
误差最小0.1%!AI预测大选结果惊人,民调可以「下课」了

新智元报道
新智元报道
来源:VB
编辑:小匀、QJP
【新智元导读】美国大选尘埃落定,在回顾无数drama的竞选之路的同时,人们也发现,传统的民意查方法似乎变得「老套」了,一些科技公司表示,人工智能大有希望!算法可以捕捉到更广阔的选举动态图景,利用了twitter 和 Facebook 等信息,AI的预测似乎更为准确。
美国人讲不讲风水?
在各种比赛中,为了预测结果,什么「工具」都用上了。比如2010年世界杯时,章鱼哥因预测胜负频频得准火出了圈。
宁信章鱼也不信人的种子就这样埋下了。
本届美国大选也是,可能是由于民调的结果有过失误(当年希拉里民调领先,却输了大选),这次的大选,人们不再信人心,更加相信「科学」了。
比如,一个AI。
一家专门从事NLP的意大利软件公司Expert.ai,将其技术应用到数百万个社交帖子上,通过分析语气和情绪等因素,将这些数据转化为了选票。
另一家公司总部位于加州的Unanimous.ai公司销售所谓的「群体智能」软件。它使用人工智能模型来汇总群体的预测和决策。
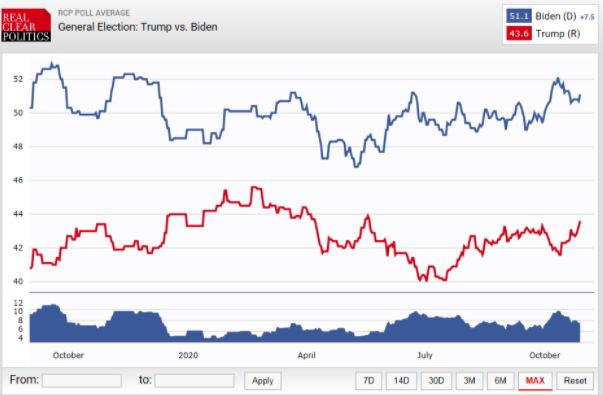
尽管方法略有不同,但他们的推论都是:拜登获胜。
历经无数big drama后,拜登终于在昨日凌晨突围,并修改自己的推特简历:美国当选总统。任凭川普再怎么不服输,任凭川普粉丝再怎么愤怒。
大势已定,AI预测普遍获胜。

如果「章鱼哥」没有英年早逝,它应该会吃惊地发现,自己的工作可以被AI替代。

民调不完美坑了谁?
民调并不是一门完美的科学。
2016年大选前的报道显示,希拉里·克林顿在全国范围内领先,在威斯康辛、密歇根和宾夕法尼亚等州势均力敌。但是,结果有些出乎意料——特朗普最终通过了赢得总统大选所需的270张选举人票。
美国民意研究协会的一份报告得出结论说,州级民调「低估了川普在中西部北部的支持率」。
换句话说,民调忽略了一些地区的数据,而这些,正是川普最终获胜的关键。

虽然此次的民调是拜登领先,与最终大选结果一致。但是否有比传统民调更准确的方法,来预测选举结果呢?
众所周知,民调主要依靠电话和在线小组调查,显然,这个范围会漏掉很多东西——现在的人们更倾向于在网上发泄情绪。
许多AI公司称,利用Twitter和Facebook消息等信号,算法可以更全面地描绘选举动态。
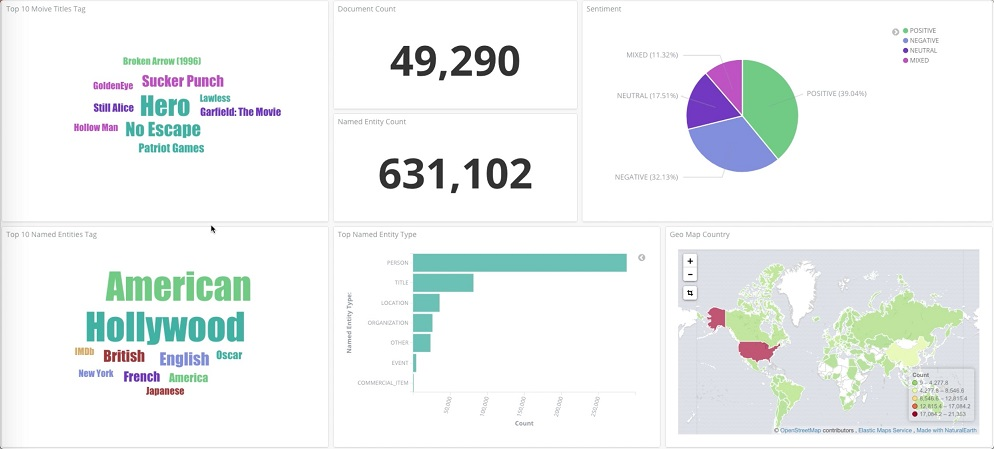
差距最小为0.1%!有的AI预测还真不是「江湖骗子」
此次大选期间利用AI预测的科技公司非常多,但他们都有一个共同点:在社交媒体数据上进行训练。
与投票一样,算法驱动的预测结果中的一些差异也可以归因于方法上的差异。
意大利的Expert.ai 利用一个知识图谱来进行命名实体识别(包括个人、公司和地点) ,并尝试建立它们之间的关系模型。
该公司表示,系统将84个情感标签对应到来自 Twitter 和其它网络来源的数十万条帖子上,同时半自动化的去除了僵尸账号。

Expert.ai 的算法对标签进行排名,取值从1到100不等,并将其乘以每个候选项出现的次数。与此同时,它将标签的情绪分为「积极的」或「消极的」,并利用这一点创建一个指数,可以比较两个候选项的区别。
根据自己的系统预测,民主党总统候选人拜登将赢得50.2% 的普选票,共和党总统特朗普将获得47.3% 的选票,领先2.9个百分点。
来对比下实际结果;拜登获得了50.7% 的普选选票,特朗普获得了47.7% 的选票,差距为3个百分点。
Expert.ai 的预测结果仅仅差距了0.1个百分点!
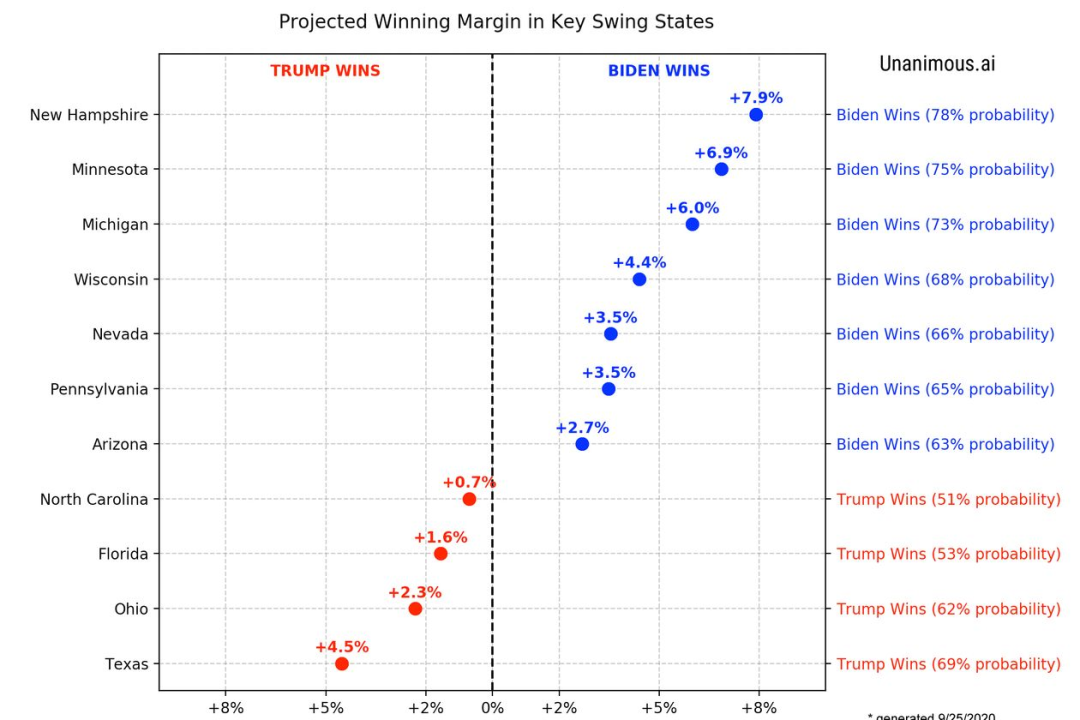
相比之下,KCore Analytics 公司声称它们已经使用了超过10亿条 tweets 数据来进行预测,它开发了一个端到端的框架来收集像 Twitter 这样的网络中的有影响力的人和标签。
数据是根据推文的内容和频率进行实时选择的,同时排除了机器人、AWS-LSTM 这样的模型产生的数据等,通过分析这些数据进行预测分类,声称准确率高达89.5% 。
至于Polly系统,它收集了一个随机的、受控的美国选民样本,这些选民是通过他们在社交媒体上的帖子和对话来确定的。在11月3日之前,这一数字为288,659人。
使用人工智能预测选举结果的其中一个挑战是:必须训练算法学习与国家预测相吻合的选举团的不同模型。
另一个挑战是,这些模型需要进行 fine-tune,以发现对特定少数群体和地区的重要的问题,群体越小,问题就越难找到。
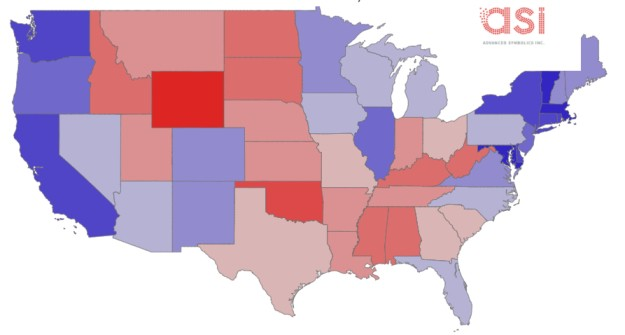
Polly基于对Twitter等社交媒体内容的消化,创建了一个包含288,588名选民的随机示例。
它也关注那些推动选民的问题,如COVID、选举的公正性、犯罪等。Polly根据模型预测拜登将赢得346张选举人票。
不过,根据 Advanced Symbolics(ASI)的说法,Polly 系统在这方面完全失败了——这个模型预测,佛罗里达州将投票给拜登,占该州总票数的52.6%。
原因很简单:古巴裔美国人通常投票给共和党候选人,但该系统没有对他们进行单独抽样,而却将他们归类为「西班牙裔」 ,与委内瑞拉裔和墨西哥裔美国人并列。
潜在影响因素也可能导致AI预测失误
除了这些,AI预测也有别的「门槛」。
例如,美国农村地区的投票结果就更难以用模型来解释。因为这些地区使用 Twitter 的选民比例较低,导致这些模型低估了支持拜登的选民的优势。

此外,Twitter 上的特朗普潜在支持者更少,因为这个社交网络往往更倾向于自由派。这意味着,特朗普的支持者的推文在基于社会的选举预测模型中的权重更大,但有时也不够大,就像Polly遇到的情况一样。
像 KCore Analytics 这样的公司表示,他们的人工智能模型要优于传统的民意调查,因为它们可以扩大潜在选民的群体,并根据抽样偏差(比如代表性不足的少数族裔)和其他限制调整预测结果。
任何数据以及最终对AI的挑战都是数据本身。
投票基于人的数据集。人们面临的挑战是,他们实际上是不可靠和不可预测的。当被问到诸如「您将投票给谁」和「您每周工作多少次」之类的问题时,他们也是不诚实的,会经常给出他们认为询问者想听到的答案。
AI预测要代替民调了吗?还差点意思!
基于民调,却胜于民调。

「它与传统投票和人工智能的主要区别在于,人工智能一直在变得越来越好。」
相比传统的民调,AI 预测系统两大优点不可忽视:
首先,能综合多元异构数据,社交网络和新闻媒体的数据多的不计其数,而且,AI还可以根据突发状况实时更新预测果。
这也是它的第二个优点。
同时,在搜集各家民调数据之后,AI预测更细粒度的精准数据,将预测的结果的准确性提升一个等级。
不过,对于AI来说,要想得到更准确的预测结果,需要更多元化的数据。
但是,在保隐私数据护严格的美国,想收集反映群体和个体行为的数据,是十分困难的。

