
阿里数据专家:如何有规范+规划的进行数据埋点?
本文是前阿里巴巴数据分析专家-张腾在infoQ 账号 analysis-lion
发布的一篇原创文章
https://xie.infoq.cn/article/661e01f560c13b028b3e1567a
序
说起数据埋点,对于大多数的数据分析师来说并不陌生,并且可能在很多人的认知中,埋点的工作是由产品经理来完成的。那么为什么笔者认为数据埋点是分析师成长体系中的一环呢?其核心在于埋点的规范与规划。在笔者任职的多家企业中,通常产品经理设计埋点是仅考虑自己所负责的模块,那么会出现一个常见的问题--数据链路断裂,在一些前后端跨模块统计时数据无法有效追踪或者关联。那么作为分析师,尤其是中台的分析师,自身存在一定的优势,承接业务、产品的需求,对接前后端数据,可以从总体去规划和规范埋点方案,从而降低埋点成本,减少数据链路断裂等问题。
Starting~
什么是埋点?
埋点是数据采集的重要方式之一,通过在 app/H5/pc 等终端部署采集 SDK 代码,来记录和收集用户的行为数据,比如进入页面、点击按钮等,之后数据会被收集并传输到服务器存储。下图为一个较常见的数据流处理流程。

埋点的分类
笔者的经验,埋点其实可以分为客户端(前端)埋点和服务端(后端)埋点,可能一些小伙伴对前后概念不是很清楚,这里简单概括一下,客户端就是用户端,就是使用服务,而服务端则是为用户端提供服务。客户端埋点和服务端埋点核心都是为了采集数据,但是相较于客户端埋点,服务端的本质决定了其能够实时采集数据,不存在延迟上报,数据更准确;同时服务端埋点支持与用户身份信息和行为附带属性信息整合;并且服务端埋点更新时不需要随发版才生效。
不过需要注意的是,大多情况埋点时不会将服务端埋点独立出来,而是混合在客户端中,等用户端和服务器的交互返回结果之后,将结果进行上报。

埋点的技术方案
埋点的技术方案目前来看基本可以分为三大类:代码埋点、可视化埋点、无埋点(也成为全埋点),其中代码埋点是目前的主流埋点技术方案。
代码埋点
代码埋点实际上就是将采集的 SDK 集成在终端,用户在使用客户端时,只要触发了需要统计的事件,SDK 就会将数据传到后端服务器上。
优势:自定义属性、行为,控制精准,想要统计什么用户行为数据都可以获取到
劣势:埋点成本较大,需要 RD 才能完成;更新成本较高,需要随客户端发版才能生效;
可视化埋点
除了 RD 开发集成采集的 SDK 外,不需要额外的开发量,业务人员直接在可视化分析平台上,直接设置需要采集的行为,配置后自动采集用户行为数据;流程上是把核心代码、配置和资源做拆分,用过网络更新配置和资源从而实现采集代码下发;其原理参考了 VS 等一系列 IDE 的做法,用交互的手段代替代码编写,从而大幅缩减工作量和沟通成本,同时降低出错几率。
优势:很好的解决了代码埋点的人工成本和发版更新的代驾;有业务人员直接操作、无需开发支持
劣势:覆盖的功能有限,企业个性化 SDK 开发难度较高;
无埋点
无埋点也成为全埋点,就是 SDK 采集用户所有的行为数据,并全部上报,不要 RD 添加额外的代码;业务方通过后台管理对关注的行为数据进行圈选。
优势:全量采集数据,无需 RD 开发,减少沟通成本,支持先上报数据后埋点
劣势:全量采集数据,数据传输和服务器压力较大;企业个性化 SDK 开发难度大;
埋点框架
笔者认为埋点也是一门艺术,埋点的框架就是从大量埋点方案中抽象出来的规则或方法。本文以阿里的埋点框架 SPM 为例,定义 A,B,C,D,E 分别代表站点、页面、区块、具体位置、随机生成的字符串,通过组合的形式来确定唯一的用户行为。优势就是将埋点结构化,并且每个元素都可以独立管理及复用。以天猫首页部分页面为例,通过点击跳转可以区分此图内有 3 个模块。
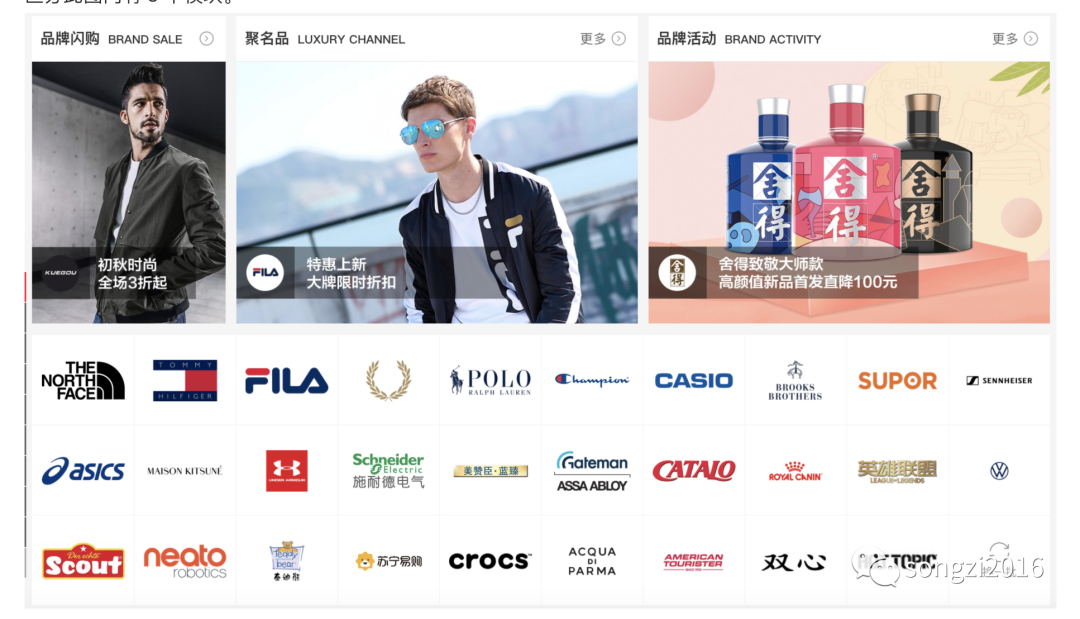
点击 fila 图标,可以看到链接中 spm 部分为 875.7931836/B.2016073.3.1c9c4265IitEmy,根据框架结构带入可以了结其信息和对应关系
https://fila.tmall.com/shop/view_shop.htm?spm=875.7931836/B.2016073.3.1c9c4265IitEmy&user_number_id=676606897&pvid=38336a1a-9b06-4951-a7d8-410faf8fe4dc&pos=3&brandId=3224828&acm=09042.1003.1.1200415&scm=1007.13029.131809.100200300000000复制代码
埋点规范
正所谓无规矩不成方圆,哪怕你有了一个合理的埋点框架,但是没有制定和遵守规范,随着埋点的不断迭代,数据处理的复杂度会随时间推移不断的增加。
在介绍规范之前,我们先了解一下埋点采集的日志数据类型和结构。
日志数据
通常对于埋点采集的数据我们成为日志数据,此部分主要介绍日志数据的事件和日志数据的结构。
以客户端采集的数据为例,按照用户行为的不同,我们定义为不同的事件(event),其中常见的基础事件包括不限于启动、页面访问、曝光、点击、性能,针对于不同产品会有一些特定的事件比如播放类产品需要定一个播放事件等。
日志的数据结构主要由公共参数和拓展参数构成。公共参数表示不同事件都可以具备和拥有的信息,例如用户 id 类(guid,user_id 等)、地域信息、设备、事件基础信息(事件类型、会话 id 等);拓展参数是不同事件特有的信息,比如页面访问时间的访问时长、播放事件的播放次数、用户启动事件的登录状态等,拓展参数大多以 json 形式存在,好处是数据仓的日志层可以减少字段拓展造成的改动,缺点是可能存在数据整理成本较高,尤其是 json 嵌套下。
下图为笔者参与的埋点方案设计。
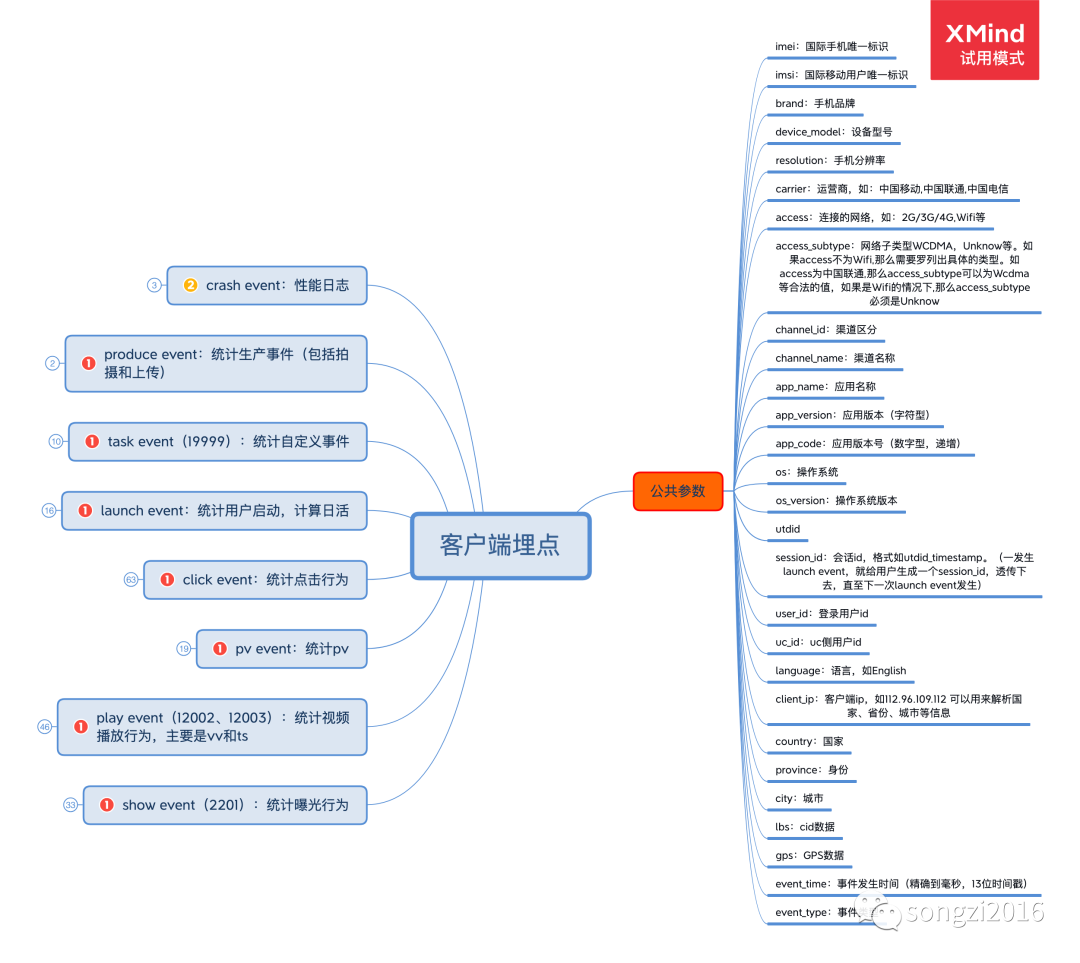
敲黑板,要注意客户端埋点和服务端埋点的区别,以及数据透传与记录。例如红包、折扣券、推荐内容由服务端记录及提供,客户端可以选择性记录用来分析及关联相应的明细信息。
规范
了解日志数据基础信息后,我们就要制定的相应的规范来确保埋点的准确和稳定性。
首先,如果采用的是结构化的埋点框架,对于站点、页面、区块的管理都是独立,统一管理减少唯一 id 代表的信息冗余;
其次,划分事件类型,对事件类型的定义进行统一,如:页面访问事件为 pv 或者 pageload;制定参数命名的规范,如点击 click,提交 submit;
再次,对于不同事件触发和上报的逻辑的规范,什么事件需要实时上报,什么事件可以延迟上报,特定行为的上报逻辑应该如何设计,比如:卡片的曝光,可以设计成卡片面积超过 60%,曝光时长超过 1 秒,这 样既可以保证用户看到大部分的内容,同时避免快速切换或者滑动页面造成的虚假曝光统计;
最后,我们需要制定统一标准的埋点文档。

如何做埋点?
上文介绍为了什么是埋点,埋点的分类、技术方案、框架和规范,那么从数据分析师的角色出发,如何去做埋点呢?官方话术:了解业务、产品设计方案及交互、明确分析的目标。
思路
做埋点的前提是遵循 4W1H 的思路:
WHO:谁?表征用来描述用户的 id 类信息;
WHEN:时间,会话创建的时间、事件发生时间、事件上报时间、视频播放时间、推荐资源请求时间等;
WHAT:描述事件内容,比如:播放事件,从什么入口进来,播放了什么内容,播放的时长是多久等;
WHERE:表示位置类信息,如城市、区域、GPS、IP 信息等;
HOW:路径及方式,从那个页面,那个模块跳转而来,在什么网络环境下;
流程
以分析师作为第一视角的埋点流程大致如下:
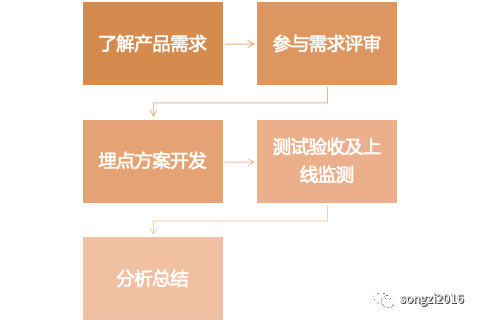
了解产品需求
对于每次产品迭代,作为分析师应该深入的去了解产品迭代的背景、面向的用户和业务逻辑, 数据的角度去思考如何通过数据证明,从而思考埋点如何设计。
此过程包含最初的产品需求对接,以及产品内部的需求评审,作为分析师应该参与其中了解更多的细节内容。对于过审的产品需求,产品应提供一下内容:产品文档、交互原型、数据指标需求,分析师设计具体的埋点方案及数据统计逻辑。
参与需求评审
产品埋点方案设计完整之后需要和开发进行评审,主要讨论功能或者埋点可实现性及开发周期相关工作。
埋点方案开发
过审后,分析师及产品会频繁的与开发进行沟通,跟踪埋点整体的进度以及解决开发过程中的问题。分析师可以在此过程中,优先构建指标数据统计看板,待测试或者正式上线后,可以同步看到数据,提升整体产出效率。
测试验收及上线监测
功能开发后,分析师主要检查埋点上传的日志数据的准确性(是否异常值、值错误、数据重复)、完整性(公共参数、自定义参数是否缺失,日志漏传等)。
埋点测试通过后,需要紧密监控发版后的数据,通常在此过程中会有一段时间的 AB-test,主要是监控埋点数据、统计指标是否异常,用户行为数据是否出现较大波动。
分析总结
测试和发版后数据没有明显异常的情况下,通常在之后的 1-2 周可以输出相关的产品功能迭代的分析报告,主要是同步覆盖率、使用率、留存活跃及迭代功能使用的相关数据。
写在最后
埋点是一项相对精细的工作,不仅仅是为了上报数据,其中事件的定义、行为的已定、日志结构、存储方式、前后端数据交互逻辑、数据提取的逻辑都需要考虑其中,需要从更高的全局角度去看待埋点。以免变成埋个点挖个坑,最后坑套坑,无穷尽。
本文阐述的内容仅作为个人工作的总结,如有疑问,欢迎与我讨论交流。感谢阅读~
