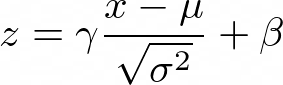(给机器学习算法与Python实战加星标,提升AI技能)

在这篇文章中,为了你的阅读乐趣,我列出了今年阅读人工智能论文的十条建议(以及其他一些进一步的阅读建议)。
在这个列表中,我主要关注那些在不提出新架构的情况下推动最新技术的文章,这些文章不包含最新的YOLO或ResNet变体;相反,主要包括了损失公式、理论突破、新优化器等方面的最新进展。对于文章的前半部分,我将重点介绍计算机视觉和NLP,因为这些是我最熟悉的主题,并从一两个经典技术开始。对于每一篇论文,我都会总结其主要贡献,并列出阅读理由。最后,我在每一篇文章的结尾都给出了关于这个主题的具体阅读建议,并将其与其他最新进展或类似想法联系起来。1.GloVe (2014)
Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. “Glove: Global vectors for word representation.” 2014年自然语言处理方法会议(EMNLP)论文集。- 论文链接:https://www.aclweb.org/anthology/D14-1162.pdf
虽然现在的社区主要关注神经网络,但许多早期的结果是通过更简单的数学方法获得的。GloVe是从经典算法出发的,它是基于减少单词共现矩阵维数的单词嵌入模型。与以前的方法不同,GloVe使用隐式表示法,使其可以扩展为大规模文本语料库。理由1:如果你从自然语言处理(NLP)入手,这是一本很好的读物,可以帮助你了解单词嵌入的基本知识以及它们的重要性。理由2:以前并不是所有的东西都是基于Transformers的,阅读早期的作品是一个很好的方法去找到一个“被遗忘的想法”,该想法可以使现有技术进一步发展。- Transformers:http://papers.nips.cc/paper/7181-attention-is-all-you-need
理由3:许多作者在后来扩展了本文中提出的许多概念。如今,词嵌入已成为自然语言处理(NLP)中的主要内容进一步阅读:在同一时期,Google发布了Word2Vec,另一个著名的语义向量生成模型。不久之后,这些想法被生物学界采纳,作为表示大蛋白和基因序列的方法。而现在BERT是词汇表征和语义理解的主导方法。- Word2Vec:https://arxiv.org/abs/1301.3781
- BERT:https://arxiv.org/abs/1810.04805
2.AdaBoost (1997)
Freund, Yoav; Schapire, Robert E (1997). “A decision-theoretic generalization of on-line learning and an application to boosting”.- 论文链接:https://www.sciencedirect.com/science/article/pii/S002200009791504X
经典的机器学习模式根本就不灵活,大多数公式都有显著的局限性,这使得它们无法扩展到越来越复杂的任务中。首先解决这个问题的办法之一是将现有的最佳模式进行投票整合。1997年,Freund和Schapire提出了AdaBoost算法,这是一种元启发式学习算法,能够将许多“弱”模型运用到“强”分类器中。简而言之,该算法迭代地训练多个分类器,并将每个训练样本重新加权为“简单”或“困难”,随着训练的进行,这套系统会通过更多地关注较难分类的样本来进化。该算法非常有效,但是遇到复杂的问题也很容易过度拟合。理由1:可以说,神经网络是弱分类器(神经元/层)的集合,然而神经网络文献的发展是独立于整体的。读一篇关于这个主题的论文可能会对为什么神经网络工作得这么好产生一些见解。理由2:许多新手把传统的机器学习方法视为过时和“软弱”的,在几乎所有事情上都偏爱神经网络。AdaBoost是一个很好的例子,说明经典的机器学习并不是很弱,而且与神经网络不同的是,这些模型具有很强的可解释性。理由3:有多少报纸是从一个赌徒的故事开始的,他因为一次又一次输给朋友的骑马赌博而受挫?我也真希望我敢写这样的论文。进一步阅读:其他流行的集成方法包括随机森林分类器、梯度提升技术和广受好评的XGBoost软件包,它以赢得数次机器学习竞赛而闻名,同时相对容易使用和调整。这个家族中最新加入的是微软的LightGBM,它适用于大规模分布的数据集。- 随机森林分类器:https://en.wikipedia.org/wiki/Random_forest
- 梯度提升技术:https://en.wikipedia.org/wiki/Gradient_boosting
- XGBoost软件包:https://github.com/dmlc/xgboost
- LightGBM:https://github.com/microsoft/LightGBM
3.Capsule Networks (2017)
Sabour, Sara, Nicholas Frosst, and Geoffrey E. Hinton. “Dynamic routing between capsules.” 神经信息处理系统的研究进展。- 论文链接:https://arxiv.org/abs/1710.09829
神经网络文献从感知器模型开始,到卷积神经网络(CNN)。下一个飞跃是一个备受争议的话题,其中建议之一就是由Sara Sabour,Nicholas Frosst和图灵奖获得者Geoffrey Hinton提出的Capsule Network。理解胶囊网络的一个简单方法是用“胶囊”代替“目标检测器”。每层“目标检测器”都试图识别图像中的相关特征,以及它的姿态(方向、比例、倾斜等),通过叠加探测器,可以导出物体的鲁棒表示。从本质上讲,胶囊并不像cnn那样将本地信息聚合到高级功能中,取而代之的是,它们检测目标部分并按层次组合它们以识别更大的结构和关系。理由1:作为科学家,我们都应该寻找下一个重大事件。虽然我们不能说胶囊网络将是下一个摇滚明星,但我们可以说他们试图解决的问题是相关的,并且对于所有相关问题,最终会有人回答。理由2:本文提醒我们CNN并不完美,它们对旋转和缩放不变。尽管我们使用数据增强来缓解这种情况,但俗话说,没有一种创可贴能治愈一个男人。理由3:在深度学习成为主流之前,许多目标检测方法都依赖于识别易于发现的“目标部分”并针对数据库/本体执行模式匹配。Hinton和他的团队正在做的是使这种早期方法现代化,这就是为什么我们都应该不定期阅读经典。进一步阅读:在过去的一年中,Attention机制引起了很大注意,尽管它没有尝试替代或增加卷积,但确实为全局推理提供了一条途径,这是现代网络中众多Aquiles脚跟之一。4.Relational Inductive Biases (2018)
Battaglia, Peter W., et al. “Relational inductive biases, deep learning, and graph networks.” arXiv preprint arXiv:1806.01261 (2018).- 论文链接:https://arxiv.org/pdf/1806.01261.pdf
这篇文章总结了深层思维团队相信的深度学习下一个重要技术:图神经网络(GNNs)。(…)。我们认为,组合泛化必须是人工智能实现类人能力的首要任务,结构化表示和计算是实现这一目标的关键。正如生物学合作使用自然和培养一样,我们反对在“手工工程”和“端到端”学习之间的错误选择,而是提倡一种从两者互补优势中获益的方法。我们将探讨如何在深度学习架构中使用关系归纳偏差来促进对实体、关系和组合规则的学习。旁注:归纳偏差是学习算法对数据所做的所有假设。例如,线性模型假设数据是线性的。如果一个模型假设数据有一个特定的关系,它就有一个关系归纳偏差。因此,图是一种有用的表示。理由1:目前的CNN模型是“端到端”的,这意味着它们使用的是原始的,大部分是未经处理的数据。特征不是由人类“设计”的,而是由算法自动“学习”的。我们大多数人都被教导特征学习会更好。在本文中,作者提出了相反的观点。理由2:早期的人工智能文献大多与计算推理有关,然而计算直觉占了上风。NN不会对输入进行仔细考虑;它们会产生一种相当精确的数学“预感”。图形可能是一种将这种差距与直觉推理联系起来的方法。理由3:组合问题可以说是计算机科学中最关键的问题,大多数都处于我们认为可处理或可能的边缘。然而,我们人类可以自然地、毫不费力地推理。图神经网络是答案吗?进一步阅读:GNNs是一个令人兴奋和不断发展的领域。从图论中,我们知道几乎任何事物都可以被建模为一个图。谢尔盖·伊万诺夫(Sergei Ivanov)在2020年ICLR会议上发表了大量参考文献,列出了GNN的新趋势。- 2020年图机学习的主要趋势:https://towardsdatascience.com/top-trends-of-graph-machine-learning-in-2020-1194175351a3
5.Training Batch Norm and Only BatchNorm (2020)
Frankle, Jonathan, David J. Schwab, and Ari S. Morcos. “Training BatchNorm and Only BatchNorm: On the Expressive Power of Random Features in CNNs.” arXiv preprint arXiv:2003.00152 (2020).- 论文链接:https://arxiv.org/abs/2003.00152
你相信在CIFAR-10上,仅ResNet-151的批处理标准化层就可以达到+60%的精确度吗?换句话说,如果你将所有其他层锁定在它们的随机初始权值,并训练网络50个左右的周期,它的性能将比随机的好。我不得不把这篇论文复制出来亲眼看看,“魔力”来自于经常被遗忘的批次范数的γ和β参数:批处理标准化操作的完整定义。γ和β是两个可学习的参数,可在标准化发生后允许图层缩放和移动每个激活图。理由1:这是一个疯狂的想法,值得一读。开箱即用的想法总是受欢迎的。理由2:你可能会问自己批归一化层如何学习,并且你可能会想知道为什么有人会关心这一点。对于数据科学中的许多事情,我们认为批归一化是理所当然的,我们相信这只会加速训练。但是,它可以做得更多。理由3:这篇文章可能会激起你的兴趣,让你看看所有的公共层都有哪些参数和超参数。进一步阅读:大多数课程教导批归一化层是针对所谓的内部协方差转移问题。最近的证据表明情况并非如此(https://arxiv.org/abs/1805.11604),相反,作者认为BN层使整体损失情况更为平滑。另一个巧妙的想法是彩票假说,它也是由弗兰克尔等人提出的。- 彩票假说:https://arxiv.org/abs/1803.03635
6.Spectral Norm (2018)
Miyato, Takeru, et al. “Spectral normalization for generative adversarial networks.” arXiv preprint arXiv:1802.05957 (2018).- 论文链接:https://arxiv.org/abs/1802.05957
在GAN文献中,Wasserstein损失改善了训练GANs的几个关键挑战,然而它规定梯度必须有一个小于或等于1的范数(1-Lipschitz)。损失的最初作者建议将权重裁剪为[-0.01,0.01],以此来增强小梯度。作为响应,也有人提出了更干净的解决方案,使用频谱范数作为约束权重矩阵以生成最多单位梯度的平滑替代方法。- Wasserstein损失:https://arxiv.org/abs/1701.07875
理由1:标准化是一个比较大的话题,许多特殊属性可以通过专门的标准化和精心设计的激活函数来实现。理由2:除了作为一个标准,它也是一个正则化,这是神经网络设计中经常被忽视的话题。除了dropout,读一篇关于该问题的成功论文让人耳目一新。- dropout:https://en.wikipedia.org/wiki/Dropout_(neural_networks)
进一步阅读:标准化技术的其他最新进展是组标准化和自适应实例标准化技术,前者以小批量解决了批量范数的一些缺点,而后者则是任意风格转换的关键突破之一。7.Perceptual Losses (2016)
Johnson, Justin, Alexandre Alahi, and Li Fei-Fei. “Perceptual losses for real-time style transfer and super-resolution.” 欧洲计算机视觉会议. Springer, Cham, 2016.大多数神经网络背后的驱动力是损失函数。在描述什么是好的和什么是坏的损失函数越是成功,我们就越快收敛到有用的模型中。在文献中,大多数损失相对简单,只能测量低水平的属性。除此之外,获取高级语义也是出了名的棘手。Perceptual Losses论文认为,可以使用预先训练的网络来度量语义相似度,而不是手工设计复杂的损失函数。在实践中,生成值和真实值的结果通过预先训练的VGG网络传递,并比较特定层的激活情况。相似图像应该有相似的激活。早期图层捕捉广泛的特征,而后期图层捕捉更多细微的细节。理由1:损失是生成优秀模型最重要的方面之一。没有一个合适的反馈信号,任何优化过程都不会收敛。这就是一个好老师的角色:给予反馈。理由2:成功的损失往往具有里程碑意义。在感知损失被发明之后,GANs所获得了品质的跃升。理解这部作品对于理解大部分后期技术是必不可少的。理由3:这些神经损失既神秘又有用。虽然作者对这些模型的工作原理提供了合理的解释,但它们的许多方面仍然是开放的,就像神经网络中的大多数东西一样。进一步阅读:神经网络的一个迷人的方面是它们的可组合性。本文利用神经网络来解决神经网络问题。拓扑损失理论将这种思想推广到图像分割问题中。神经结构搜索(NAS)文献使用神经网络来寻找新的神经网络。至于计算机视觉的其他损失,这里有一个全面的指南。感谢Sowmya Yellapragada整理了这个强大的清单:- https://medium.com/ml-cheat-sheet/winning-at-loss-functions-2-important-loss-functions-in-computer-vision-b2b9d293e15a
8.Nadam (2016)
Dozat, Timothy. “Incorporating nesterov momentum into adam.” (2016).我们大多数人都熟悉SGD、Adam和RMSprop等术语,有些人还知道一些不太熟悉的名字,如AdaGrad、AdaDelta和AdaMax,但是很少有人花一些时间来理解这些名称的含义以及为什么Adam是当今的默认选择。Tensorflow捆绑了Nadam,它改进了Adam,但是大多数用户并不知道。理由1:本论文对大多数神经网络优化器进行了全面而直接的解释。每一种方法都是对其他方法的直接改进。很少有论文能在两页半的篇幅里涵盖如此重数学的知识。理由2:我们都认为优化器是理所当然的,了解它们的基本原理对改进神经网络非常有用,这就是为什么我们在RMSprop不收敛时用Adam替换它,或者用SGD替换它。进一步阅读:自2016年以来,已经提出了许多对优化器的其他改进,有些将在某个时候合并到主流库中。看看 Radam, Lookahead,和Ranger 的一些新想法。- Radam:https://arxiv.org/abs/1908.03265v1
- Lookahead:https://arxiv.org/abs/1907.08610
- Ranger:https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
9.The Double Descent Hypothesis (2019)
Nakkiran, Preetum, et al. “Deep double descent: Where bigger models and more data hurt.” arXiv preprint arXiv:1912.02292 (2019).传统的观点认为小模型欠拟合,大模型过拟合,然而,在彩虹之上的某个地方,更大的模型仍然闪耀着光芒。本文中,Nakkiran等人有证据表明,随着尺寸的增长,一些模型表现出“双下降”现象,测试精度下降,然后上升,然后再次下降。此外,他们认为拐点是在“插值阈值”:一个模型足够大来插值数据的点,换句话说,当一个模型的训练超出了该领域的建议,它就会开始改进。理由1:大多数课程都教授偏差/方差权衡,显然,该原则仅在一定程度上适用——需要时间来复习基础知识。理由2:如果增加的周期数也越过了插值点,我们都应该尽早放弃,看看会发生什么。总的来说,我们都可以做科学的分析。理由3:这和5很好地提醒了我们还有很多我们不知道的地方。并非我们所学的一切都是正确的,并且并非所有直观的知识都是正确的。进一步阅读:一个更轻松的阅读是图像分类的“技巧包”。在这本书中,你将找到几个简单且可操作的建议,用于从模型中提取额外的性能下降元素。- 图像分类的“技巧包”:https://arxiv.org/abs/1812.01187
10.On The Measure of Intelligence (2019)
François, Chollet. “On the Measure of Intelligence.” arXiv preprint arXiv:1911.01547 (2019).- https://arxiv.org/abs/1911.01547
大多数人都在努力多走一英里,弗朗索瓦·乔利特正在向月球射击。在这个列表中,所有提到的文章都进一步推动了实践和理论的发展。一些技术已经被广泛采用,而另一些则为融合提供了良好的改进,然而,比肩人类智力,仍然是一个神秘而难以捉摸的话题,更不用说奥秘或神秘了。时至今日,人工智能领域朝着通用智能方向的进步还只是用“成就”来衡量。每隔一段时间,一种算法在复杂的任务中击败了人类,比如国际象棋、dota2或围棋。每当这种情况发生时,我们都说我们又近了一步?. 然而,这还不足以衡量智力的技能习得效率。在这篇(长篇)文章中,Chollet认为:“要想朝着更智能、更人性化的人工系统迈进,我们需要遵循适当的反馈信号。”换句话说,我们需要一个合适的机器智能基准,一种智商测试。因此,作者提出了抽象推理语料库(ARC)。ARC可以被看作是一个通用的人工智能基准,一个程序综合基准,或者一个心理测量智能测试。它的目标是人类和人工智能系统,这些系统旨在模拟人类一般流体智能的形式。”理由1:虽然数据科学很酷很时髦,但人工智能才是真正的核心。如果没有人工智能,就不会有数据科学。它的最终目标不是寻找数据洞察力,而是构建可以拥有自己想法的机器。花些时间思考以下基本问题:什么是智力,我们如何衡量?本文是一个好的开始。理由2:在过去的几十年里,IA社区被来自数理逻辑和演绎推理的思想所支配,但是支持向量机和神经网络在没有任何形式的显式推理的情况下,比基于逻辑的方法更先进。ARC是否会引发经典技术的复兴?理由3:如果Chollet是正确的,我们离创建能够求解ARC数据集的算法还有几年的时间。如果你正在寻找一个可以在业余时间使用的数据集,这里有一个可以让你保持忙碌的数据集:进一步阅读:2018年,Geoffrey Hinton、Yosha Bengio和Yan LeCun因其在深度学习基础上的先驱工作而获得图灵奖。今年,在AAAI会议上,他们就人工智能的未来发表了自己的看法。你可以在Youtube上观看:- https://youtu.be/UX8OubxsY8w
我想用杰弗里·辛顿的一句话来结束这篇文章,我相信这句话概括了这一切:“未来取决于某个研究生,他对我所说的一切都深表怀疑。”GloVe通过隐式完成了共现矩阵。AdaBoost使数百个弱分类器成为最新技术。胶囊网络挑战了CNN,而图神经网络可能会取代它们。关键的进步可能来自归一化,损失和优化器,而我们仍然有空间质疑批处理规范和训练过度参数化的模型。我想知道还有多少关于dropout和ReLU的事情需要去发现。参考链接:https://towardsdatascience.com/ten-more-ai-papers-to-read-in-2020-8c6fb4650a9b
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「hych666」,欢迎添加我的微信,更多精彩,尽在我的朋友圈。老铁,三连支持一下,好吗?↓↓↓