
网络爬虫(一)
《Python学习》专栏·第2篇
文 | 段洵
1099字 | 5 分钟阅读
【数据科学与人工智能】已开通Python语言社群,学用Python,玩弄数据,求解问题,以创价值。喜乐入群者,请加微信号shushengya360,或扫描文末二维码,添加为好友,同时附上Python-入群。有朋自远方来,不亦乐乎,并诚邀入群,以达相互学习和进步之美好心愿。
一、网络爬虫:需要安装的包
• requests:HTTP请求库
Python实现的一个简单易用的HTTP库,支持HTTP持久连接和连接池、SSL证书验证、cookies处理、流式上传等,向服务器发起请求并获取响应,完成访问网页的步骤,简洁、容易理解,是最友好的网络爬虫库。
http请求类型
requests.request():构造一个请求
requests.get():获取HTML网页
requests.head():获取HTML网页头信息
requests.post():提交POST请求
requests.put():提交PUT请求
requests.patch():提交局部修改请求
requests.delete():提交删除请求
requests.options():获取http请求
返回的是一个response对象,response对象包含服务器返回的所有信息,例如状态码、编码形式、文本内容等;也包含请求的request信息 .status_code:HTTP请求的返回状态 .text:HTTP响应内容的字符串形式 .content:HTTP响应内容的二进制形式 .encoding:(从HTTP header中)分析响应内容的编码方式 .apparent_encoding:(从内容中)分析响应内容的编码方式。

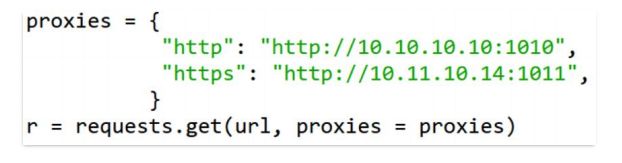
定制请求头。requests的请求接口有一个名为headers的参数,向它传递一个字典来完成请求头定制。设置代理。一些网站设置了同一IP访问次数的限制,可以在发送请求时指定proxies参数来替换代理,解决这一问题。
• beautifulsoup4:HTML文档分析库
页面解析器:使用requests库下载了网页并转换成字符串后,需要一个解析器来处理HTML和XML,解析页面格式,提取有用的信息。
解析器类型

搜索方法:find_all(name, attrs, recursive, string,**kwargs),返回文档中符合条件的所有tag,是一个列表。find(name, attrs, recursive, string,**kwargs) ,相当于find_all()中limit = 1,返回一个结果。name:对标签名称的检索字符串。attrs: 对标签属性值的检索字符串。recursive: 是否对子节点全部检索,默认为True。string: <>... 中检索字符串。**kwargs:关键词参数列表。
• lxml:页面解析器
二、爬虫的基本流程
分析网页结构
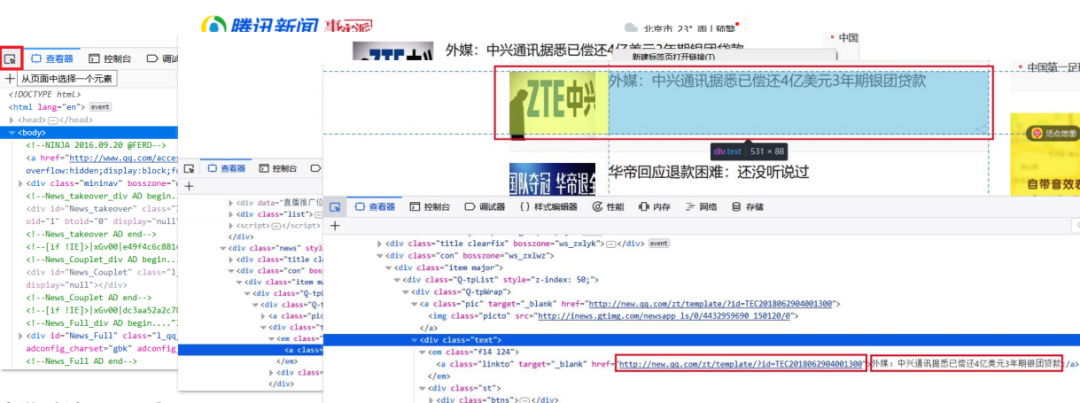
爬取页面:通过requests库向目标站点发送请求,若对方服务器正常响应,能够收到一个response对象,它包含了服务器返回的所有信息。

解析页面:HTML代码-网页解析器,此处使用bs4进行解析。


推荐阅读:图像处理
公众号推荐
数据思践
数据思践公众号记录和分享数据人思考和践行的内容与故事。
Python语言群
诚邀您加入
请扫下方二维码加我为好友,备注Python-入群。有朋自远方来,不亦乐乎,并诚邀入群,以达相互学习和进步之美好心愿。