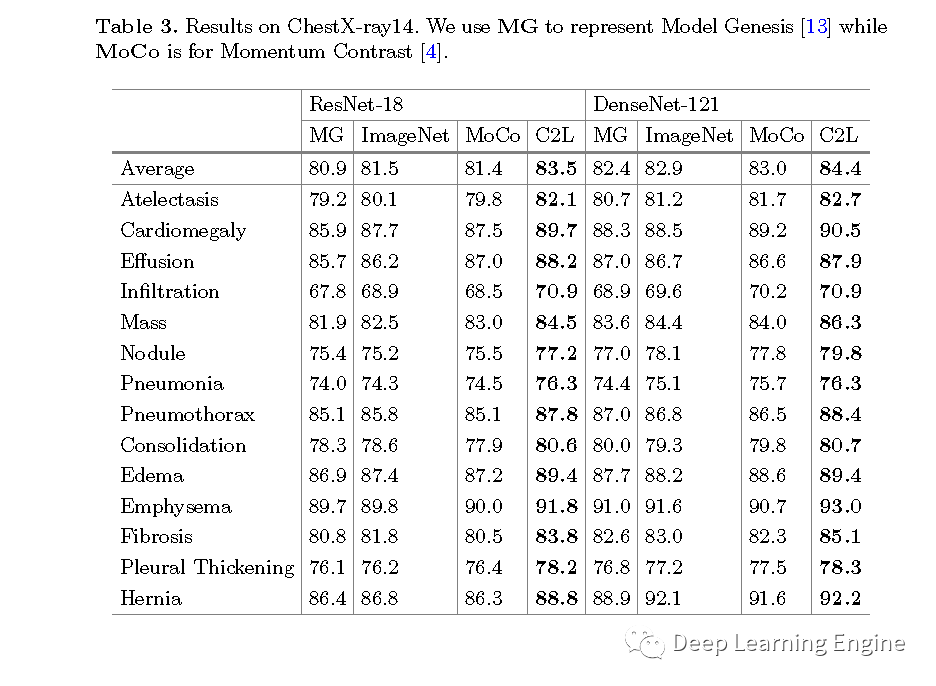
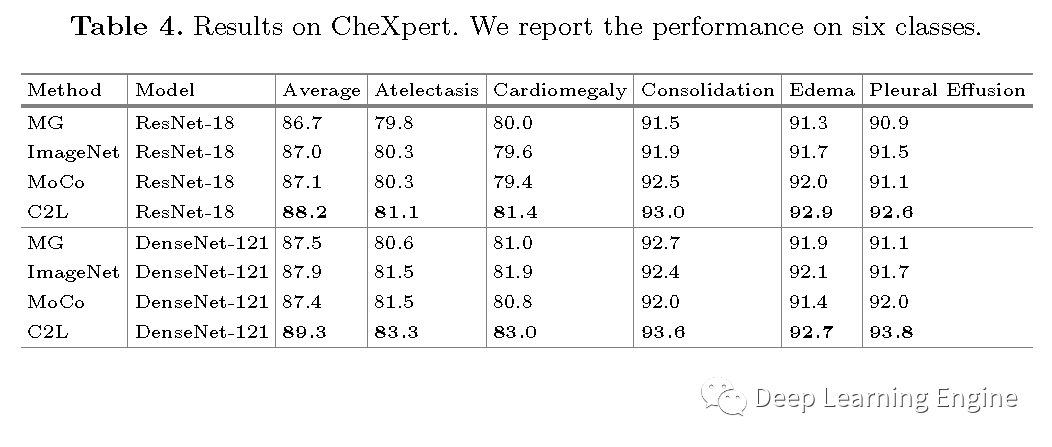
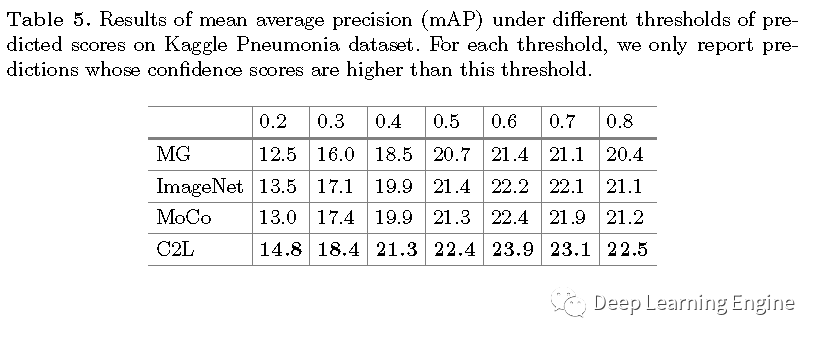
本期分享一篇MICCAI2020的一篇关于医学图像的预训练模型论文《Comparing to Learn: Surpassing ImageNet Pretraining on Radiographs by Comparing Image Representations》。在深度学习领域,预训练模型有着举足轻重的地位,特别是以自然场景数据为代表的ImageNet预训练模型是大多任务模型初始化参数的不二选择。对于医学图像来说,其和自然场景数据差异大。医学任务模型用ImageNet预训练模型就不太合适。因此,作者提出了一种新型的预训练方法(C2L),利用该方法在70万X光无标注数据上进行训练。利用预训练模型在不同的任务和数据集上均取得了优于ImageNet预训练模型更好的SOTA结果。
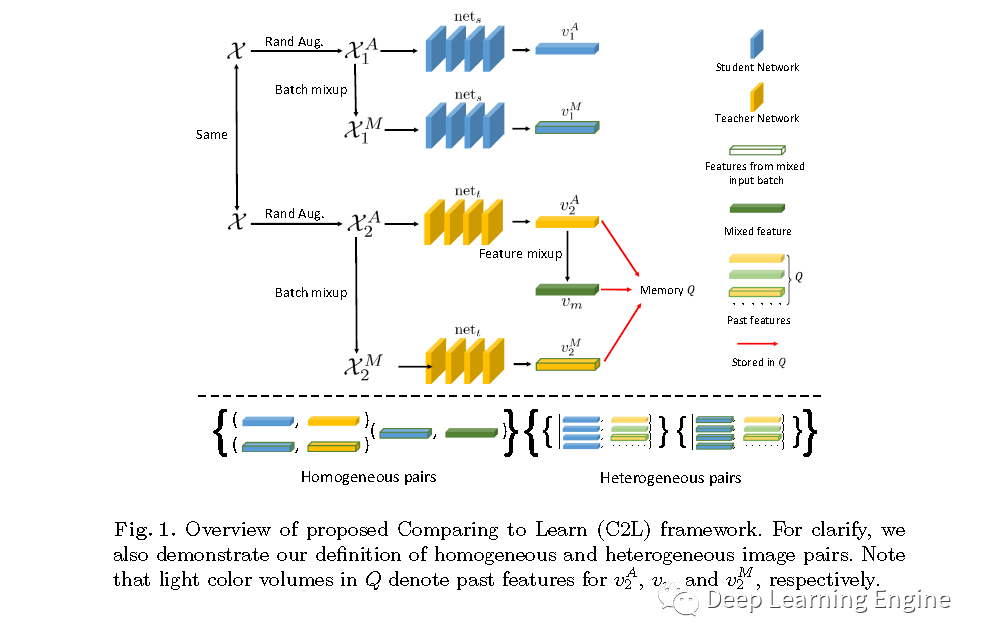
通过上述分析,作者提出了一种全新的自监督预训练方法C2L(Compare to Learn)。此方法旨在利用大量的未标注的X光图像预训练一个2D深度学习模型,使得模型能够在有监督信息的条件下,通过对比不同图像特征的差异,提取通用的图像表达。与利用图像修复等代理任务方法不同的是,作者提出的方法是一种自定义特征表达相似性度量。文中重点关注图像特征级别的对比,通过混合每个批次的图像和特征,提出了结构同质性和异质性的数据配对方法。设计了一种基于动量的“老师-学生”(teacher-student architecture)对比学习网络结构。“老师”网络和“学生”网络共享同一个网络结构,但是更新方式不同,其伪代码如下。
02 proposed Method
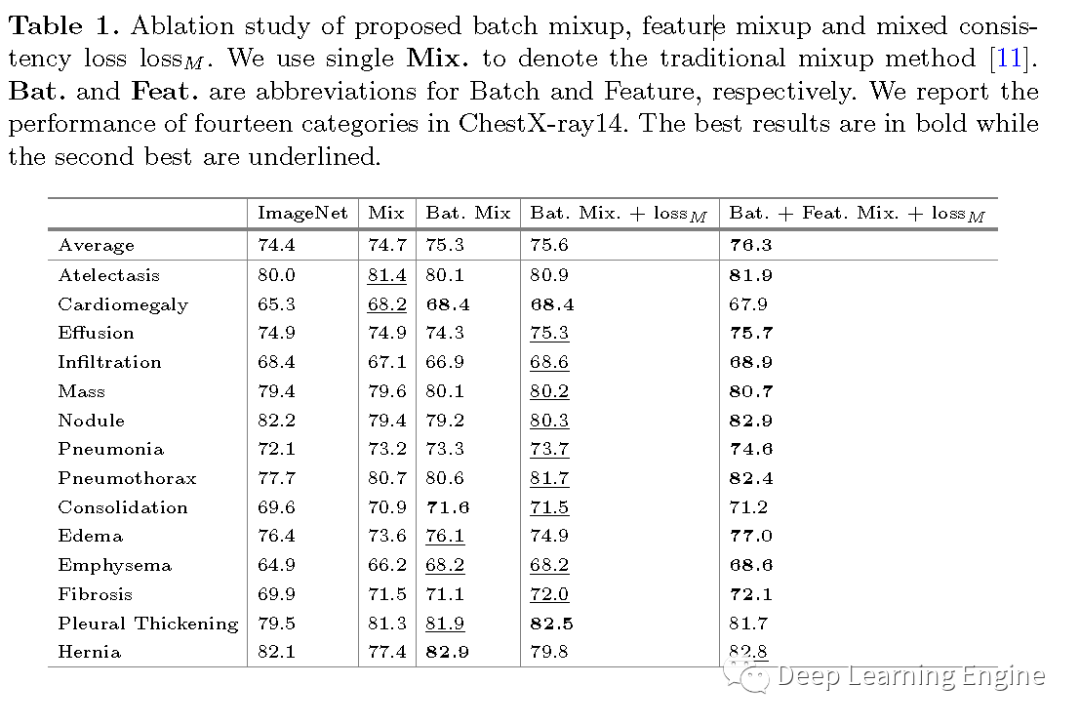
Batch Mixup and Feature Mixup:每一个批次的输入图像数据,首先进行随机数据增强(如随机裁剪,旋转等),生成两组数据。与传统的图像级混合方法不同,作者提出了一种基于批次级的混合方法。假设每个批次包含Z张图像,其中。随机打乱,构造配对数据。 其中,~ Beta(1.0,1.0)分布。通过实验发现,对两组数据使用相同的混合因子和数据打乱方法对模型的性能有提升效果。作者对特征的表达也使用了相同的数据混合策略。其中指数因子控制着动量的程度。如伪代码及流程图所示,"教师"网络同时利用自身和"学生"网络进行更新。而在实际中,作者输入和到"学生"模型,输入和到"教师"模型。分别使用和表示"学生"网络和"老师"网络的输出特征向量。Homogeneous and Heterogeneous Pairs:为了构造同质数据对,作者假设数据增强(包括文中用到的mixing operation混合操作)只会略微改变训练数据的分布。那么每个同质性配对的数据包含的是经过一些列同样的数据增强,批次数据混合以及特征混合的数据。对于同质数据对,只需要将当前特征和所有的已经存储的队列中特征进行对比。
Feature Comparison, Memory Q and Loss Function:如伪代码如所示,C2L模型优化最小化同质数据对之间的距离,最大化异质数据之间的距离。