
CAP只能三选二,可以选CA吗?
CAP理论在分布式系统领域非常重要,在我们做分布式系统的架构设计时会通过CAP原理验证方案的合理性。
CAP说的是在分布式系统下,存在三个要素:一致性、可用性、分区容错性。
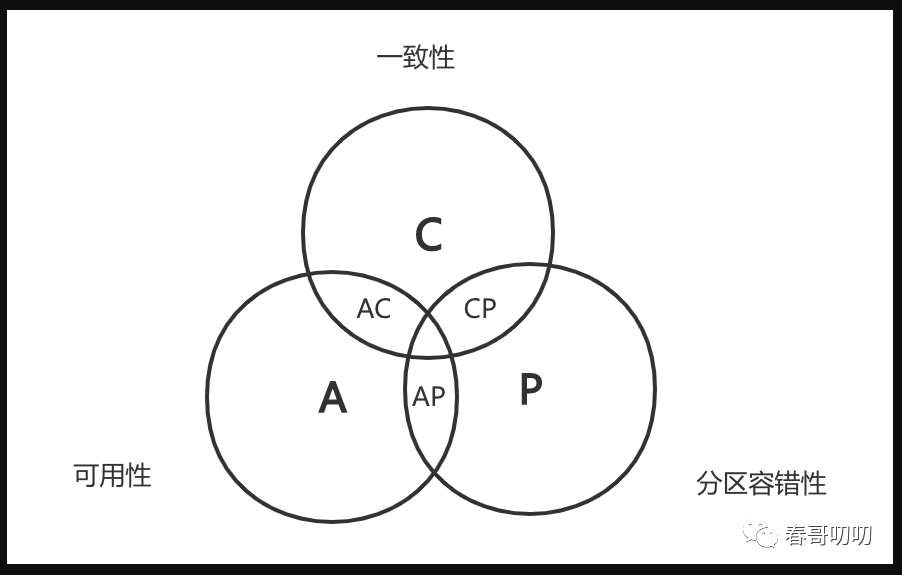
一致性:在分布式系统中,一份数据一般会存在多个副本,要求多个副本对数据的更新可以体现在所有副本上,也就是”强一致性“,不返回最新数据,就返回错误;
可用性:在分布式系统中,任一时刻,分布式系统都需要保证在限定延时内可以正常响应客户端读写,获取非错误的响应,但不能保证获得的是最新数据;
分区容错性:在分布式系统中,节点之间可能因为网络异常导致网络分区(丢包、延迟、中断等),需要保障在网络分区出现时,分布式系统不受影响;
CAP原理说在分布式系统下,只能满足其中两个特性,不能三者同时满足。
根据Cap定理的CA分布式系统是否存在?
答案:没有
关于分区容忍性。
第一版解释:出现消息丢失或分区错误时,系统能够继续运行;
第二版解释:当出现网络分区后,系统能够继续工作;
两版的区别是对分区的定义,不仅仅限定于消息丢失情况,可能是丢包、中断、拥塞等情况。
那有没有满足CA的系统呢?
有人说CA选型的系统是Oracle和MySQL,他们拥有强一致性和可用性,虽然Oracle RAC看似是分布式,但依然是通过共享存储实现的。MySQL主从则可以理解成多个单点的MySQL,通过Binlog实现数据同步到所有单点上。虽然看似实现了CA,但他们两者归根结底还是单点系统。
如果选择了CA放弃了P,那么当出现网络分区时,为了保障C那么就需要禁止写入,也就不能实现A了。
这里扩展下,我们所了解的一致性算法,包括2PC/3PC、Paxos、M/S,M/M 整个系统总是可以达到一致状态的,具体怎么达成一致,可能受时效性影响,也就是最终一致性还是强一致性。
由于分布式系统下,网络问题是不可避免的现象,不保证P很难叫分布式系统,P必然被实现,所以分布式系统一般都会在CP和AP上权衡。
选择CP的系统是什么逻辑?
CP系统意味着放弃了整体可用性,在分布式系统下,每个数据都是有副本的。
CP系统可以简单理解为副本数为1,客户端可以访问不同的副本进行数据读写,由于只有一个副本,不需要做副本之间数据同步,所以数据是强一致性的,也就满足了CP,一旦发生了网络分区问题,数据就会出现丢失或难以更新,会要求停止写,此时对客户端来说就不满足A了(读不到值、也写不进去了)。

选择AP的系统是什么逻辑?
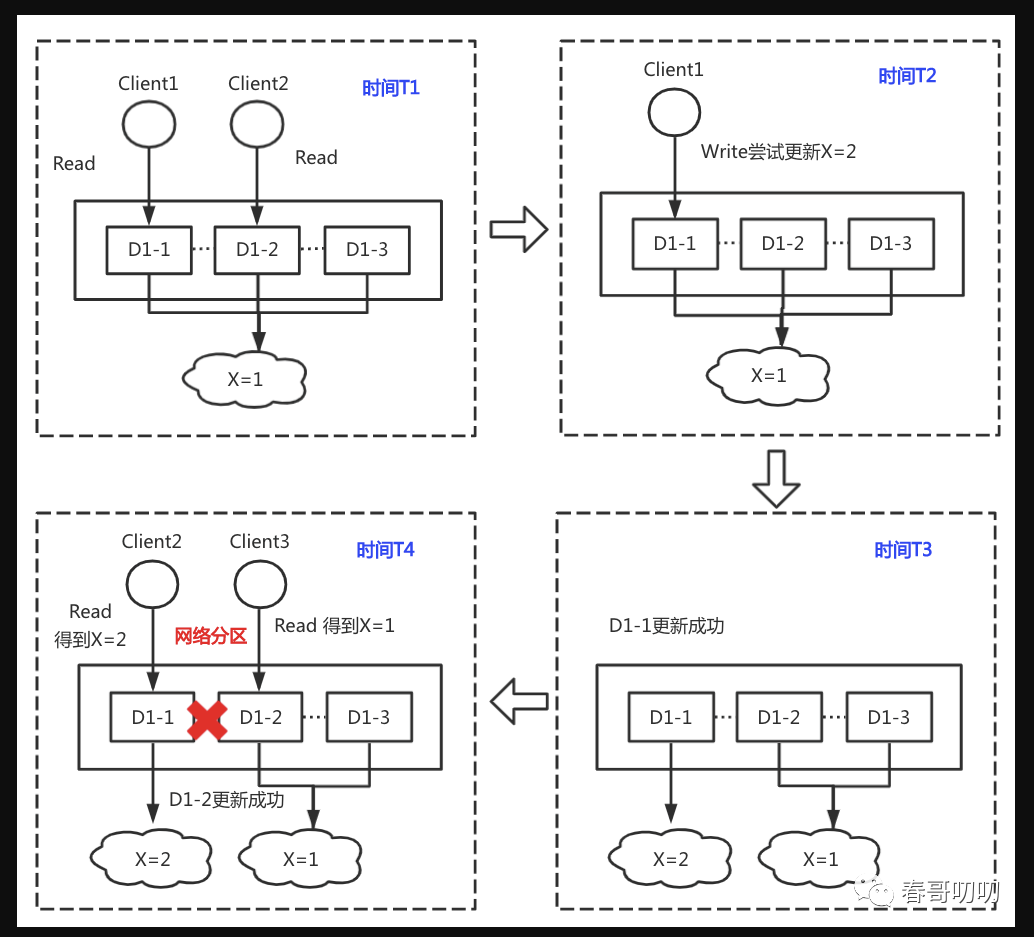
AP的系统一般要求数据具有多个副本,即使出现网络分区,也不会因为丢失数据或数据不一致导致不可用,但多个副本划分在不同网络分区,会出现副本之间数据不一致情况。
比如D1有三个副本,D1-1、D1-2、D1-3分布在不同节点上,正常情况下客户端写数据可以三个副本都复制成功,客户端读取任一副本可以得到最新更新的值;但当出现网络分区时,副本之间出现数据不可达,导致副本D1-3数据和另外两个副本不一致,这样不同客户端可以读取不同副本数据(或做故障转移),但不可以保障副本的一致性,就出现了一致性问题。
如何以CPA原理实现架构设计呢?
总的来说,在分布式系统下P是基础,需要在CA中找平衡,且这两者也不是百分百的。
比如虽然很多人认为单机系统是满足CA的,但是P不是简单的分布式网络上的节点,也有可能是多个协作的任务,任务之间是异步的,如果要求强一致性,那必然是同步的,但在数据未达成一致性时是不能对外提供服务的,也就不满足A了。
那么有没有100%的A呢?
要求任何情况下不出现问题其实是很难实现的,基本不存在,我们说的可用性是相对于容错性来说,容错率低、故障恢复时间快在某个领域下的一个可承受的阈值。
所以对于CAP理论的使用,不是简单的字面之间的权衡,非此即彼,而是要当做一种分布式系统设计的指导思想,需要更动态的看待自己的系统。
比如一个分布式系统是多服务、多模块的,涉及到计算服务与存储服务,在面对网络分区时,可以通过降级、预案等手段实现细粒度的A、C的取舍,而不是简单、整体的对外反映系统整体的服务、数据维度的响应结果。
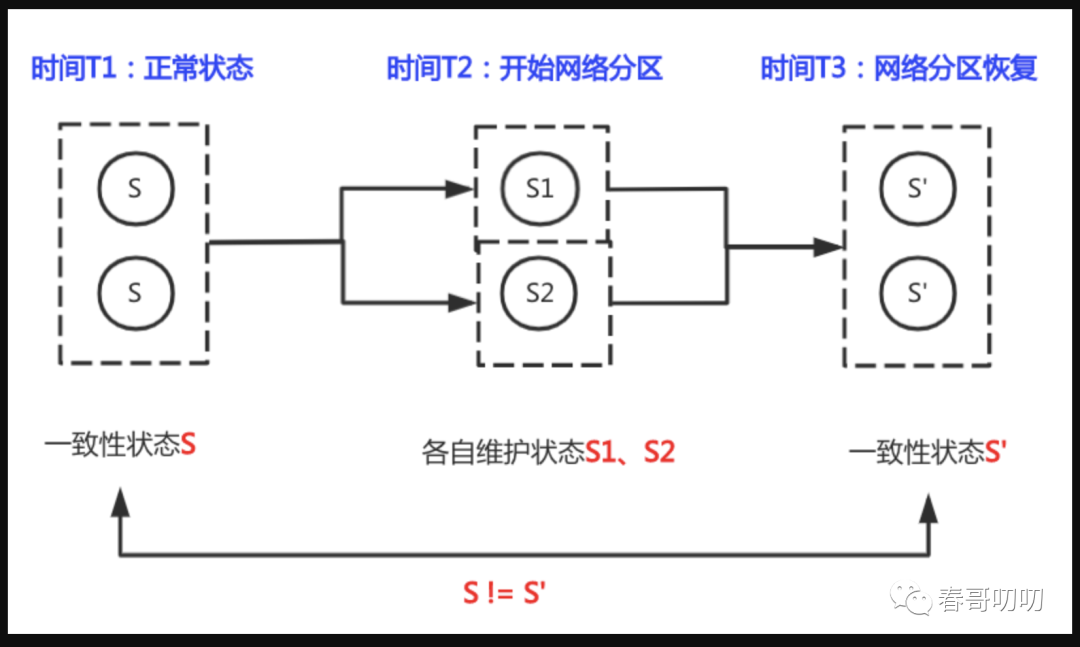
以中间件处理脑裂情况为例:
T1时刻,一切正常,两个节点都是S状态;
T2时刻,出现网络分区,导致两个节点状态出现S1、S2的分歧;
T3时刻,网络分区恢复,依据脑裂处理算法,两个节点达成最终状态S`;
正是因为CAP原理不能简单的适用于所有分布式系统场景,所以在分布式系统领域,还有其他一些理论做细化处理。
ACID
A:原子性,一个事务要么成功要么失败;
C:一致性,在事务开始前和事务结束后,数据满足一致性约束(这里是逻辑上的一致性,不是CAP里面的数据维度的一致性);
I:隔离性:如果多个事务同时发生,不应该互相影响;
D:持久性:当事务提交之后,对于整个系统来说,这次更新将是持久的;
ACID一般用在关系数据库的事务原则上。
BASE
BA:基本可用,分布式系统大部分时间是可用的,而不是百分百可用,允许偶尔的失败,相比于CAP的A来说,BA更符合真实场景;
S:软状态,分布式系统中的数据副本之间存在一个中间状态,也就是允许一部分数据副本是新的,一部分是老的,其实大部分中间件的副本都属于这种情况,副本之间存在延迟;
E:最终一致性,副本之间存在一致性延迟,但最终会变成数据一致的,这个往往是对外承诺的时间;
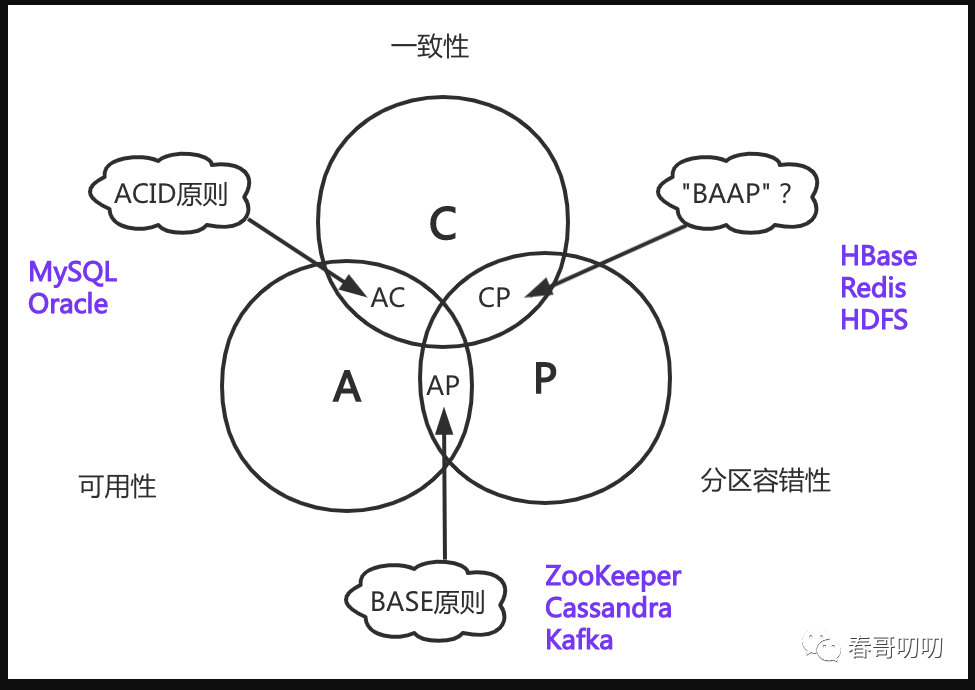
BASE和ACID可以认为是对于CAP的细化,让技术选型多了参考:
CA的选型一般对应ACID原则,针对于关系型数据库等;
AP的选型对应BASE原则,一般适用于存储型中间件,因为多副本是必须的,但副本同步是有延迟的,但最终会是数据一致的的;
CP的选型在分布式系统下暂时还没发现,正如上面说的,不会有人在分布式系统下只做一个副本吧,有人说Spanner是CP,可能仅仅是因为他的可用性太高,TiDB貌似也是CP系统,但感觉是一种障眼法,不让你读到错误的数据不就行了;