
趣闻|95%PyTorch库都会中招的bug!特斯拉AI总监都没能幸免

极市导读
最近Reddit上热议的一个话题,是一位网友发现,在PyTorch中用NumPy来生成随机数时,受到数据预处理的限制,会多进程并行加载数据,但最后每个进程返回的随机数却是相同的。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

而是它到底算不算一个bug?

这究竟是怎么一回事?

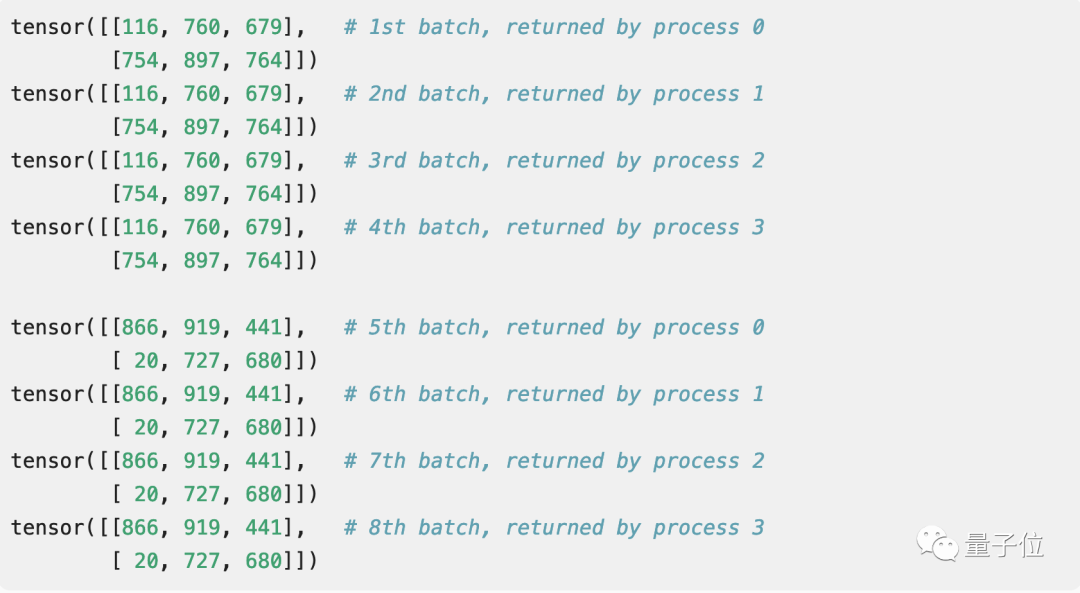
到底是不是bug?
虽然这个问题非常常见,但它并不算是一个bug,而是一个在调试时不可以忽略的点。

这不是产生伪随机数的问题,也不是numpy的问题,问题的核心是在于PyTorch中的DataLoader的实现

对于包含随机转换的数据加载pipeline,这意味着每个worker都将选择“相同”的转换。 而现在NN中的许多数据加载pipeline,都使用某种类型的随机转换来进行数据增强,所以不重新初始化可能是一个预设。
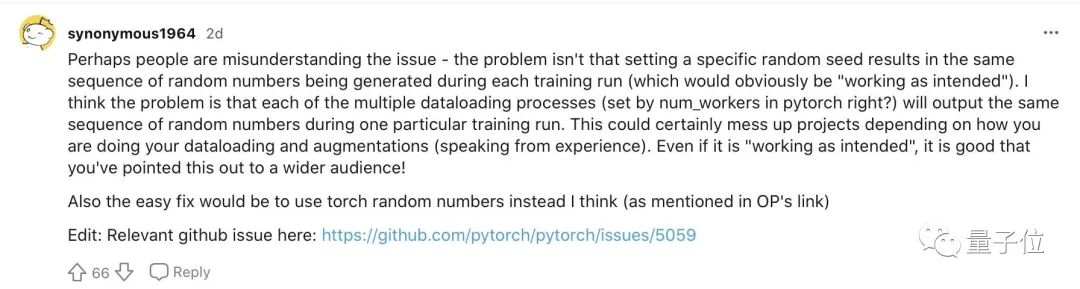
我认识到这一点是之前跑了许多进程来创建数据集时,然而发现其中一半的数据是重复的,之后花了很长的时间才发现哪里出了问题。


顺便一提,这提供了Karpathy定律的另一个例子:即使你搞砸了一些非常基本代码,“neural nets want to work”。
你有踩过PyTorch的坑吗?

[2]https://www.reddit.com/r/MachineLearning/comments/mocpgj/p_using_pytorch_numpy_a_bug_that_plagues/
[3]https://www.zhihu.com/question/67209417/answer/866488638
推荐阅读
2021-04-13

2021-04-11

2021-02-12


# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论