用 Altera 的 FPGA 处理,以及英特尔自身的至强等型号的处理器,可以形成自动驾驶整个硬件超级中央控制的解决方案。
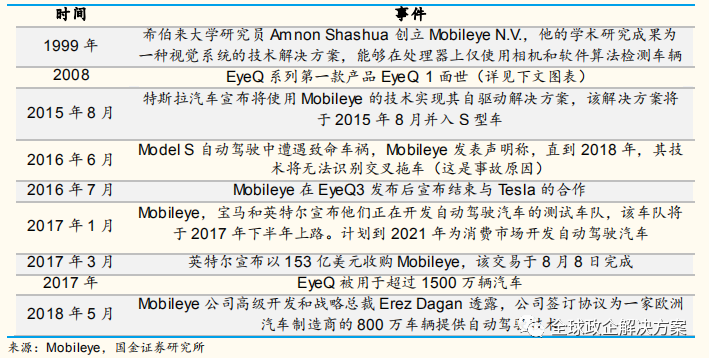
Mobileye 具有自主研发设计的芯片 EyeQ 系列,由意法半导体公司生产供应。现在已经量产的芯片型号有 EyeQ1 至 EyeQ4,EyeQ5 正在开发进行中,计划 2020 年面世,对标英伟达 Drive PX Xavier,并透露 EyeQ5 的计算性能达到了 24 TOPS,功耗为 10 瓦,芯片节能效率是 Drive Xavier 的2.4 倍。英特尔自动驾驶系统将采用摄像头为先的方法设计,搭载两块EyeQ5 系统芯片、一个英特尔凌动 C3xx4 处理器以及Mobileye 软件,大规模应用于可扩展的 L4/L5 自动驾驶汽车。该系列已被奥迪、宝马、菲亚特、福特、通用等多家汽车制造商使用。
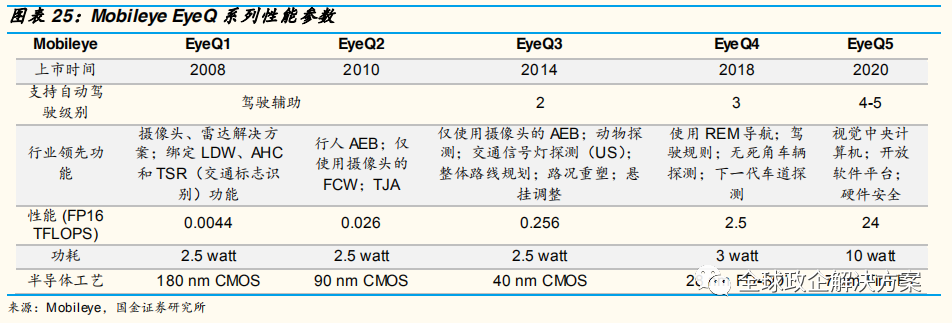
从硬件架构来看,该芯片包括了一组工业级四核 MIPS 处理器,以支持多线程技术能更好的进行数据的控制和管理。多个专用的向量微码处理器(VMP),用来应对 ADAS 相关的图像处理任务(如:缩放和预处理、翘曲、跟踪、车道标记检测、道路几何检测、滤波和直方图等,下图右上)。一颗军工级 MIPS Warrior CPU 位于次级传输管理中心,用于处理片内片外的通用数据。
此外通过行业访谈调研等途径了解到,Mobileye 在 L1-L3 智能驾驶领域具有极大的话语权,对 Tire1 和 OEM 非常强势,其算法和芯片绑定,不允许更改。
寒武纪科技在 2018 产品发布会上发布了多个 IP 产品——采用7nm 工艺的终端芯片 Cambricon 1M、云端智能芯片 MLU100 等。
其中寒武纪 1M 芯片是公司第三代 IP 产品,在 TSMC7nm 工艺下 8 位运算的效能比达 5Tops/w(每瓦 5 万亿次运算),同时提供 2Tops、4Tops、8Tops 三种尺寸的处理器内核,以满足不同需求。1M 还将支持 CNN、RNN、SVM、k-NN 等多种深度学习模型与机器学习算法的加速,能够完成视觉、语音、自然语言处理等任务。通过灵活配置 1M 处理器,可以实现多线和复杂自动驾驶任务的资源最大化利用。它还支持终端的训练,以此避免敏感数据的传输和实现更快的响应。
寒武纪首款云端智能芯片 Cambricon MLU100 同期发布,同时公布了在R-CNN算法下 MLU100 与英伟达 Tesla V100(2017)和英伟达 Tesla P4(2016)的对比,从参数上看,主要对标 Tesla P4。
地平线星云,基于征程 1.0 芯片,能够以车规级标准满足 L1 和 L2 级别的自动驾驶的需求, 能同时对行人、机动车、非机动车、车道线、交通标志牌、红绿灯等多类目标进行精准的实时监测与识别;并可满足车载设备严苛的环境要求,以及复杂环境下的视觉感知需求,支持L2 级别 ADAS 功能。
地平线 Matrix 1.0,内置地平线征程 2.0 处理器架构,最大化嵌入式 AI计算性能,是面向 L3/L4 的自动驾驶解决方案,可满足自动驾驶场景下高性能和低功耗的需求。依托地平线公司自主研发的工具链,开发者和研究人员可以基于 Matrix 平台部署神经网络模型,实现开发、验证、优化和部署。
Google TPU于 2016 年在 Google I/O上宣布,当时该公司表示 TPU已在其数据中心内使用了一年以上。该芯片专为 Google 的 Tensor Flow(一个符号数学库,用于神经网络等机器学习应用)框架而设计。

Google TPU 是专用的,并不面向市场,谷歌仅表示“将允许其他公司通过其云计算服务购买这些芯片。”今年 2 月,谷歌在其云平台博客上宣布的TPU 服务开放价格大约为每 cloud TPU (180TFLOPS 和 64 GB 内存)每小时 6.50 美元。Google 使用 TPU开发围棋系统 AlphaGo 和 Alpha Zero以及进行 Google 街景视频文字处理等,能够在不到五天的时间内找到街景数据库中的所有文字,此外 TPU也用于提供 Google 搜索结果的排序。
TPU与同期的 CPU和 GPU相比,可以提供 15-30 倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。
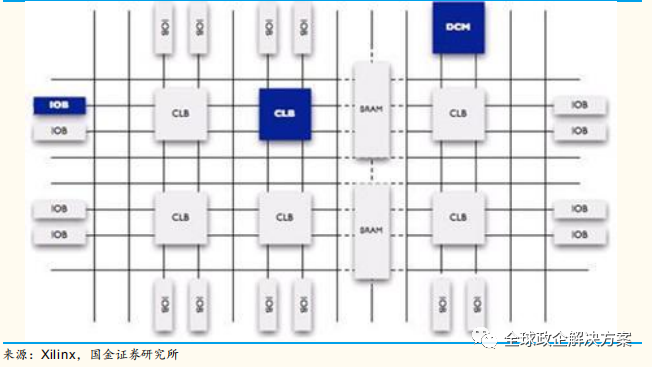
Xilinx 赛灵思是 FPGA 的先行者和领导者,1984 年,赛灵思发明了现场可编程门阵列 FPGA,作为半定制化的 ASIC,顺应了计算机需求更专业的趋势。FPGA 的好处是可编程以及带来的灵活配置,同时还可以提高整体系统性能,比单独开发芯片整个开发周期大为缩短,但缺点是价格、尺寸等因素。
在汽车 ADAS 和自动驾驶解决方案上,赛灵思的 FPGA 和 SOC 产品家族衍生出三个模块:自动驾驶中央控制器 Zynq UltraScale+ MPSoC,前置摄像头Zynq-7000 / Zynq UltraScale+ MPSoC、多传感器融合系统 Zynq UltraScale+ MPSoC。
Zynq 采用单一芯片即可完成 ADAS 解决方案的开发,SOC 平台大幅提升了性能,便于各种捆绑式应用,能实现不同产品系列间的可扩展性,可帮助系统厂商加快在环绕视觉、3D 环绕视觉、后视摄像头、动态校准、行人检测、后视车道偏离警告和盲区检测等 ADAS 应用的开发时间。并且可以让 OEM 和 Tier1 在平台上添加自己的 IP 以及赛灵思自己的扩展。
来源:全球政企解决方案
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
