
大数据到底应该如何学?大数据生态圈技术组件解析

大数据文摘投稿作品
作者:小山猪的沙塔
这是一篇技术杂谈类的文章。
下面是食用须知:
本文适合还不十分了解大数据的你,同样适合不确定要不要学习大数据的你,将带你了解行业的需求以及与之相关的岗位,也同样适合刚刚踏入大数据领域工作的你,欢迎收藏并将文章分享给身边的朋友。 笔者从事大数据开发和培训多年,曾为多家机构优化完整大数据课程体系,也为多所高校设计并实施大数据专业培养方案,并进行过多次大数据师资培训、高校骨干教师学习交流,希望自己的一点粗浅认识能够帮助到大家。 本文并不是要将大数据描述成一个万能的、可以解决所有问题的东西,而是客观的阐述其作用,能够解决的一些问题。希望将这一领域尽可能完整的介绍给你,至于如何选择需要根据自己的实际情况来决定。
大数据的基本概念
什么是大数据
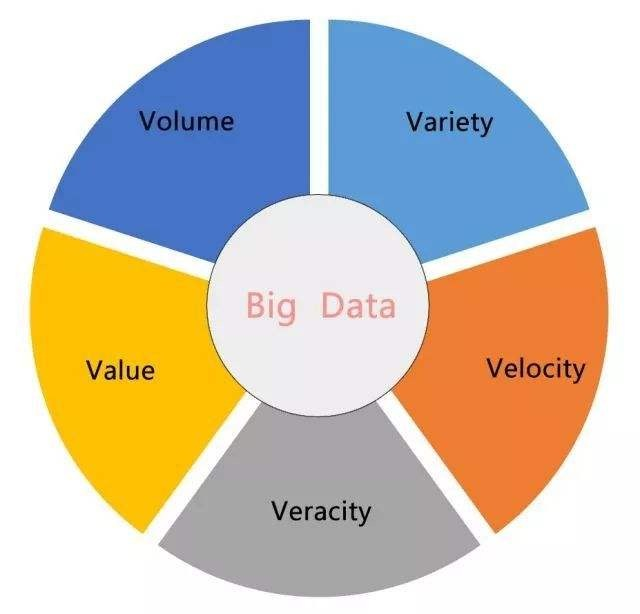
数据是如何采集的
对于用户行为数据更多的来自于应用埋点和捕获,因为用户使用应用必须通过鼠标点击或者手指触碰来和用户界面进行交互。以网页应用(网站)为例,对于鼠标的所有行为基本上都可以通过事件监听的方式来捕获,鼠标在某个区域停留的时间、是否进行点击,我们甚至可以根据用户的行为数据刻画出整个页面的热力图。
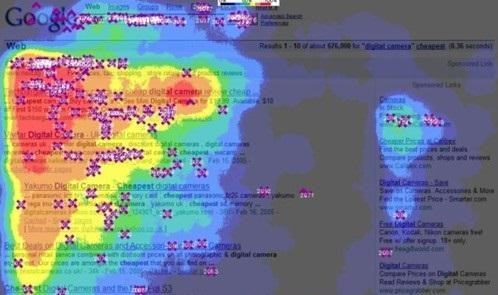
在不同的应用场景中,我们可以对行为类型、功能模块、用户信息等维度进一步的划分,做更加深入的分析。
对于非机构化的数据指的就是除结构化数据以外的另一大类数据,通常没有预期的数据机构,存储在非关系型数据库中,如:Redis、MongoDB,使用NoSQL来进行操作。也可能是非文本类型的数据,需要特别对应的手段来处理和分析。
大数据真的能预测吗
但是我们可以明确的一点是,大数据的预测也好、推荐也好,都是基于算法的,是数学的,也是科学的,但并不会百分之百的准确。
什么是大数据开发



如果是分析公司自身的业务数据,一般会更偏重于使用大数据组件和算法库,构建出一个可行的数据分析方案。大家可以看出,现在完全不涉及算法的大数据岗位已经比较少了。这里的算法指的并不是数据结构,而是指机器学习库,与数据挖掘相关的算法,至少要知道如何控制算法的输入与输出,算法能够解决的问题,可能不会涉及到亲自建模,在大数据分析的小节中会详细介绍。

操作系统:Linux(基本操作、软件维护、权限管理、定时任务、简单Shell等) 编程语言:Java(主要)、Scala、Python等 数据采集组件及中间件:Flume、Sqoop、Kafka、Logstash、Splunk等 大数据集群核心组件:Hadoop、Hive、Impala、HBase、Spark(Core、SQL、Streaming、MLlib)、Flink、Zookeeper等 素养要求:计算机或大数据相关专业
什么是大数据分析



编程语言:Python、R、SQL等 建模工具:MATLAB、Mathematica等 熟悉机器学习库及数据挖掘经典算法 数学、统计学、计算机相关专业,对数据敏感
应如何学习大数据
涉及到了这么多的技术点,如何学习才更加高效呢?首先好入门的自然是大数据开发,对于Linux的操作系统和编程语言的部分没什么过多说明的,不要觉得有些东西没用就跳过,有些时候编程思想和解决问题的方法同样很重要,课本上有的一定要扎实。对于和大数据相关的组件,看上去十分的繁杂,很多小伙伴可能都是钻研于每个组件的用法、算子、函数、API,这当然没有错,但是同时一定不要忘记埋在其中的主线,那就是:完整的数据分析流程。在学习的过程中一定要了解各组件的特点、区别和应用的数据场景。
数据源:数据文件、数据库中的数据等
数据采集:Sqoop、HDFS数据上传、Hive数据导入等
数据存储:HDFS
数据分析:MapReduce、Hive QL
计算结果:Hive结果表(HiveJDBC查询)、导出至关系型数据库
实时计算
数据源:日志文件增量监听等 数据采集:Flume 中间件:Kafka 数据分析:Spark-Streaming,Flink等 计算结果:HBase
作者介绍:资深开发者,全栈开发工程师,大数据高级开发工程师。具有多年开发及培训经验,实施过多次面向学生、企业、高校骨干教师等各种形式的培训。
个人主页:
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn
评论